 何恺明等人再出重磅新作:分割任务的TensorMask框架
何恺明等人再出重磅新作:分割任务的TensorMask框架

看到今天要给大家介绍的论文,也许现在大家已经非常熟悉 Ross Girshic、Piotr Dollár 还有我们的大神何恺明的三人组了。没错,今天这篇重磅新作还是他们的产出,营长感觉刚介绍他们的新作好像没多久啊!想要追赶大神脚步,确实是不能懈怠啊!
不过这次一作是来自 FAIR 的陈鑫磊博士,虽然和三人组合比起来,一作陈鑫磊还没有那么被大家所熟知,不过其实力也是不容小觑的(毕竟后面跟着三个实力响当当的人物)。营长在陈鑫磊的个人主页上看到他的学习经历和研究成果,也是忍不住点赞。陈鑫磊在浙江大学国家重点实验室 CAD&CG实验室学习时,师从蔡登教授,随后在 CMU 攻读博士学位,现任职于 FAIR,毕业前曾在 Google Cloud 李飞飞和李佳组内实习。在博士研究期间,每年和导师 Abhinav Gupta 教授都有论文发表在 AAAI、CVPR、ECCV、ICCV 等顶会上,考虑篇幅,营长就从每年成果中选一篇列举出来,大家可以前往陈鑫磊的个人主页中可以看到全部作品。
2013-2018 年间的主要作品:
[1]、Xinlei Chen, Li-Jia Li, Li Fei-Fei, Abhinav Gupta.Iterative Visual Reasoning Beyond Convolutions. The 31st IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2018.Spotlight
[2]、Xinlei Chen, Abhinav Gupta.Spatial Memory for Context Reasoning in Object Detection. The 15th International Conference on Computer Vision(ICCV), 2017
[3]、Gunnar A. Sigurdsson,Xinlei Chen, Abhinav Gupta.Learning Visual Storylines with Skipping Recurrent Neural Networks. The 14th European Conference on Computer Vision(ECCV), 2016
[4]、Xinlei Chen, Abhinav Gupta.Webly Supervised Learning of Convolutional Networks. The 15th International Conference on Computer Vision(ICCV), 2015.Oral
[5]、Xinlei Chen, C. Lawrence Zitnick.Mind's Eye: A Recurrent Visual Representation for Image Caption Generation. The 28th IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2015
[6]、Xinlei Chen, Alan Ritter, Abhinav Gupta, Tom Mitchell.Sense Discovery via Co-Clustering on Images and Text. The 28th IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2015.
[7]、Xinlei Chen, Abhinav Shrivastava, Abhinav Gupta.Enriching Visual Knowledge Bases via Object Discovery and Segmentation. The 27th IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2014
[8]、Xinlei Chen, Abhinav Shrivastava, Abhinav Gupta.NEIL: Extracting Visual Knowledge from Web Data. The 14th International Conference on Computer Vision(ICCV), 2013.Oral.
这几个人从出道至今,都有非常多的佳作,出产率也非常高,最近大家还在重谈去年三人组合的论文《Rethinking ImageNet Pre-training》,今天就有了这篇在密集掩码预测新突破:《TensorMask: A Foundation for Dense Object Segmentation》,大神们简直就是快要承包整个 CV 界了!
“CV男团”四人的个人主页(一到四作的顺序):
http://xinleic.xyz/#
http://www.rossgirshick.info/
http://kaiminghe.com/
http://pdollar.github.io/
接下来,营长就为大家带来“CV男团”这篇最新力作的初解读,因为论文中涉及很多与 TensorMask 框架相关的专业术语,函数定义等,还需要大家下来细细研究,感兴趣的同学可以从下面的论文地址里下载论文进一步学习,也欢迎大家在后台给我们留言,发表你的感想。
论文解读
摘要
在目标检测任务中,采用滑窗方式生成目标的检测框是一种非常常用的方法。而在实例分割任务中,比较主流的图像分割方法是首先检测目标边界框,然后进行裁剪和目标分割,如 Mask RCNN。在这篇工作中,我们研究了密集滑窗实例分割(dense sliding-window instance segmentation)的模式,发现与其他的密集预测任务如语义分割,目标检测不同,实例分割滑窗在每个空间位置的输出具有自己空间维度的几何结构。为了形式化这一点,我们提出了一个通用的框架 TensorMask 来获得这种几何结构。
我们通过张量视图展示了相较于忽略这种结构的 baseline 方法,它可以有一个大的效果提升,甚至比肩于 Mask R-CNN。这样的实验结果足以说明TensorMask 为密集掩码预测任务提供了一个新的理解方向,并可以作为该领域新的基础方法。
引言
滑窗范式(在一张图的每个滑动窗口里面去寻找目标)是视觉任务里面最早且非常成功的方法,并且可以很自然的和卷积网络联系起来。虽然像 RCNN 系列方法需要在滑窗的方法上再进行精修,但是像 SSD、RetinaNet 的方法就是直接利用滑窗预测。在目标检测里面非常受欢迎的方法,在实例分割任务中却没得到足够的关注。因此本文的工作就是来填补该缺失。本文主要的 insight 就是定义密集掩码的表示方式,并且在神经网络中有效的实现它。与低维、尺度无关的检测框不同,分割掩码需要一种更具有结构化的表示方式。因此,本文在空域上,采用结构化的 4 维张量定义了掩码的表示方式,并提出了一个基于滑窗方法的密集实例分割框架——TensorMask。在 4 维张量(V,U,H,W)中,H 和 W 表示目标的位置,而 V 和 U 表示相关掩码的位置。与仅直接在通道上加一个掩码分支的方法不同,这种方法是具有几何意义的,并且可以直接在(V,U)张量上进行坐标转换,尺度缩放等操作。在 TensorMask 框架中,作者还顺手开发了一个张量尺度金字塔(tensor bipyramid),用于 4 维的尺度缩放。如下公式所示,其中 K 就是尺度。
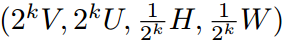
掩码的张量表示
TensorMask 框架的主要想法就是利用结构化的高维张量去表示密集的滑动窗口。在理解这样的一个框架时,需要了解几个重要的概念。
单位长度(Unit of Length):在不同的轴和尺度上有不同的单位长度,且 HW 和 VU 的单位长度可以不相等。
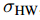 和
和 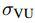 分别表示其单位长度。
分别表示其单位长度。
自然表示(Natural Representation):在点(y,x)处的滑窗内,某点的掩码值表示,如下截图所示,其中 alpha 表示 VU 和 HW 的单位长度比率。

对齐表示(Aligned Representation):由于单位长度中 stride 的存在,自然表示存在着像素偏移的问题,因此这里有一个同 ROIAlign 相似的想法,需要从张量的角度定义一个像素级的表示。

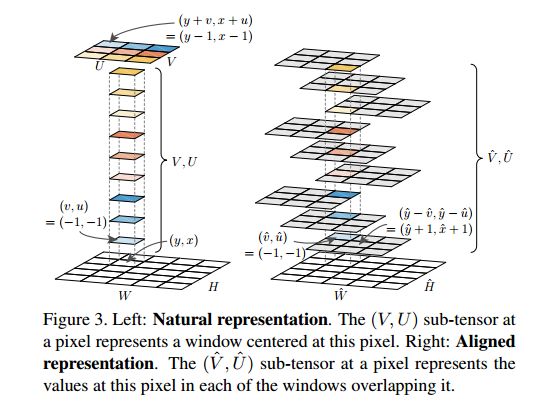
坐标转换:用于自然表示和对齐表示间的转换,论文给出了两种情况下的转换公式,一种是简化版的( 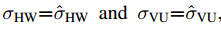 ),一种是一般版的(就是任意的单位长度)。
),一种是一般版的(就是任意的单位长度)。
上采样转换(Upscaling Transformation):下图就是上采样转换的操作集合。实验证明它可以在不增加通道数的情况下,有效的生成高分辨率的掩码。
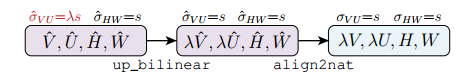
张量尺度金字塔(Tensor Bipyramid):由于掩码存在尺度问题,它需要随目标的大小而进行缩放,为了保持恒定的分辨率密度,提出了这种基于尺度来调整掩码像素数量的方法。
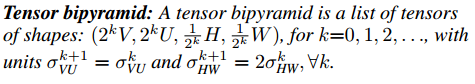
TensorMask结构
基于 TensorMask 表示的模型,有一个采用滑窗的掩码预测分支和一个类似于检测框回归的分类分支。该结构不需要增加检测框的分支。掩码预测分支可以采用卷积的 backbone,比如 ResNet50。因此,论文提出了多个基础(baseline)分支和张量尺度金字塔分支,帮助使用者快速上手 TensorMask。需要指出的是,张量尺度金字塔分支是最有效的一个模型。在训练时,作者采用 DeepMask 来帮助标记数据,以及 focal loss 等等。
实验
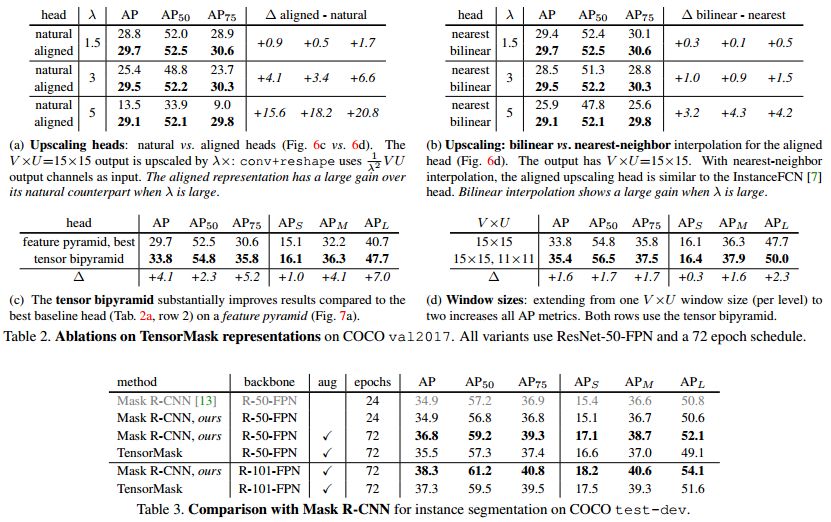
为了说明各分支或者操作的作用,论文做了大量的消融实验来进行论证。具体结果见下图表格的数据以及与 Mask-RCNN 可视化的对比。实验结果证明,TensorMask 能够定性定量的比肩 MaskR-CNN。

该项工作将滑窗方法与实例分割任务直接联系了起来,能够帮助该领域的研究者对实例分割有新的理解,期待代码早日开源。
-
神经网络
+关注
关注
42文章
4845浏览量
108341 -
框架
+关注
关注
0文章
404浏览量
18521 -
开源
+关注
关注
3文章
4415浏览量
46566
原文标题:何恺明等人提TensorMask框架:比肩Mask R-CNN,4D张量预测新突破
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
瑞芯微(EASY EAI)RV1126B resnet50训练部署教程

RT-Thread任务+消息订阅管理框架软件包:thread_manager+event_loop

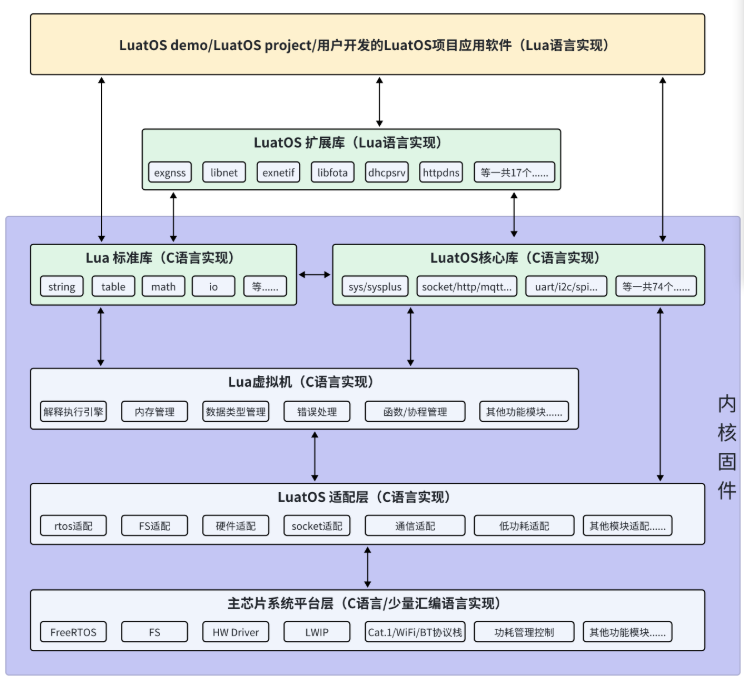
LuatOS 系统框架的模块化设计原理

LuatOS框架的使用(上)
32亿收购!晶丰明源有何布局?
手机板 layout 走线跨分割问题
基于瑞芯微RK3576的resnet50训练部署教程

Task任务:LuatOS实现“任务级并发”的核心引擎

揭秘LuatOS Task:多任务管理的“智能中枢”
洲明科技与华辉煌签订100万台AI智能硬件供货框架协议
洲明科技与香港科晫集团签署战略合作协议
洲明科技2025上半年高光时刻回顾
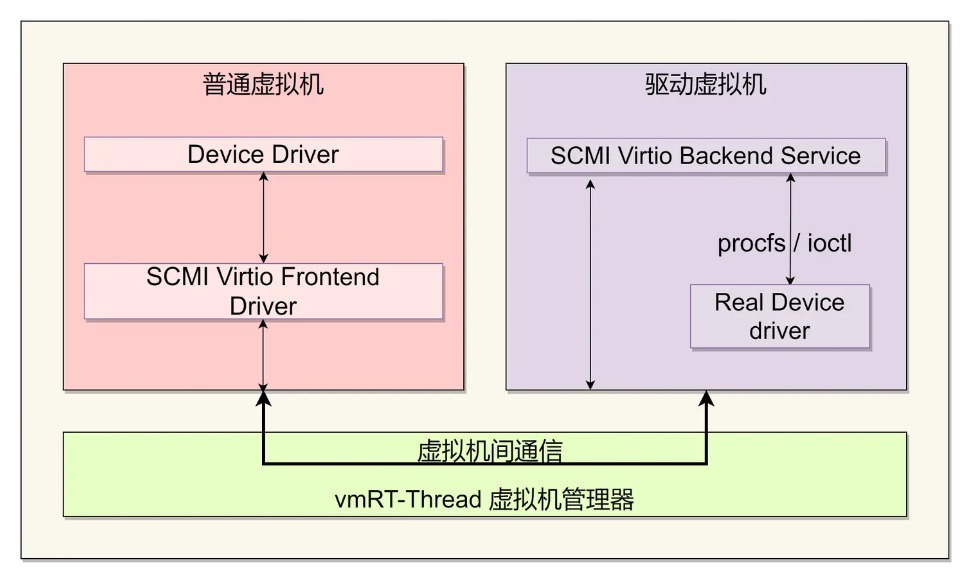
通过vmRT-Thread和VirtIO-SCMI攻克硬件分割依赖难点 | 前沿观点
【正点原子STM32MP257开发板试用】基于 DeepLab 模型的图像分割
第三届大会回顾第3期 | FFRT并发框架在OpenHarmony中的设计与实践




评论