 FAIR何恺明、Ross等人最新提出实例分割的通用框架TensorMask
FAIR何恺明、Ross等人最新提出实例分割的通用框架TensorMask
FAIR何恺明、Ross等人最新提出实例分割的通用框架TensorMask,首次在定性和定量上都接近于 Mask R-CNN 框架,为探索密集实例分割方法提供基础。
现代实例分割方法主要是先检测对象边界框,然后进行裁剪和分割,Mask R-CNN是目前这类方法中最优秀的。
近日,来自FAIR的陈鑫磊、Ross Girshick、何恺明、Piotr Dollar等人发表一篇新论文“TensorMask: A Foundation for Dense Object Segmentation”,从一个新的方向解决实例分割问题,并提出了一个名为TensorMask的通用框架。

论文地址:
https://arxiv.org/pdf/1903.12174.pdf
作者表示,TensorMask达到了与Mask R-CNN相当的结果,有助于更全面地理解这项任务。
Ross Girshick、何恺明、Piotr Dollar三人也是Mask R-CNN的作者,一作陈鑫磊博士毕业于CMU,导师是Tom Mitchell教授,并曾在谷歌云AI李飞飞、李佳的指导下实习。
TensorMask:将实例分割视为4D张量预测
在密集、规则的网格上生成边界框对象预测的滑动窗口目标检测器(sliding-window object detectors)已经得到迅速发展,并得到了广泛的应用。
与此相反,现代的实例分割方法主要是先检测对象边界框,然后进行裁剪和分割,Mask R-CNN推广了这种方法。
在这项工作中,我们研究了密集滑动窗口实例分割(dense sliding-window instance segmentation)的范例,令人惊讶的是,这方面的研究十分不足。
我们的核心发现是,这项任务与其他的密集预测任务(如语义分割或边界框对象检测)有本质的不同,因为每个空间位置的输出本身就是一个几何结构,具有自己的空间维度。
为了形式化地说明这一点,我们将密集实例分割视为一个4D张量(4D tensors)的预测任务,并提出了一个名为TensorMask的通用框架,该框架显式地捕获这种几何图形,并支持对4D tensors使用新的操作符。
图1:TensorMask的输出。我们将密集实例分割作为一种基于结构化4D张量的预测任务。除了获得具有竞争力的定量结果,TensorMask还获得了定性上合理的结果。图中小的和大的物体都被很好地描绘出来,并且,重叠的物体也被正确地处理了。
我们证明了tensor这种想法可以相比baseline获得较大的增益,并且可以得到与Mask R-CNN相当的结果。这些结果表明,TensorMask可以作为密集掩码预测的新进展的基础,有助于更全面地理解这项任务。我们将发布本研究的代码。
弥补差距:实例分割中的密集方法
滑动窗口(sliding-window)范例——通过查看放置在一组密集图像位置上的每个窗口来查找对象——是计算机视觉中最早、也是最成功的概念之一,并且这个概念自然地与卷及网络相关。
然而,尽管目前性能最好的对象检测器依赖于滑动窗口预测来生成初始候选区域,但获得更准确的预测主要来自对这些候选区域进行细化的阶段,如Faster R-CNN和Mask R-CNN,分别用于边界框目标检测和实例分割。这类方法已经主导了COCO目标检测挑战赛。
近年来,诸如SSD和RetinaNet之类的边界框目标检测器,避开了“细化”这个步骤,专注于直接的滑动窗口预测,已经有了复苏的趋势,并显示出有希望的结果。
相比之下,该领域在密集滑动窗口实例分割方面并没有取得同等的进展;对于mask prediction,没有类似于SSD / RetinaNet这样的直接、密集的方法。
为什么密集的方法在边界框检测方面进展迅速,而在实例分割方面却完全缺失?这是一个基本科学上的问题。这项工作的目标就是弥补这一差距,并为探索密集实例分割方法提供基础。
我们的主要观点是,定义dense mask representations的核心概念,以及这些概念在神经网络中的有效实现,都是缺乏的。
与边界框不同,边界框具有固定的低维表示而不考虑比例,分割掩码(segmentation masks)可以从更丰富、更结构化的表示中获益。例如,每个mask本身是一个2D空间映射,较大对象的mask可以受益于较大空间映射的使用。为dense masks开发有效的表示是实现密集实例分割的关键步骤。
为了解决这个问题,我们定义了一组用高维张量表示mask的核心概念,这些概念允许探索用于dense mask prediction的新颖网络架构。为了证明所提出的表示的优点,我们提出了几个这样的网络并进行了实验。
我们的框架称为TensorMask,它建立了第一个密集滑动窗口实例分割系统,其结果接近于Mask R-CNN。

左:自然表示。右:对齐表示(Aligned representation)。
TensorMask表示的核心想法是使用结构化的4D tensors表示空间域上的mask。
与以前的面向通道的方法不同,我们建议利用形状(V, U, H, W)的4D tensors,其中(H, W)表示目标位置,(V, U)表示对应的mask的位置,它们都是几何子张量,也就是说,它们的轴有明确定义的units和关于图像的几何意义。
这种从非结构化通道轴上的encoding masks到使用结构化几何子张量的视角转变,使得定义新的操作和网络架构成为可能。这些网络可以以几何上有意义的方式直接作用于(V, U)子张量,包括坐标变换、up-/downscaling和金字塔的使用。
在TensorMask框架的支持下,我们在一个4D tensors的标度索引列表上建立了一个金字塔结构,我们称之为张量双金字塔( tensor bipyramid)。与特征金字塔类似,tensor bipyramid是一个多尺度特征映射列表,它包含一个形状为2kV、2ku、12kh、12kw的4D张量列表,其中k≥0个索引尺度。这种结构在(H, W)和(V, U)几何子张量上都呈金字塔形状,但方向相反。这种设计捕捉了大对象具有粗糙空间定位的高分辨率mask(大k)和小对象具有精细空间定位的低分辨率mask(小k)的理想特性。
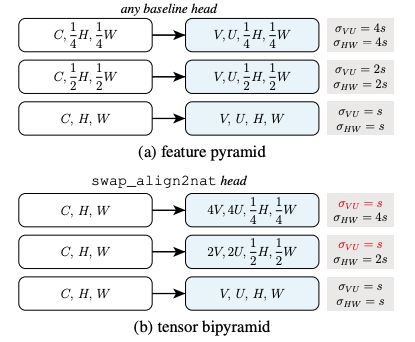
feature pyramid和tensor bipyramid的比较
我们将这些组件组合成一个网络骨干和训练程序,类似RetinaNet,其中我们的dense mask predictor扩展了原始的密集边界框预测器。
通过详细的消融实验,我们评估了TensorMask框架的有效性,并证明了明确捕捉该任务的几何结构的重要性。最后,我们展示了TensorMask与对应的Mask R-CNN产生了相似的结果(见图1和图2)。
TensorMask的架构
TensorMask框架的核心思想是使用结构化的高维张量来表示一组密集滑动窗口中的图像内容(例如masks)。
图2:使用ResNet-101-FPN骨干的TensorMask和Mask R-CNN的示例结果(与图6中使用的Mask R-CNN的图像相同)。结果在定量和质量上都很相似,表明密集滑动窗口范式确实可以有效地用于实例分割任务。请读者猜猜哪些结果是TensorMask生成的(答案见文末)。
TensorMask架构
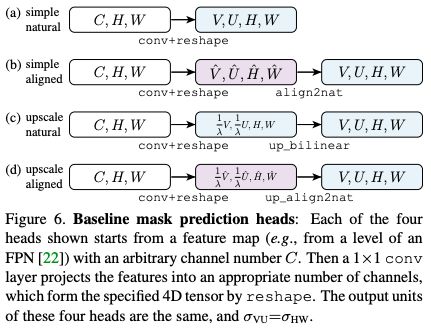
我们已经展示了采用TensorMask representations的模型。这些模型有一个在滑动窗口中生成masks的mask prediction head,以及一个用于预测对象类别的classification head,类似于滑动窗口目标检测器中的box regression和classification heads。
实验和结果
我们报告了COCO实例分割的结果。所有的模型都在~118k train2017图像上进行训练,并在5k val2017图像上进行测试。最终结果在test-dev上。我们使用COCO mask的平均精度(用AP表示)。box AP用APbb表示。
TensorMask表示
首先,我们研究了使用V =U=15和ResNet-50-FPN骨干的mask的各种张量表示。表2报告了定量结果,图2和图9显示了定性比较。

表2
与Mask R-CNN的比较
表3总结了test-dev上最好的TensorMask模型,并将其与当前用于COCO实例分割的主流方法Mask RCNN进行了比较。
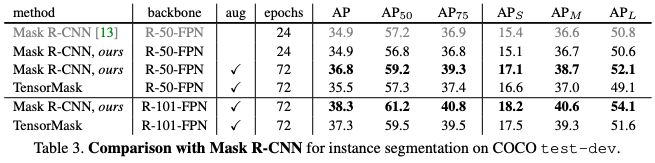
表3
如上表所示,最好的TensorMask在test-dev上达到了35.5 mask AP,接近于mask R-CNN的36.8。
在ResNet-101中,TensorMask实现了37.3 mask AP,与mask R-CNN相比只有1.0 AP差距。
这些结果表明,密集滑动窗口方法可以缩小与“先检测后分割”方法的差距。定性结果如图2、10、11所示。
结论
TensorMask是一个dense sliding-window实例分割框架,首次在定性和定量上都接近于Mask R-CNN框架。TensorMask为实例分割研究建立了一个概念互补的方向。
(图2答案:第一行是Mask R-CNN的结果,第二行是TensorMask的结果。)
-
检测器
+关注
关注
1文章
871浏览量
47809 -
神经网络
+关注
关注
42文章
4785浏览量
101276 -
AI
+关注
关注
87文章
31845浏览量
270672
原文标题:何恺明等最新论文:实例分割全新方法TensorMask,效果比肩 Mask R-CNN
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
图像分割基础算法及实现实例

何恺明、Ross Girshick等大神深夜扔出“炸弹”:ImageNet预训练并非必须
FAIR何恺明团队最新论文提出“全景FPN”,聚焦于图像的全景分割任务
李飞飞等人提出Auto-DeepLab:自动搜索图像语义分割架构
何恺明等人再出重磅新作:分割任务的TensorMask框架
FAIR何恺明团队近日发表神经结构搜索NAS方面的最新力作

Facebook AI使用单一神经网络架构来同时完成实例分割和语义分割


深度学习部分监督的实例分割环境
用于实例分割的Mask R-CNN框架
基于X光图片的实例分割垃圾数据集WIXRay (Waste Item X- Ray)
用于弱监督大规模点云语义分割的混合对比正则化框架
基于通用的模型PADing解决三大分割任务

基于SAM实现自动分割遥感图像实例






 工商网监
工商网监
评论