 西安交通大学人工智能与机器人研究所公开全球首个五维驾驶场景理解数据集
西安交通大学人工智能与机器人研究所公开全球首个五维驾驶场景理解数据集
在自主驾驶领域,已经建立了大量的数据集来辅助完成三维或二维目标检测、立体视觉、语义或实例分割等任务。然而,更有意义的自主车辆周围对象的动态演化却很少被利用,并且缺乏大规模的数据集平台。为了解决这个问题,西安交通大学构建并公开了BLVD数据集,与以往静态检测、语义或者实例分割任务的数据集不同,BLVD旨在为动态4D跟踪(3D+时间)、5D交互事件识别(4D+交互行为)和意图预测等任务提供一个统一的验证平台。
BLVD数据集与之前的数据集相比将体现出对交通场景的更深层次理解。BLVD一共标注654个包含12万帧的序列。并进行了全序列5D语义注释。包含249129条3D目标框,4902个有效可跟踪的独立个体,包含总长度约214900个跟踪点,6004个用于5D交互事件识别的有效片段以及4900个可以进行5D意图预测的目标。根据标注场景中交通参与者的密集程度(低和高)和光照条件(白天和晚上),BLVD包含四种场景。
论文发表于ICRA2019,BLVD数据集已经公开,并可在github项目站点:
https://github.com/VCCIV/BLVD/下载。
论文网址参见:https://arxiv.org/abs/1903.06405
在BLVD数据集中,定义了三种参与者,包括车辆、行人和骑行者,其中骑行者包括骑自行车的人和摩托车的人。数据构建由西安交通大学夸父号无人车采集,采集车上装载多种传感器用于周围感知,包括一个Velodyne HDL-64E三维激光雷达、一个全球定位系统(GPS)及惯性导航系统、两个高分辨率多视点相机。值得注意的是,所装载的所有的传感器都是自动进行了时钟同步和对齐。与以往的驾驶场景中的三维目标跟踪、行为理解与分析数据集相比,BLVD具有更丰富的场景多样性。包含不同驾驶场景(城市和高速公路)、多种光照条件(白天和晚上)、多种个体密度。图1给出了一个典型的简介,它表示从数据集测试的静态3D注释到5D意图预测的任务流程。
图1 BLVD上5D语义注释的任务流示意。(a)表示包含多个静态三维目标的数据帧,(b)展示4D(3D+时间)维度的三维目标跟踪,(c)表示5D交互行为类型,每一个个体都进行了类型标注。(d)展示5D意图预测示意,包含位置预测、3D框的几何结构、朝向和行为交互状态预测。
值得注意的是,BLVD的不同数据任务具有一致的数据划分标准,可以提供从三维目标跟踪、五维度行为交互状态识别、五维度意图预测任务的串行多任务验证。其中对于五维度行为交互状态识别,对于不同的交通参与者,如车辆、行为何骑行者,分别设定了13种、8种及7种行为状态,如图2所示。
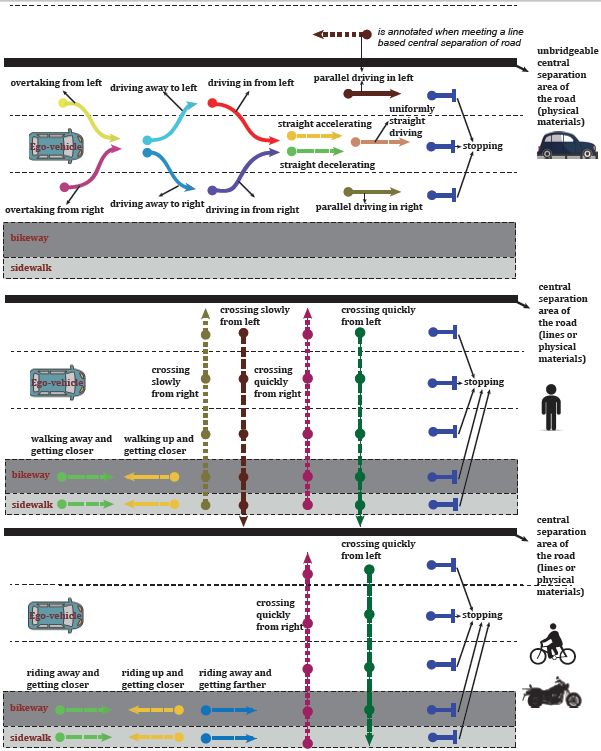
图2基于车辆坐标系的交互行为类型的说明。从上到下依次展示活动车辆、行人和骑手的活动类型。注意,有一个额外的参与者交互行为类型(指“其它”)用于表示其他的交互行为类型。
【结论】
西安交通大学人工智能与机器人研究所研究人员为自主驾驶构建的大规模5D语义数据集,采集于多种驾驶场景,并能够高效、准确地进行校准、同步和校正。不同于以往的静态检测/分割任务,他们更注重对交通场景的深入理解。具体来说,本次数据标注了4D跟踪、5D交互状态识别、5D意向预测等任务。在不断的优化完善下,相信这个数据集将在机器人和计算机视觉领域非常有用。
-
传感器
+关注
关注
2554文章
51686浏览量
758430 -
激光雷达
+关注
关注
969文章
4053浏览量
190824 -
数据集
+关注
关注
4文章
1212浏览量
24956
原文标题:西安交通大学人工智能与机器人研究所公开全球首个五维驾驶场景理解数据集
文章出处:【微信号:IV_Technology,微信公众号:智车科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
短讯:全球首个!人形机器人技术新突破
【「具身智能机器人系统」阅读体验】2.具身智能机器人的基础模块
【「具身智能机器人系统」阅读体验】2.具身智能机器人大模型
【「具身智能机器人系统」阅读体验】1.初步理解具身智能
《具身智能机器人系统》第7-9章阅读心得之具身智能机器人与大模型
【「具身智能机器人系统」阅读体验】+数据在具身人工智能中的价值
【「具身智能机器人系统」阅读体验】+初品的体验
《具身智能机器人系统》第1-6章阅读心得之具身智能机器人系统背景知识与基础模块
优艾智合与西安交大成立具身智能机器人研究院

名单公布!【书籍评测活动NO.51】具身智能机器人系统 | 了解AI的下一个浪潮!
开启全新AI时代 智能嵌入式系统快速发展——“第六届国产嵌入式操作系统技术与产业发展论坛”圆满结束
FPGA在人工智能中的应用有哪些?
阿尔泰科技与西安交通大学陕西省某技术重点实验室共谋未来!

人工智能与机器人的区别
直线电机生产厂家谈高校建成投用人形机器人研究院






 工商网监
工商网监
评论