 1024块TPU在燃烧!将BERT预训练模型的训练时长从3天缩减到了76分钟
1024块TPU在燃烧!将BERT预训练模型的训练时长从3天缩减到了76分钟

“Jeff Dean称赞,TensorFlow官方推特支持,BERT目前工业界最耗时的应用,计算量远高于ImageNet。我们将BERT的训练时间从三天缩短到了一小时多。”UC Berkeley大学在读博士尤洋如是说道。
近日,来自Google、UC Berkeley、UCLA研究团队再度合作,成功燃烧1024块TPU,将BERT预训练模型的训练时长从3天缩减到了76分钟。batch size技术是加速神经网络训练的关键,在“Reducing BERT Pre-Training Time from 3 Days to 76 Minutes”这篇论文中,作者提出了LAMB优化器,它支持自适应元素更新和分层校正。
论文传送门:https://arxiv.org/pdf/1904.00962.pdf
论文摘要:batch size增加到很大时的模型训练是加速大型分布式系统中深度神经网络训练的关键。但是,这种模型训练很难,因为它会导致一种泛化差距。直接优化通常会导致测试集上的准确性下降。
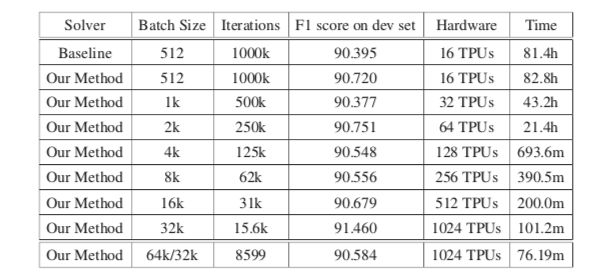
BERT是一种先进的深度学习模型,它建立在语义理解的深度双向转换器上。当我们增加batch size的大小(如超过8192)时,此前的模型训练技巧在BERT上表现得并不好。BERT预训练也需要很长时间才能完成,如在16个TPUv3上大约需要三天。
为了解决这个问题,我们提出了LAMB优化器,可将batch size扩展到65536,且不会降低准确率。LAMB是一个通用优化器,batch size大小均使用,且除了学习率之外不需要别的参数调整。
基线BERT-Large模型需要100万次迭代才能完成预训练,而batch size大小为65536/32768的LAMB仅需要8599次迭代。我们还将batch size进行内存限制,接近TPUv3 pod,结果可在76分钟内完成BERT训练。
据悉,该论文的一作是来自UC Berkeley计算机科学部的在读博士尤洋,同时也是Google Brain的实习生。据公开信息显示,尤洋的导师是美国科学院与工程院院士,ACM/IEEE fellow,伯克利计算机系主任,以及首批中关村海外顾问James Demmel教授。他当前的研究重点是大规模深度学习训练算法的分布式优化。2017年9月,尤洋等人的新算法以24分钟完成ImageNet训练,刷新世界纪录。
在此之前,他曾在英特尔实验室、微软研究院、英伟达、IBM沃森研究中心等机构实习。尤洋本科就读于中国农业大学计算机系,硕士保送清华大学计算机系,是一名杠杠的理工学霸!
-
神经网络
+关注
关注
42文章
4845浏览量
108326 -
TPU
+关注
关注
0文章
174浏览量
21731 -
深度学习
+关注
关注
73文章
5613浏览量
124723 -
训练模型
+关注
关注
1文章
37浏览量
4090
原文标题:1024块TPU在燃烧!BERT训练从3天缩短到76分钟 | 技术头条
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
谷歌发布第八代TPU,训练推理分离,搭载自研CPU

百度发布文心5.1:预训练成本降至行业6%
零基础手写大模型资料2026
AI Ceph 分布式存储教程资料大模型学习资料2026
HM博学谷狂野AI大模型第四期
Edge Impulse 唤醒词模型训练 | 技术集结

AI模型训练与部署实战 | 线下免费培训


AI硬件全景解析:CPU、GPU、NPU、TPU的差异化之路,一文看懂!

RA8P1部署ai模型指南:从训练模型到部署 | 本周六

在Ubuntu20.04系统中训练神经网络模型的一些经验
基于大规模人类操作数据预训练的VLA模型H-RDT




评论