 完成一个简单的端到端的机器学习模型需要几步?
完成一个简单的端到端的机器学习模型需要几步?
【导语】完成一个简单的端到端的机器学习模型需要几步?在本文中,我们将从一个完整的工作流:下载数据→图像分割与处理→建模→发布模型,教大家如何对 900 万张图像进行分类,分类标签多达 600 个。可是如此庞大的数据集又是从何而来呢?上周,AI科技大本营为大家介绍过一篇文章在过去十年间,涵盖 CV、NLP 和语音等领域,有 68 款大规模数据集,本文所用的数据集也在其中,大家也可以以此为借鉴,学习如何利用好这些数据。
前言
如果您想构建一个图像分类器,哪里可以得到训练数据呢?这里给大家推荐 Google Open Images,这个巨大的图像库包含超过 3000 万张图像和 1500 万个边框,高达 18tb 的图像数据!并且,它比同级别的其他图像库更加开放,像 ImageNet 就有权限要求。
但是,对单机开发人员来说,在这么多的图像数据中筛选过滤并不是一件易事,需要下载和处理多个元数据文件,还要回滚自己的存储空间,也可以申请使用谷歌云服务。另一方面,实际中并没有那么多定制的图像训练集,实话讲,创建、共享这么多的训练数据是一件头疼的事情。
在今天的教程中,我们将教大家如何使用这些开源图像创建一个简单的端到端机器学习模型。
先来看看如何使用开源图像中自带的 600 类标签来创建自己的数据集。下面以类别为“三明治”的照片为例,展示整个处理过程。
谷歌开源图像-三明治图片
一、下载数据
首先需要下载相关数据,然后才能使用。这是使用谷歌开源图像(或其他外部数据集)的第一步。而下载数据集需要编写相关脚本,没有其他简单的方法,不过不用担心,我写了一个Python脚本,大家可以直接用。思路:首先根据指定的关键字,在开源数据集中搜索元数据,找到对应图像的原始 url(在 Flickr 上),然后下载到本地,下面是实现的 Python 代码:
1importsys 2importos 3importpandasaspd 4importrequests 5 6fromtqdmimporttqdm 7importratelim 8fromcheckpointsimportcheckpoints 9checkpoints.enable()101112defdownload(categories):13#Downloadthemetadata14kwargs={'header':None,'names':['LabelID','LabelName']}15orig_url="https://storage.googleapis.com/openimages/2018_04/class-descriptions-boxable.csv"16class_names=pd.read_csv(orig_url,**kwargs)17orig_url="https://storage.googleapis.com/openimages/2018_04/train/train-annotations-bbox.csv"18train_boxed=pd.read_csv(orig_url)19orig_url="https://storage.googleapis.com/openimages/2018_04/train/train-images-boxable-with-rotation.csv"20image_ids=pd.read_csv(orig_url)2122#GetcategoryIDsforthegivencategoriesandsub-selecttrain_boxedwiththem.23label_map=dict(class_names.set_index('LabelName').loc[categories,'LabelID']24.to_frame().reset_index().set_index('LabelID')['LabelName'])25label_values=set(label_map.keys())26relevant_training_images=train_boxed[train_boxed.LabelName.isin(label_values)]2728#Startfrompriorresultsiftheyexistandarespecified,otherwisestartfromscratch.29relevant_flickr_urls=(relevant_training_images.set_index('ImageID')30.join(image_ids.set_index('ImageID'))31.loc[:,'OriginalURL'])32relevant_flickr_img_metadata=(relevant_training_images.set_index('ImageID').loc[relevant_flickr_urls.index]33.pipe(lambdadf:df.assign(LabelValue=df.LabelName.map(lambdav:label_map[v]))))34remaining_todo=len(relevant_flickr_urls)ifcheckpoints.resultsisNoneelse35len(relevant_flickr_urls)-len(checkpoints.results)3637#Downloadtheimages38withtqdm(total=remaining_todo)asprogress_bar:39relevant_image_requests=relevant_flickr_urls.safe_map(lambdaurl:_download_image(url,progress_bar))40progress_bar.close()4142#Writetheimagestofiles,addingthemtothepackageaswegoalong.43ifnotos.path.isdir("temp/"):44os.mkdir("temp/")45for((_,r),(_,url),(_,meta))inzip(relevant_image_requests.iteritems(),relevant_flickr_urls.iteritems(),46relevant_flickr_img_metadata.iterrows()):47image_name=url.split("/")[-1]48image_label=meta['LabelValue']4950_write_image_file(r,image_name)515253@ratelim.patient(5,5)54def_download_image(url,pbar):55"""DownloadasingleimagefromaURL,rate-limitedtooncepersecond"""56r=requests.get(url)57r.raise_for_status()58pbar.update(1)59returnr606162def_write_image_file(r,image_name):63"""Writeanimagetoafile"""64filename=f"temp/{image_name}"65withopen(filename,"wb")asf:66f.write(r.content)676869if__name__=='__main__':70categories=sys.argv[1:]71download(categories)
该脚本可以下载原始图像的子集,其中包含我们选择的类别的边框信息:
1$gitclonehttps://github.com/quiltdata/open-images.git2$cdopen-images/3$condaenvcreate-fenvironment.yml4$sourceactivatequilt-open-images-dev5$cdsrc/openimager/6$pythonopenimager.py"Sandwiches""Hamburgers"
图像类别采用多级分层的方式。例如,类别三明治和汉堡包还都属于食物类标签。我们可以使用 Vega 将其可视化为径向树:

并不是开源图像中的所有类别都有与之关联的边框数据。但这个脚本可以下载 600 类标签中的任意子集,本文主要通过”汉堡包“和”三明治“两个类别展开讨论。
football,toy,bird,cat,vase,hairdryer,kangaroo,knife,briefcase,pencilcase,tennisball,nail,highheels,sushi,skyscraper,tree,truck,violin,wine,wheel,whale,pizzacutter,bread,helicopter,lemon,dog,elephant,shark,flower,furniture,airplane,spoon,bench,swan,peanut,camera,flute,helmet,pomegranate,crown…
二、图像分割和处理
我们在本地处理图像时,可以使用 matplotlib 显示这些图片:
1importmatplotlib.pyplotasplt2frommatplotlib.imageimportimread3%matplotlibinline4importos5fig,axarr=plt.subplots(1,5,figsize=(24,4))6fori,imginenumerate(os.listdir('../data/images/')[:5]):7axarr[i].imshow(imread('../data/images/'+img))
可见这些图像并不容易训练,也存在其他网站的源数据集所面临的所有问题。比如目标类中可能存在不同大小、不同方向和遮挡等问题。有一次,我们甚至没有成功下载到实际的图像,只是得到一个占位符——我们想要的图像已经被删除了!
我们下载得到了几千张这样的图片之后就要利用边界框信息将这些图像分割成三明治,汉堡。下面给出一组包含边框的图像:
带边界框
此处省略了这部分代码,它有点复杂。下面要做的就是重构图像元数据,剪裁分割图像;再提取匹配的图像。在运行上述代码之后,本地会生成一个 images_cropped 文件夹,其中包含所有分割后的图像。
三、建模
完成了下载数据,图像分割和处理,就可以训练模型了。接下来,我们对数据进行卷积神经网络(CNN)训练。卷积神经网络利用图像中的像素点逐步构建出更高层次的特征。然后对图像的这些不同特征进行得分和加权,最终生成分类结果。这种分类的方式很好的利用了局部特征。因为任何一个像素与附近像素的特征相似度几乎都远远大于远处像素的相似度。
CNNs 还具有其他吸引之处,如噪声容忍度和(一定程度上的)尺度不变性。这进一步提高了算法的分类性能。
接下来就要开始训练一个非常简单的卷积神经网络,看看它是如何训练出结果的。这里使用 Keras 来定义和训练模型。
1、首先把图像放在一个特定的目录下
1images_cropped/2sandwich/3some_image.jpg4some_other_image.jpg5...6hamburger/7yet_another_image.jpg8...
然后 Keras 调用这些文件夹,Keras会检查输入的文件夹,并确定是二分类问题,并创建“图像生成器”。如以下代码:
1fromkeras.preprocessing.imageimportImageDataGenerator 2 3train_datagen=ImageDataGenerator( 4rotation_range=40, 5width_shift_range=0.2, 6height_shift_range=0.2, 7rescale=1/255, 8shear_range=0.2, 9zoom_range=0.2,10horizontal_flip=True,11fill_mode='nearest'12)1314test_datagen=ImageDataGenerator(15rescale=1/25516)1718train_generator=train_datagen.flow_from_directory(19'../data/images_cropped/quilt/open_images/',20target_size=(128,128),21batch_size=16,22class_mode='binary'23)2425validation_generator=test_datagen.flow_from_directory(26'../data/images_cropped/quilt/open_images/',27target_size=(128,128),28batch_size=16,29class_mode='binary'30)
我们不只是返回图像本身,而是要对图像进行二次采样、倾斜和缩放等处理(通过train_datagen.flow_from_directory)。其实,这就是实际应用中的数据扩充。数据扩充为输入数据集经过图像分类后的裁剪或失真提供必要的补偿,这有助于我们克服数据集小的问题。我们可以在单张图像上多次训练算法模型,每次用稍微不同的方法预处理图像的一小部分。
2、定义了数据输入后,接下来定义模型本身
1fromkeras.modelsimportSequential 2fromkeras.layersimportConv2D,MaxPooling2D 3fromkeras.layersimportActivation,Dropout,Flatten,Dense 4fromkeras.lossesimportbinary_crossentropy 5fromkeras.callbacksimportEarlyStopping 6fromkeras.optimizersimportRMSprop 7 8 9model=Sequential()10model.add(Conv2D(32,kernel_size=(3,3),input_shape=(128,128,3),activation='relu'))11model.add(MaxPooling2D(pool_size=(2,2)))1213model.add(Conv2D(32,(3,3),activation='relu'))14model.add(MaxPooling2D(pool_size=(2,2)))1516model.add(Conv2D(64,(3,3),activation='relu'))17model.add(MaxPooling2D(pool_size=(2,2)))1819model.add(Flatten())#thisconvertsour3Dfeaturemapsto1Dfeaturevectors20model.add(Dense(64,activation='relu'))21model.add(Dropout(0.5))22model.add(Dense(1))23model.add(Activation('sigmoid'))2425model.compile(loss=binary_crossentropy,26optimizer=RMSprop(lr=0.0005),#halfofthedefaultlr27metrics=['accuracy'])
这是一个简单的卷积神经网络模型。它只包含三个卷积层:输出层之前的后处理层,强正则化层和 Relu 激活函数层。这些层因素共同作用以保证模型不会过拟合。这一点很重要,因为我们的输入数据集很小。
3、最后一步是训练模型
1importpathlib 2 3sample_size=len(list(pathlib.Path('../data/images_cropped/').rglob('./*'))) 4batch_size=16 5 6hist=model.fit_generator( 7train_generator, 8steps_per_epoch=sample_size//batch_size, 9epochs=50,10validation_data=validation_generator,11validation_steps=round(sample_size*0.2)//batch_size,12callbacks=[EarlyStopping(monitor='val_loss',min_delta=0,patience=4)]13)1415model.save("clf.h5")
epoch 步长的选择是由图像样本大小和批处理量决定的。然后对这些数据进行 50 次训练。因为回调函数 EarlyStopping 训练可能会提前暂停。如果在前 4 个 epoch 中没有看到训练性能的改进,那么它会在 50 epoch 内返回一个相对性能最好的模型。之所以选择这么大的步长,是因为模型验证损失存在很大的可变性。
这个简单的训练方案产生的模型的准确率约为75%。
precisionrecallf1-scoresupport00.900.590.71139910.640.920.751109microavg0.730.730.732508macroavg0.770.750.732508weightedavg0.780.730.732508
有趣的是,我们的模型在分类汉堡包为第 0 类时信心不足,而在分类汉堡包为第 1 类时信心十足。90% 被归类为汉堡包的图片实际上是汉堡包,但是只分类得到 59% 的汉堡。
另一方面,只有 64% 的三明治图片是真正的三明治,但是分类得到的是 92% 的三明治。这与 Francois Chollet 采用相似的模型,应用到一个相似大小的经典猫狗数据集中,所得到的结果为 80% 的准确率基本是一致的。这种差异很可能是谷歌 Open Images V4 数据集中的遮挡和噪声水平增加造成的。数据集还包括其他插图和照片,使分类更加困难。如果自己构建模型时,也可以先删除这些。
使用迁移学习技术可以进一步提高算法性能。要了解更多信息,可以查阅 Francois Chollet 的博客文章:Building powerful image classification models using very little data,使用少量数据集构建图像分类模型
https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html
四、模型发布
现在我们构建好了一个定制的数据集和训练模型,非常高兴可以与大家分享。基于此也进行了一些总结,机器学习项目应该是模块化的可复制的,体现在:
将模型因素分为数据、代码和环境组件
数据版本控制模型定义和训练数据
代码版本控制训练模型的代码
环境版本控制用于训练模型的环境。比如环境可能是一个Docker文件,也可能在本地使用pip或conda
如果其他人要使用该模型,提供相应的{数据、代码、环境}元组即可
遵循这些原则,就可以通过几行代码,训练出需要的模型副本:
gitclonehttps://github.com/quiltdata/open-images.gitcondaenvcreate-fopen-images/environment.ymlsourceactivatequilt-open-images-devpython-c"importt4;t4.Package.install('quilt/open_images',dest='open-images/',registry='s3://quilt-example')"
结论
在本文中,我们演示了一个端到端的图像分类的机器学习实现方法。从下载/转换数据集到训练模型的整个过程。最后以一种模块化的、可复制的便于其他人重构的方式发布出来。由于自定义数据集很难生成和发布,随着时间的积累,形成了这些广泛使用的示例数据集。并不是因为他们好用,而是因为它们很简单。例如,谷歌最近发布的机器学习速成课程大量使用了加州住房数据集。这些数据有将近 20 年的历史了!在此基础上应用新的数据,使用现实生活的一些有趣的图片,或许会变得比想象中更容易!

有关文中使用的数据、代码、环境等信息,可通过下面的链接获取更多:
https://storage.googleapis.com/openimages/web/index.html
https://github.com/quiltdata/open-images
https://alpha.quiltdata.com/b/quilt-example/tree/quilt/open_images/
https://blog.quiltdata.com/reproduce-a-machine-learning-model-build-in-four-lines-of-code-b4f0a5c5f8c8
原文链接:
https://medium.freecodecamp.org/how-to-classify-photos-in-600-classes-using-nine-million-open-images-65847da1a319
-
神经网络
+关注
关注
42文章
4771浏览量
100766 -
图像分类
+关注
关注
0文章
90浏览量
11918 -
数据集
+关注
关注
4文章
1208浏览量
24701
原文标题:轻松练:如何从900万张图片中对600类照片进行分类|技术头条
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
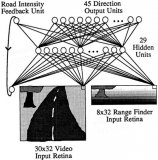
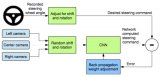
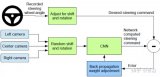
针对端到端自主驾驶模型的简单对抗实例
基于生成式对抗网络的端到端图像去雾模型

一种对红细胞和白细胞图像分类任务的主动学习端到端工作流程

小鹏汽车发布端到端大模型

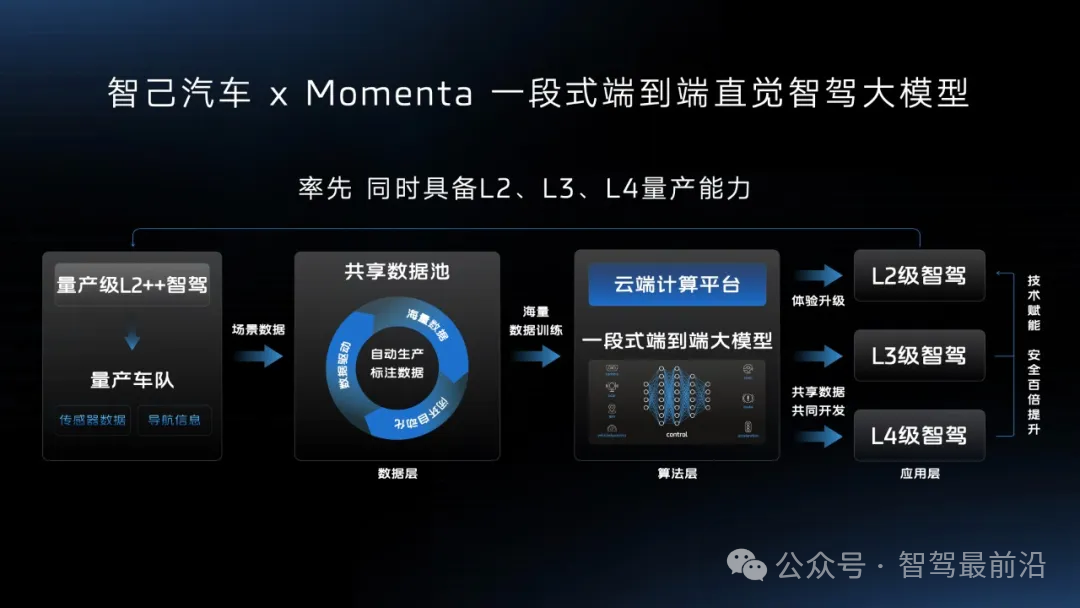
智己汽车“端到端”智驾方案推出,老司机真的会被取代吗?
连接视觉语言大模型与端到端自动驾驶






 工商网监
工商网监
评论