 解析DARTS:海量数据训练和新样本特征的综合
解析DARTS:海量数据训练和新样本特征的综合
摘要:研究人员首次将深度学习与贝叶斯假设检验结合,利用深度学习强化RNA可变剪接分析的准确性。
在生命科研领域,常有人说深度学习的基因组学应用好比是“一个盲人在一间黑暗的房子里寻找一顶并不存在的黑色帽子”。言下之意,是遗憾深度学习的基因组学应用并没有给人们带来太多惊喜。不过,近日宾夕法尼亚大学和费城儿童医院教授邢毅团队的一项研究,找到了这样一顶“黑帽子”。
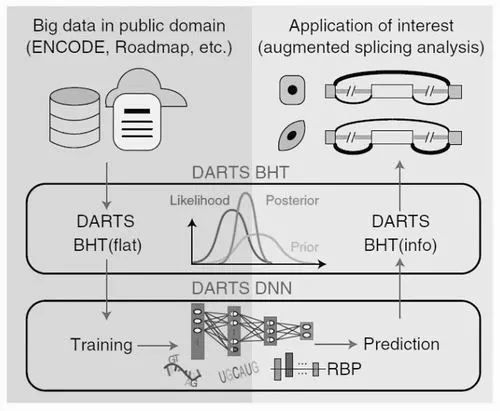
这项发表在《自然—方法》上的论文成果,提出了一种新的计算框架——DARTS(“利用深度学习强化对RNA-seq的可变剪接分析”英文的首字母缩写)。该计算框架首次将深度学习与贝叶斯假设检验结合,用于RNA可变剪接分析。这种结合使得它即使对于测序深度不那么高的样品,也能有效提高RNA-seq定量差异剪接的准确度。
清华大学生命科学学院教授张强锋点评道:“DARTS综合了深度学习和贝叶斯假设检验统计模型的优点,为那些低测序深度的数据提供了更好的做可变剪接分析的手段,拓展了传统RNA-seq可变剪接分析的敏感度和准确度。”
计算基因组学中
一个广受关注的问题
邢毅等人在上述论文中指出,目前,RNA-seq技术是研究RNA剪接最常用的实验手段。然而,RNA-seq技术虽然能较好地定量基因表达的结果,但对于差异剪接分析来说,它依赖于更高的测序深度。而且即便如此,现有的计算方法还不能较准确地定量低表达基因的剪接变化。因此,为了提高剪接定量的准确性,急需引入新的计算分析方法。
“可变剪接现象从20世纪70年代被发现后,其基本的科学问题聚焦为可变剪接位点发现、差异分析、调控元件和网络的发现和构建。RNA-seq 技术的发明,使得系统、定量的可变剪接差异分析成为可能。”张强锋介绍说,大量测序数据的可变剪接差异分析需要优秀的统计模型和计算工具,因此一直是一个需要高度技巧的生物信息学研究课题。
据张强锋介绍,邢毅研究组在针对大量测序数据的可变剪接差异分析的计算分析领域深耕多年,已经贡献了多个有影响力的算法和计算工具。该团队针对高通量RNA-seq数据开发出的用于差异剪接分析的rMATS等软件,对于测序较深、质量较好的数据集都能取得不错的结果,已在全世界范围内被广泛下载使用。
然而,由于成本等原因,大量RNA-seq 测序实验设计的测序深度较浅。对于这些数据集,能利用来做差异分析的可变剪接事件非常有限。
美国卡耐基梅隆大学计算机学院教授马坚也表示,在基因组学中,确实有很多类似的问题——如何在现有数据上对特定的基因组标注(譬如染色质结构、转录因子结合)训练一个机器学习模型并在全新的细胞系中有效预测,已经成为一个计算基因组学中广泛关注的问题。“DARTS崭新的整体设计理念值得很多其他类似的问题借鉴。”
DARTS计算框架
给出问题答案
据邢毅研究组这篇发表在《自然—方法》上的论文介绍,DARTS由两部分构成:深度神经网络模块(DNN)和贝叶斯推断模块(BHT)。其中,DNN基于顺式序列特征和样品特异的RNA结合蛋白表达水平特征来预测差异剪接的结果;而BHT则通过整合实验样品测序数据本身和基于深度神经网络的先验概率来推断差异剪接的结果。
研究者在论文中强调称,与其他计算方法不同的是,在DARTS计算框架下,DNN不仅通过顺式序列特征来预测可变剪接的结果,而且还将样品中RNA结合蛋白的表达水平整合进了RNA可变剪接结果的预测中,增加了预测参数的维度。
DARTS的逻辑是,通过DNN对ENCODE和Roadmap数据库中大量RNA-seq结果的深度学习,能够获得高精度的预测值作为BHT中的贝叶斯先验概率,进而结合具体实验中RNA-seq的结果,来获得更为准确的差异剪接推断。
在研究实践中,邢毅研究组发现,在低通量RNA-seq文库中,通过使用DNN预测值进行强化分析后,能够达到比使用传统方法分析更高的准确度,并且这种提升在越低通量的文库中越明显;即使在高通量的RNA-seq文库中,使用DNN预测仍能发现在低表达基因中的可变剪接变化。而在过去,这些低表达基因的可变剪接变化在传统分析方法中往往会被忽略。
也就是说,研究结果证明了DARTS不仅提升了基于RNA-seq方法研究可变剪接的准确性,同时也提供了在低表达基因中研究可变剪接的研究手段。
解析DARTS:
海量数据训练和新样本特征的综合
“从计算方法设计的策略和概念角度而言,此工作的最大亮点是充分利用海量公有数据如ENCODE,但模型本身又不完全依赖于这些公有数据。”马坚点评道,换言之,DARTS的整体思想是用深度神经网络从现有海量数据中找出通用的有用信息作为先验,然后用贝叶斯假设检验结合来自样本本身的RNA-seq数据信息,做可变剪接的预测,“这有效综合了海量数据的训练以及新样本的特殊性”。
马坚解释说,从模型本身的技术角度而言,DARTS有效利用了深度神经网络对异质数据特征的整合,并且整个计算方法的评测和方法都比较“明智而审慎”。他举例说,比如DARTS的深度神经网络部分结合了剪接位置附近的序列信息、进化信息、可变剪接产生的RNA二级结构信息等;同时DARTS还巧妙地利用深度神经网络预测的结果来作为贝叶斯假设检验中的先验数据,结合样本本身的RNA-seq序列信息实现了更可靠的可变剪接预测。
马坚将基因组学形容为一个“存在太多未知和容易迷失的领域”,因此他认为,有效深度学习的使用需要有强大的领域知识作为支撑。而DARTS工作恰恰体现了邢毅实验室多年以来对可变剪接机理的研究和计算方法创新的积累。“由深入的领域知识和经验作为指导,是一个有效利用不同计算模型和深度学习方法的优势实现基因组学新发现的经典工作。”
张强锋也直指“巧妙利用公开的RNA-seq大数据样本、使用深度神经网络学习得到了外显子差异剪接的贝叶斯假设检验统计模型的准确先验概率分布”是DARTS在方法上最大的特色。同时他也表示,该计算框架使用深度神经网络通过顺式序列和反式因子RBP表达丰度进行差异剪接预测的思路也值得借鉴。
此外,马坚认为论文中其他对于机器学习方法的评测同样可圈可点。例如,对常见的正负样本不均衡的问题对模型训练和评测可能带来的偏差有细致的控制。另外,该计算框架对模型中每个模块的贡献也做了详细分析。
“随着RNA-seq数据的不断积累,相信DARTS会有广泛的应用,尤其是在RNA-seq测序深度并不高的实验情况下。”马坚说,这个计算工具对进一步理解可变剪接在不同细胞状态下的调控机理有深远的意义。
-
数据
+关注
关注
8文章
7067浏览量
89129 -
深度学习
+关注
关注
73文章
5504浏览量
121246
原文标题:科学家找到深度学习基因组学应用的一顶“黑帽子”
文章出处:【微信号:AItists,微信公众号:人工智能学家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
中国联通实现30TB样本数据跨城存算分离训练
海量数据处理需要多少RAM内存
什么是协议分析仪和训练器
Llama 3 模型训练技巧
【《大语言模型应用指南》阅读体验】+ 基础知识学习
海上电磁干扰训练系统
BP神经网络最少要多少份样本
pytorch如何训练自己的数据
神经网络如何用无监督算法训练
机器学习中的数据预处理与特征工程
特征工程与数据预处理全解析:基础技术和代码示例






 工商网监
工商网监
评论