 数据挖掘的任务有哪些
数据挖掘的任务有哪些
数据挖掘的任务有哪些
1、关联分析(associationanalysis)
关联分析挖掘是由RakeshApwal等人首先提出的。两个或两个以上变量取向价值之间存在某种规律性发掘称之为关联。数据关联是数据库中存在的一类重要的、可被发现的知识。关联分为简单关联、时序关联和因果关联。关联分析的目的是找出数据库中隐藏的大量关联网。一般用支持度和可信度两个阀值来度量获取关联规则的相关性,还有兴趣度、相关性等参数,使得所挖掘的规则更符合实质需求。
2、聚类分析(clustering)
聚类是把数据按照相似性归纳成若干类别分类出来,同一类中的数据彼此相似,不同类中的数据则相异。聚类分析可以建立宏观的概念,发布数据的分布模式,以及可能性的数据属性之间的相互关系。
3、分类(classification)
分类其实就是找出一个类别的概念描述,代表了数据的整体信息,分类的内涵描述,并用描述来构造模型,一般用作于规则或决策树模式表示出来。分类是利用训练数据集中通过一定的算法而求得分类规则。分类可被用于规则描述和数据预测。
4、预测(predication)
通过预测利用历史数据找出变化规律,建立模型并由该模型对未来数据的种类及特征进行预测。预测关心的是精确度和不确定性因素,通常用预测方差来度量较为适合。
通过时间序列搜索出的重复发生概率比较高的模式。与回归一样,它也是用己知的数据预测未来的数据值,但这些数据的区别是变量所处时间的不同而已。
6、偏差分析(deviation)
在偏差中包括很多有用的知识,数据库中的数据存在很多异常情况,发现数据库中数据存在的异常情况是非常重要的。偏差检验的基本方法就是寻找观察结果与参照之间的差别。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
数据挖掘
+关注
关注
1文章
406浏览量
24191
发布评论请先 登录
相关推荐
中科曙光受邀参加第十届中国数据挖掘会议
近日,国内数据挖掘领域最主要的学术活动之一—第十届中国数据挖掘会议(CCDM2024)于山东泰安举行,中科曙光参与并分享了曙光AI构建产学研用的生态实践。
如何使用freeRTOS在两个任务之间传输任务数据?
和压力。 I2C 主控器基于其他演示项目\"硬件抽象层 (HAL):I2C 主控器\"
任务 1:尽可能快地读取传感器数值
任务 2:将数据写入 NAND 闪存或 SD 卡
我
发表于 07-03 07:55
用的cube生成的freertos工程,串口和任务通过邮箱通讯,结果任务反应很慢是怎么回事?
用的是DMA+空闲中断,将接收数组的指针,通过邮箱发送给任务。
任务通过邮箱得到接收数组的指针,然后逐个复制到任务里建立的数组,再通过串口发送出去。
现在结果是上位机发送数据大概七八
发表于 05-08 08:13
FreeRTOS系统使用xTaskCreate产生的任务与osThreadDef 产生的线程有什么不同?
请教下是要 FreeRTOS系统, 使用 xTaskCreate 产生的任务 与 osThreadDef产生的线程有什么不同?
发表于 04-29 07:20
freertos串口接收数据后如何发送给任务?
正在学freertos。串口中断接收一帧数据后,放到数组里,如何将数据发送给任务呢?
如果用消息队列,是否建立的消息队列需要是数组类型的?还是说消息列表建立成uint8类型的,列表长度设为接收
发表于 04-18 06:36
zigbee发包时过程被其他任务中断,导致发送数据丢失怎么解决?
1、问题描述:
zigbee发包时过程被其他任务中断,导致发送数据丢失
2、芯片型号:STM32WB55
发表于 03-13 08:14
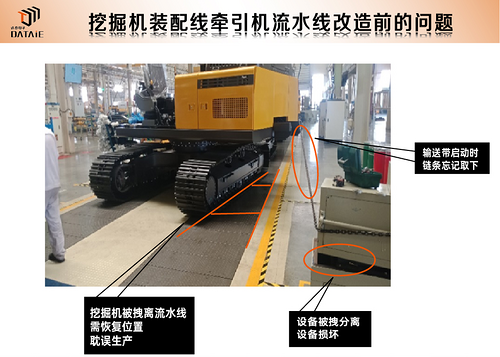
挖掘机生产装配线无线通讯应用
一、应用背景 山东某挖掘机机械有限公司主要产品有装载机、挖掘机、道路机械及核心关键零部件等系列工程机械产品。为加速新旧动能转换,全新挖掘机整机装配线配合劳动组合的调整,提高装配水平和生
iBeLink KS MAX 10.5T大算力领跑KAS新领域
Kaspa是一种基于DAG(有向无环图)技术的加的密的货的币,它拥有高速、安全、可扩展的特点,是未来区的块的链领域的新星。为了挖掘Kaspa,我们需要一款专门的挖掘机,能够适应Kaspa的特殊算法
发表于 02-20 16:11
verilog中函数和任务对比
对比,方便学习理解。 比较 函数 任务 输入 函数至少需要包含一个输入,端口类型不能包含inout类型 任务可以没有或者有多个输入,且端口声明可以为inout类型 输出 函数无输出 任务
数据挖掘的应用领域,并举例说明
数据挖掘(Data Mining)是一种从大量数据中提取出有意义的信息和模式的技术。它结合了数据库、统计学、机器学习和人工智能等领域的理论和方法,通过高效的算法和工具,对大
任务调度系统设计的核心逻辑
Redis的读写性能极好,分布式锁也比Quartz数据库行级锁更轻量级。当然Redis锁也可以替换成Zookeeper锁,也是同样的机制。
在小型项目中,使用:定时任务框架(Quartz/Spring Schedule)和 分布式锁(redis/zookeeper)
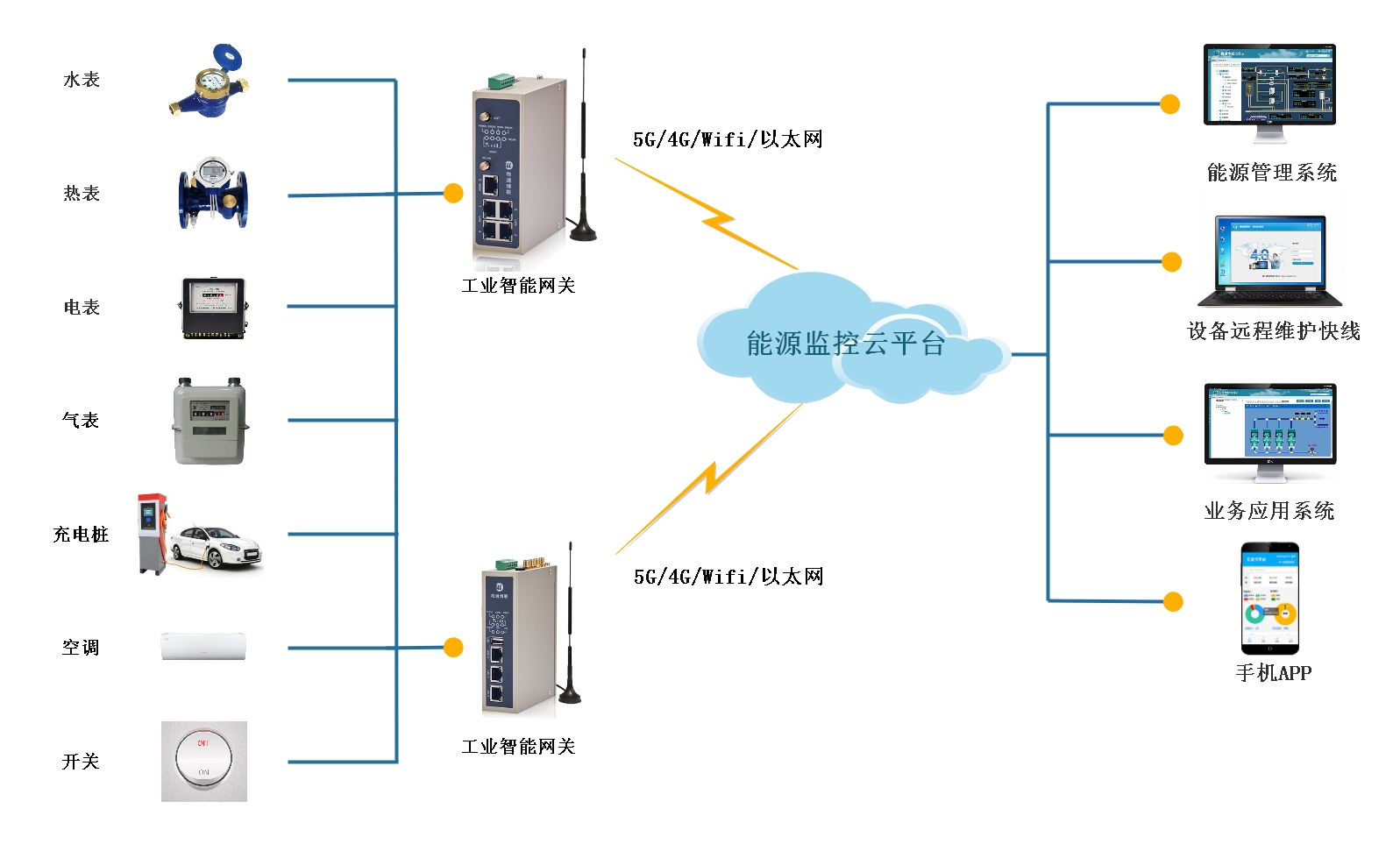
如何通过能源数据管理挖掘智慧楼宇的节能空间
性能的同时优化能耗,对此我们需要了解建筑内各种能源的使用结构、使用时间等信息。对此,物通博联提供智慧楼宇的能源数据管理系统,实现楼宇内各种能源的数据采集与可视化监控,并建立能源全面数据视图,帮助确定可以
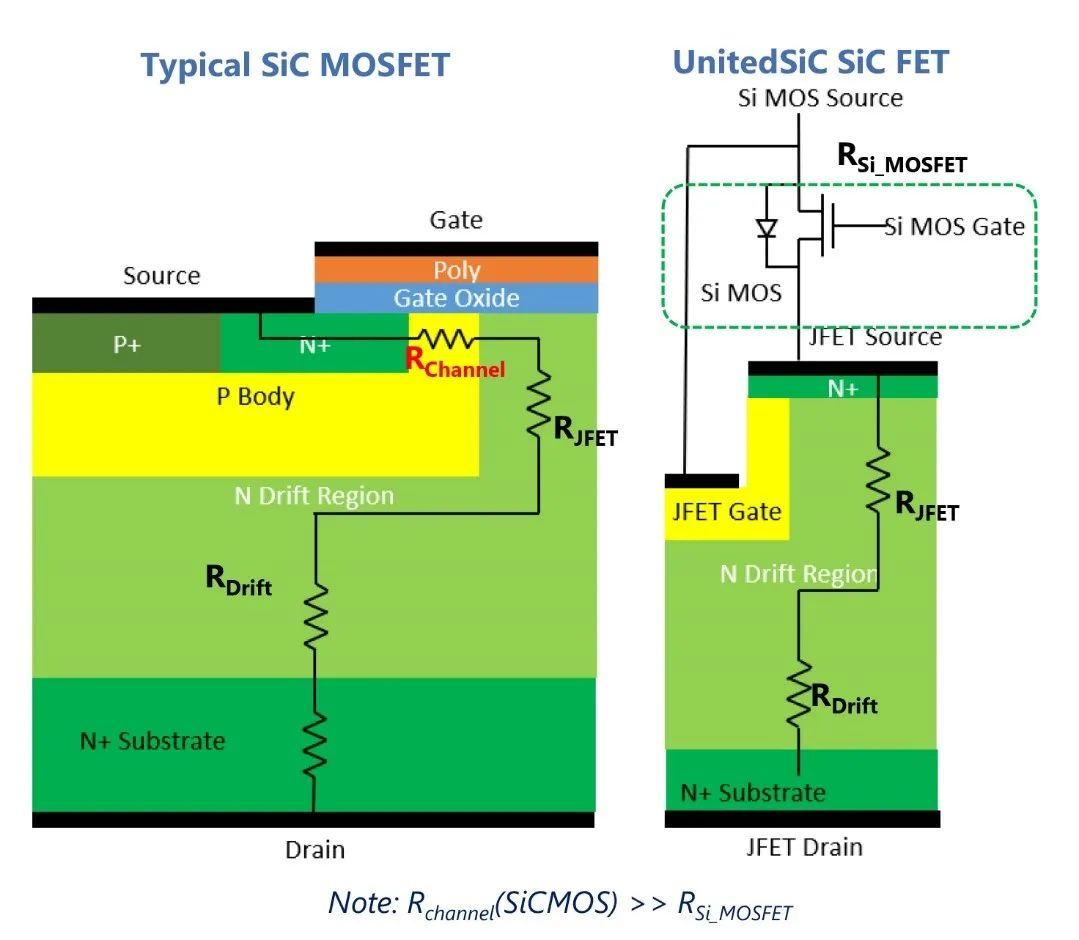
数据挖掘示波器与传统示波器的区别在哪里?
数据采集方式:传统示波器通过将模拟信号转换为数字信号进行采集和显示。而数据挖掘示波器主要用于数字信号的采集和分析,例如从数字通信系统、传感器网络等获取的数字信号进行处理和分析。
FreeRTOS中的任务管理
任务是 FreeRTOS 中最基本的调度单元,它是一段可执行的代码,可以独立运行。FreeRTOS 中的任务是基于优先级的抢占式调度,优先级高的任务可以抢占优先级低的任务的 CPU 资





 工商网监
工商网监
评论