 鲲云发布超高效CAISA2.0架构 为AI提供更高算力支撑
鲲云发布超高效CAISA2.0架构 为AI提供更高算力支撑
2019年4月9日,第二届全球人工智能应用创新峰会在深圳五洲宾馆举行,这场由深圳市科学技术协会、福田区科技创新局主办,鲲云科技、鲲云人工智能应用创新研究院和源创力创新中心承办的AI开年盛会上,鲲云科技发布全球第一款基于数据流技术打造的通用人工智能底层架构-定制数据流CAISA架构和端到端自动编译工具链RainBuilder,实现了国内完全自主产权的AI芯片架构,有效计算效率大幅领先国际水平,为人工智能算法的快速应用落地提供高性能算力支撑,推动我国人工智能芯片领域的技术革新和发展。深圳市人大常委会副主任、深圳市科协主席蒋宇扬,深圳市福田区委常委、副区长黄伟,深圳市源创力离岸创新中心总裁周路明,深圳市科协秘书长、办公室主任林肇武,深圳市福田区科技创新局、发展和改革局和工业和信息化局等单位负责同志出席峰会。
打破摩尔定律局限,鲲云发布全球首款通用底层AI架构-定制数据流CAISA架构
牛昕宇博士
作为本次峰会的重头戏,鲲云科技创始人&CEO牛昕宇博士在会上发布了定制数据流CAISA2.0架构。依托创始团队在数据流架构领域近三十年的积累,鲲云的CAISA架构抛弃了传统基于指令集的架构方式,是全球第一款基于数据流技术打造的通用人工智能底层架构,可发挥90%以上的芯片峰值计算性能,大幅领先国际主流AI芯片。同时,鲲云还在会上发布了针对数据流架构定制开发的RainBuilder编译工具链,CAISA2.0架构可支持Tensorflow,Caffe等开源框架下开发的主流深度学习算法的无缝迁移,无需用户进行面向CAISA架构的编程。基于Arria10 SX160、SX660、GX1150,Straix10 GX2800系列的FPGA加速卡已完成开发并应用于产品落地中。
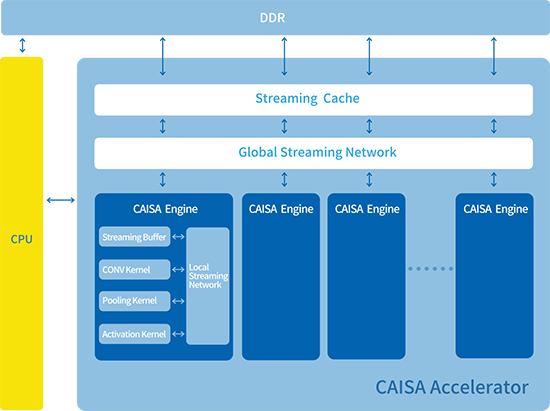
(定制数据流CAISA2.0架构)
随着人工智能技术的深入发展,对人工智能芯片的算力提出了更高的要求,算力成为了决定算法落地的重中之重。尤其是在云计算、自动驾驶、安防工业等领域,算力的提升更是能够直接带来更多的用户量、更多的前端设备智能升级和更安全的自动驾驶汽车。正如图灵奖得主John Hennessey和 David Patterson在图灵奖颁奖典礼所言,未来十年,随着摩尔定律逐步饱和,人工智能芯片的峰值算力将逐步趋近饱和,而架构效率将成为芯片性能的决定因素,未来十年将是计算架构的“黄金十年”。鲲云科技自主研发的CAISA2.0架构以及RainBuilder编译工具链,没有采用主流计算机架构下大规模并行指令集设计的思路,通过完全不同的数据流架构突破底层架构的效率瓶颈,最大化发挥底层硬件的效率,在同等峰值芯片性能情况下可以为人工智能应用提供更高的算力支撑。
打造最好用的AI芯片编译工具,CAISA架构的端到端自动编译工具链RainBuilder面世,让人工智能更简单
要实现更快的AI应用落地,满足不同算法开发的需求,需要一个可以兼容各类算法框架和方便快捷实现算法到硬件写入的编译工具。为了降低使用门槛,鲲云发布了端到端自动编译工具链RainBuilder,它是一款针对深度学习算法优化加速的开发工具链。依托于CAISA架构的高性能特性,RainBuilder提供从算法模型到芯片级算法部署的一整套开发套件。该套件主要由Compiler和Runtime两部分组成,其中Compiler包含了一系列命令行接口,支持主流AI开发框架模型的解析和优化,并将模型转化为适用于CAISA架构的中间表达和数据。Runtime以Compiler生成的中间表达和数据为输入,为用户提供了丰富易用的开发接口以完成对底层AI芯片硬件的高效应用。
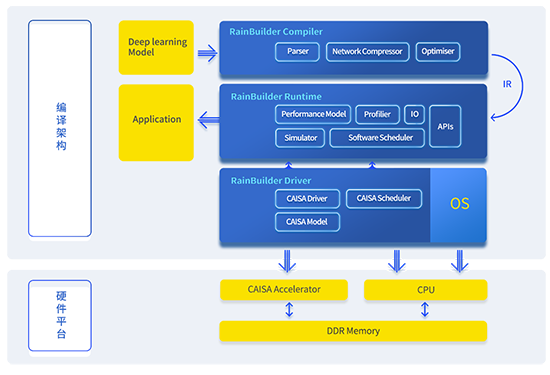
(RainBuilder端到端自动编译工具链)
RainBuilder使用过程非常简单便捷,用户无需对于底层硬件有深入的了解,即可快速开发适用于AI专用芯片的算法方案。从训练好的模型文件,只需两步,即可实现整个神经网络的推演。首先,调用Compiler的命令行接口完成模型的离线准备,对于一个模型,该步骤只需进行一次。Compiler提供了一套端到端的优化流程,包括模型解析、冗余节点裁剪、节点融合、模型量化压缩等。之后用户只需编写针对特定算法的前后处理函数,Runtime会自动完成算法模型对于CAISA架构的高效调用。Runtime中包含了大量针对CAISA架构的深层优化,如硬件资源调配、运行时资源调度、软硬件并行、异常处理等。另外,RainBuilder通过支持用户自定义算子实现了对于不同算法的高拓展性。用户只需根据提供的接口即可完成自定义模块的实现,RainBuilder会自动将自定义算子整合进计算图中,并针对其特点完成相应的计算优化。
提供下一代人工智能计算平台,鲲云公布基于CAISA架构的系列AI产品,鲲云高性能AI芯片切入工业市场
会上,鲲云还公布了基于CAISA架构的一系列产品,包括针对前端和边缘计算的“雨人”AI芯片加速卡3代和应用于NVR和服务器的“星空”AI加速卡2代,目前已经在电力、安防、工业等领域实现了规模落地。同合作伙伴联合开发的搭载雨人加速卡的AI摄像头、智能无人机、智能ops系统盒子,搭载星空加速卡的两款AI服务器也同时披露。
(雨人加速卡3代)
“雨人”加速卡可嵌入前端IoTs设备,提供深度学习目标定位、去重一体化前端方案,支持1080p高清实时视频对于60x60像素特定目标全检测,具有50帧/秒的处理能力。
(星空加速卡2代)
“星空”加速卡嵌入小型主机和服务器设备,即插即用,可同时支持16路1080p视频中对最小60×60像素的特定目标全检测及视频结构化分析,实现1080P高清实时视频200-800帧/秒的检测性能,延时低至5毫秒,功耗为35w,实测性能达理论峰值的90%。充分体现了自主研发的定制数据流CAISA架构芯片高性能、低功耗、低延时的特性,最大化资源能效比。可为安防行业中交通、商场和住宅等场景数字安全监控及行人、车辆、路况等提供深度学习目标定位、去重、识别、属性分析一体化的边缘后端人工智能加速方案。
鲲云高校计划发布,联合高校开展人工智能教学科研合作
为满足高校日益增长的在人工智能领域教学培训、科研平台方面的需求,鲲云科技结合自身在人工智能芯片、开发平台和垂直领域解决方案等方向的研发和技术优势,以及与市场端广泛的互动关系,由鲲云人工智能应用创新研究院发起,鲲云正式发布鲲云高校计划CUP (Corerain University Program),与全球高校在人工智能课程、科研合作和国际交流等领域实现深度合作。
在课程方面,鲲云提供基于CAISA架构FPGA加速卡的人工智能课程及实验内容,支持高校相关课程升级;在科研方面,鲲云支持高校基于CAISA架构运行最新人工智能算法,以及围绕CAISA架构拓展硬件平台;在国际合作领域,鲲云提供人工智能峰会、人工智能硬件加速暑期峰会等国际交流平台,全方位支持与高校在AI领域的合作,加速最新AI技术的产学研合作。
2019年2月24日,鲲云高校计划启动,联手英特尔开展的基于Intel? FPGA的人工智能芯片应用设计培训的交流活动完美落幕,来自清华大学、武汉大学、华中科技大学、山东大学、天津大学、重庆大学、电子科技大学等近30所高校的40余位老师参加。除与Intel合作进行人工智能课程培训外,鲲云人工智能应用创新研究院已同帝国理工学院、哈尔滨工业大学、天津大学等成立联合实验室,在定制计算、AI芯片安全、工业智能等领域开展前沿研究合作。
高端会晤,国际AI领域权威分享人工智能前沿技术突破
作为年度重量级AI峰会,此次活动汇聚了政府领导、全球人工智能领域顶尖学术大师、世界顶级科技企业、互联网巨头,产业界、投资界行业领袖,共同探讨人工智能实战落地和产学研发展方向。整个峰会由政府致辞、主题演讲和产业论坛三个环节组成。会上,几位人工智能领域的国际权威,包括获得“IT诺贝尔奖”的Viktor K. Prasanna教授,IEEE终身会士Sun Yuan Kung(贡三元)教授,国际学术界公认的世界上极少数同时在数据库理论与系统两个领域做出突破性贡献的Wenfei Fan(樊文飞)院士,定制计算国际权威Wayne Luk 陆永青院士,清华大学魏少军教授,以及高性能计算领域的Cristina Silvano教授等院士嘉宾就计算加速技术在人工智能领域的落地应用、AI方法的研究演进、面向人工智能应用的定制计算加速技术以及高能效高性能并行集群计算,软件定义芯片等内容做主题报告。
除了诸位院士、会士嘉宾的专业分享以外,Intel PSG战略市场总监的Tony Kau、浪潮人工智能与产品总经理刘军,也分享了英特尔和浪潮在人工智能的落地应用以及创新技术等方面的技术革新和新进展,也分享了同鲲云在AI加速应用和高校推广等方面的深入合作。
此外,峰会还邀请到星瀚资本杨歌、雷锋网麦广炜、天津大学电子信息学院副院长刘强、JWIPC副总经理刘迪科、CCE-YOCSEF深圳主席卢昱明等专家学者与鲲云科技CTO蔡权雄博士就人工智能芯片产业与生态落地等话题进行了探讨。
2019年人工智能应用创新峰会顺利结束,干货满满,在未来计算架构的黄金十年,鲲云科技是否能够凭借自己多年积累的数据流架构厚积薄发,在AI芯片性能上实现突破?我们拭目以待。
-
人工智能
+关注
关注
1792文章
47477浏览量
239144 -
AI芯片
+关注
关注
17文章
1897浏览量
35120 -
鲲云科技
+关注
关注
0文章
39浏览量
3833
发布评论请先 登录
相关推荐
迅为瑞芯微RK3562开发板主频2.0内置NPU算力达1TOPS,核心板扩展更多功能
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--全书概览
青云科技强化AI算力架构,升级产品与服务体系
迅为瑞芯微RK3588与3588S如何选型硬件区别
iTOP-3562开发板/核心板采用RK3562,集成四核A53+Mali G52架构
名单公布!【书籍评测活动NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架构分析
ElfBoard技术贴|如何将libwebsockets库编译为x86架构

助力全国一体化算力网建设,神州鲲泰以算力构建新质生产力

鲲泰新闻|神州鲲泰创新智算之旅北京站开幕,发布全新智算架构和液冷整机柜产品应对 “多云、异构、绿色

打造新型智算中心,神州鲲泰中标中移动智算中心采购

神州鲲泰推出全新智算架构及硅光+液冷整机柜,破解多云异构绿色智算难题
深度践行“IaaS on DPU”理念,中科驭数正式发布“驭云”高性能云异构算力解决方案!






 工商网监
工商网监
评论