 如果把中学生的英语阅读理解选择题让AI来做,会做出什么水平?
如果把中学生的英语阅读理解选择题让AI来做,会做出什么水平?
如果把中学生的英语阅读理解选择题让AI来做,会做出什么水平?近日,上交大团队训练的“双向协同匹配网络”(DCMN)取得了74%的正确率。尽管和人类学生相比只能算马马虎虎,但对AI来说,这已经达到了目前的最高水平。
目前,在英语考试的阅读理解上,AI虽然无法击败更有能力的人类学生,但它仍然是衡量机器对语言理解能力的最佳量度之一。
近日,上海交通大学的赵海团队对AI模型进行了超过25000次英语阅读理解测试训练。训练材料和中国现行英语水平考试的阅读理解形式类似,每篇文章大约200到300个词,文后是一系列与文章内容相关的多项选择题。这些测试来自针对12至18岁中国学生的英语水平考试。
虽然这些问题有些可以在文中找到答案,但其中一半以上的题目仍需要一定程度的推理。例如,有些问题会要求从四个选项中选出文章的“最佳标题”。在训练结束后,AI参加了测试,其中包括1400次以前从未见过的考试。综合得分为74分(百分制),优于之前的所有机器测试。
上交大的AI系统可以识别与问题相关的文章相关部分,然后选出在含义上和逻辑上最相似的答案。在测试中排名第二的是腾讯的AI系统,在同一次考试中得分为72分。腾讯的AI学会了比较每个选项中包含的信息,并将不同选项间的信息差异作为提示,在文章中寻找证据。
目前最厉害的AI,阅读理解只能得个C+
尽管在测试中分数处于领先,赵海团队仍在努力提高AI系统的能力。“如果从真人学生的视角来看,我们的AI的表现也就是一般水平,最多得个C+,”他说。“对于那些想进入中国优秀大学的学生来说,他们的目标是90分。”
为了提高分数,团队将尝试修改AI,以便理解嵌入在句子结构中的信息,并为AI提供更多数据,扩大其词汇量。
如何理解人类的语言,一直是AI领域的一个主要问题,因为这种理解通常是不精确的,这个问题涉及机器难以掌握的隐含语境信息和社会线索问题。
卡内基梅隆大学的GuokunLai表示,目前我们仍不清楚AI在学习我们的语言时会遵循什么规则,“不过在阅读了大量的句子和文章之后,AI似乎能够理解我们的逻辑。”
该研究的相关论文已经发表在Arxiv上,以下是论文的主要内容:

让AI做阅读理解是一项具有挑战性的任务,需要复杂的推理过程。AI需要从一组候选答案中选择正确的答案。本文提出双重协同匹配网络(DCMN),该网络可以双向地模拟通道,问题和答案之间的关系。
与仅就问题感知或选择性文章表示进行计算的现有方法不同,DCMN能够计算文章感知问题表示和文章感知答案表示。为了证明DCMN模型的有效性,我们在大型阅读理解数据集(即RACE)上评估了模型。结果表明,该模型达到了目前AI阅读理解的最高水平。
机器阅读理解和问答已经成为评估自然语言处理和理解领域人工智能系统进展的关键应用问题。计算语言学界对机器阅读理解和问答的一般问题给予了极大的关注。
本文主要关注选择题阅读理解数据集,如RACE,该数据集中每个问题后都带有一组答案选项。大多数问题的正确答案可能不会在原文中完全复现,问题类型和范围也更加丰富和广泛,比如涉及某一段落的提要和对文章作者态度的分析。
这需要AI能够更深入地了解文章内容,并利用外部世界知识来回答这些问题。此外,与传统的阅读理解问题相比,我们需要充分考虑通过文章-问题-答案三者之间的关系,而不仅仅是问题-答案的配对。
新模型DCMN:在文章、问题、答案三者之间建立联系
DCMN模型可以将问题-答案与给定文章内容进行双向匹配,利用了NLP领域的最新突破——BERT进行上下文嵌入。在介绍BERT的原论文中提到,对应于第一输入令牌(CLS)的最终隐藏向量被用作聚合表示,然后利用分类层计算标准分类损失。
我们认为这种方法太粗糙,无法处理文章-问题-答案的三者关系组合,因为这种方法只是粗略地将文章-问题的联系作为第一序列,将问题作为第二序列,没有考虑问题和文章内容之间的关系。因此,我们提出了一种新方法来模拟文章、问题和候选答案之间的关系。
使用BERT作为编码层,分别得到文章、问题和答案选项的上下文表示。
构造匹配层以获得文章-问题-答案三者之间匹配表示,对问题在文章中对应的位置信息与特定上下文匹配的候选答案进行编码。
对从字级到序列级的匹配表示应用层次聚合方法,然后从序列级到文档级应用。
我们的模型在BERT模型的基础上,于RACE数据集上将当前最高得分提高了2.6个百分点,并使用大规模BERT模型进一步将得分提高了3个百分点。
实验及测试结果
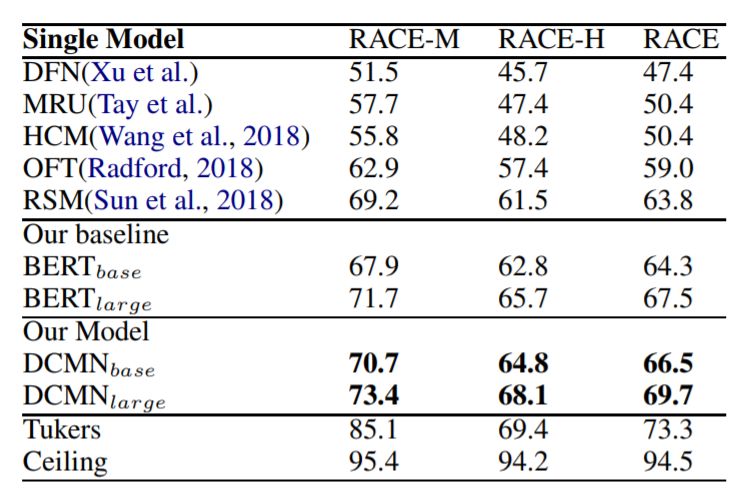
在RACE数据集上对模型进行了评估。这个数据集由两个子集组成:RACE-M和RACE-H。RACE-M来自初中考试试题,RACE-H来自高中考试试题。RACE是这两者的结合。我们将我们的模型与以下基线方法进行了比较:MRU(多范围推理),DFN(动态融合网络),HCM(等级协同匹配),OFT(OpenAI微调语言转换模型),RSM(阅读策略模型)。
我们还将我们的模型与BERT基线进行比较,并实现BERT原论文(2018)中描述的方法,该方法使用对应于第一个输入标记([CLS])的最终隐藏向量作为聚合表示,然后是分类层,最后计算标准分类损失。测试结果如上表所示。
我们可以看到BERT基线模型的性能非常接近先前的最高水平,而大型BERT模型的表现甚至超过了之前SOTA水平3.7%。但是实验结果表明,我们的DCMN模型更强大,将最高得分进一步分别提升了2.2%。
-
AI
+关注
关注
87文章
30747浏览量
268900 -
人工智能
+关注
关注
1791文章
47200浏览量
238270 -
数据集
+关注
关注
4文章
1208浏览量
24690
原文标题:最强AI挑战中国英语阅读理解:只得70多分,不如中等生
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【「大模型启示录」阅读体验】对大模型更深入的认知
【「大模型启示录」阅读体验】对本书的初印象
常见AI大模型的比较与选择指南
如何选择合适的AI云平台
AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
《AI for Science:人工智能驱动科学创新》第二章AI for Science的技术支撑学习心得
【「大模型时代的基础架构」阅读体验】+ 未知领域的感受
云知声口语评测技术应用于教育领域
【「仓颉编程快速上手」阅读体验】+初步读后感
如何用PGA309做温度的校准?
微软发布面向学生的AI生成式阅读工具“阅读教练”
计算机视觉:AI如何识别与理解图像






 工商网监
工商网监
评论