 为大家介绍三个NLP领域的热门词汇
为大家介绍三个NLP领域的热门词汇
编者按:在过去的一段时间,自然语言处理领域取得了许多重要的进展,Transformer、BERT、无监督机器翻译,这些词汇仿佛在一夜之间就进入了人们的视野。你知道它们具体都是什么意思吗?今天,我们就将为大家介绍三个NLP领域的热门词汇。
Transformer
Transformer在2017年由Google在题为《Attention Is All You Need》的论文中提出。Transformer是一个完全基于注意力机制的编解码器模型,它抛弃了之前其它模型引入注意力机制后仍然保留的循环与卷积结构,而采用了自注意力(Self-attention)机制,在任务表现、并行能力和易于训练性方面都有大幅的提高。
在 Transformer 出现之前,基于神经网络的机器翻译模型多数都采用了 RNN的模型架构,它们依靠循环功能进行有序的序列操作。虽然 RNN 架构有较强的序列建模能力,但是存在训练速度慢,训练质量低等问题。
与基于 RNN 的方法不同,Transformer 模型中没有循环结构,而是把序列中的所有单词或者符号并行处理,同时借助自注意力机制对句子中所有单词之间的关系直接进行建模,而无需考虑各自的位置。具体而言,如果要计算给定单词的下一个表征,Transformer 会将该单词与句子中的其它单词一一对比,并得出这些单词的注意力分数。注意力分数决定其它单词对给定词汇的语义影响。之后,注意力分数用作所有单词表征的平均权重,这些表征输入全连接网络,生成新表征。
由于 Transformer 并行处理所有的词,以及每个单词都可以在多个处理步骤内与其它单词之间产生联系,它的训练速度比 RNN 模型更快,在翻译任务中的表现也比 RNN 模型更好。除了计算性能和更高的准确度,Transformer 另一个亮点是可以对网络关注的句子部分进行可视化,尤其是在处理或翻译一个给定词时,因此可以深入了解信息是如何通过网络传播的。
之后,Google的研究人员们又对标准的 Transformer 模型进行了拓展,采用了一种新型的、注重效率的时间并行循环结构,让它具有通用计算能力,并在更多任务中取得了更好的结果。
改进的模型(Universal Transformer)在保留Transformer 模型原有并行结构的基础上,把 Transformer 一组几个各异的固定的变换函数替换成了一组由单个的、时间并行的循环变换函数构成的结构。相比于 RNN一个符号接着一个符号从左至右依次处理序列,Universal Transformer 和 Transformer 能够一次同时处理所有的符号,但 Universal Transformer 接下来会根据自注意力机制对每个符号的解释做数次并行的循环处理修饰。Universal Transformer 中时间并行的循环机制不仅比 RNN 中使用的串行循环速度更快,也让 Universal Transformer 比标准的前馈 Transformer 更加强大。
预训练Pre-train
目前神经网络在进行训练的时候基本都是基于后向传播(Back Propagation,BP)算法,通过对网络模型参数进行随机初始化,然后利用优化算法优化模型参数。但是在标注数据很少的情况下,通过神经网络训练出的模型往往精度有限,“预训练”则能够很好地解决这个问题,并且对一词多义进行建模。
预训练是通过大量无标注的语言文本进行语言模型的训练,得到一套模型参数,利用这套参数对模型进行初始化,再根据具体任务在现有语言模型的基础上进行精调。预训练的方法在自然语言处理的分类和标记任务中,都被证明拥有更好的效果。目前,热门的预训练方法主要有三个:ELMo,OpenAI GPT和BERT。
在2018年初,艾伦人工智能研究所和华盛顿大学的研究人员在题为《Deep contextualized word representations》一文中提出了ELMo。相较于传统的使用词嵌入(Word embedding)对词语进行表示,得到每个词唯一固定的词向量,ELMo 利用预训练好的双向语言模型,根据具体输入从该语言模型中可以得到在文本中该词语的表示。在进行有监督的 NLP 任务时,可以将 ELMo 直接当做特征拼接到具体任务模型的词向量输入或者是模型的最高层表示上。
在ELMo的基础之上,OpenAI的研究人员在《Improving Language Understanding by Generative Pre-Training》提出了OpenAI GPT。与ELMo为每一个词语提供一个显式的词向量不同,OpenAI GPT能够学习一个通用的表示,使其能够在大量任务上进行应用。在处理具体任务时,OpenAI GPT 不需要再重新对任务构建新的模型结构,而是直接在 Transformer 这个语言模型上的最后一层接上 softmax 作为任务输出层,再对这整个模型进行微调。
ELMo和OpenAI GPT这两种预训练语言表示方法都是使用单向的语言模型来学习语言表示,而Google在提出的BERT则实现了双向学习,并得到了更好的训练效果。具体而言,BERT使用Transformer的编码器作为语言模型,并在语言模型训练时提出了两个新的目标:MLM(Masked Language Model)和句子预测。MLM是指在输入的词序列中,随机的挡上 15% 的词,并遮挡部分的词语进行双向预测。为了让模型能够学习到句子间关系,研究人员提出了让模型对即将出现的句子进行预测:对连续句子的正误进行二元分类,再对其取和求似然。
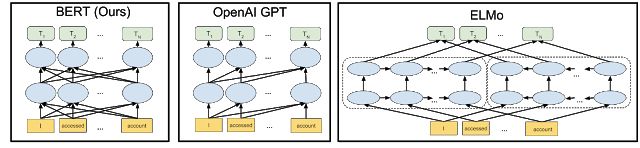
图片来源:Google AI Blog
无监督机器翻译
Unsupervised Machine Translation
现有的机器翻译需要大量的翻译文本做训练样本,这使得机器翻译只在一小部分样本数量充足的语言上表现良好,但如何在没有源翻译的情况下训练机器翻译模型,即无监督训练,成为了目前热门的研究话题。Facebook在EMNLP 2018上的论文《Phrase-Based & Neural Unsupervised Machine Translation》利用跨字嵌入(Cross Word Embedding),提升了高达11 BLEU,那么Facebook是如何实现的呢?
第一步是让系统学习双语词典。系统首先为每种语言中的每个单词训练词嵌入,训练词嵌入通过上下文来预测给定单词周围的单词。不同语言的词嵌入具有相似的邻域结构,因此可以通过对抗训练等方法让系统学习旋转变换一种语言的词嵌入,以匹配另一种语言的词嵌入。基于这些信息,就可以得到一个相对准确的双语词典,并基本可以实现逐字翻译。在得到语言模型和初始的逐字翻译模型之后,就可以构建翻译系统的早期版本。
然后将系统翻译出的语句作为标注过的真实数据进行处理,训练反向机器翻译系统,得到一个更加流畅和语法正确的语言模型,并将反向翻译中人工生成的平行句子与该语言模型提供的校正相结合,以此来训练这个翻译系统。
通过对系统的训练,形成了反向翻译的数据集,从而改进原有的机器翻译系统。随着一个系统得到改进,可以使用它以迭代方式在相反方向上为系统生成训练数据,并根据需要进行多次迭代。
逐字嵌入初始化、语言建模和反向翻译是无监督机器翻译的三个重要原则。将基于这些原理得到的翻译系统应用于无监督的神经模型和基于计数的统计模型,从训练好的神经模型开始,使用基于短语模型的其它反向翻译句子对其进行训练,最终得到了一个既流畅,准确率又高的模型。
对于无监督机器翻译,微软亚洲研究院自然语言计算组也进行了探索。研究人员利用后验正则(Posterior Regularization)的方式将SMT(统计机器翻译)引入到无监督NMT的训练过程中,并通过EM过程交替优化SMT和NMT模型,使得无监督NMT迭代过程中的噪音能够被有效去除,同时NMT模型也弥补了SMT模型在句子流畅性方面的不足。相关论文《Unsupervised Neural Machine Translation with SMT as Posterior Regularization》已被AAAI 2019接收。
感谢微软亚洲研究院自然语言计算组研究员葛涛对本文提供的帮助。
-
神经网络
+关注
关注
42文章
4772浏览量
100855 -
机器翻译
+关注
关注
0文章
139浏览量
14903 -
nlp
+关注
关注
1文章
489浏览量
22052
原文标题:请收下这份NLP热门词汇解读
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
MOS管的三个二级效应
探索并行领域—并行设计行业的三个实例介绍
NLP的介绍和如何利用机器学习进行NLP以及三种NLP技术的详细介绍

最先进的NLP模型很脆弱!最先进的NLP模型是虚假的!
Richard Socher:NLP领域的发展要过三座大山
随着人工智能的发展 即将出现这三个热门职业
介绍三个NLP领域的热门词汇
华为三个全新商标对应不同领域
NLP 2019 Highlights 给NLP从业者的一个参考
词汇知识融合可能是NLP任务的永恒话题





 工商网监
工商网监
评论