 自然语言处理顶会NAACL近日公布了本届会议的最佳论文,谷歌BERT论文获得最佳长论文
自然语言处理顶会NAACL近日公布了本届会议的最佳论文,谷歌BERT论文获得最佳长论文
自然语言处理顶会NAACL近日公布了本届会议的最佳论文,谷歌BERT论文获得最佳长论文,可谓名至实归。
自然语言处理四大顶会之一NAACL2019将于6月2日-7日在美国明尼阿波利斯市举行。
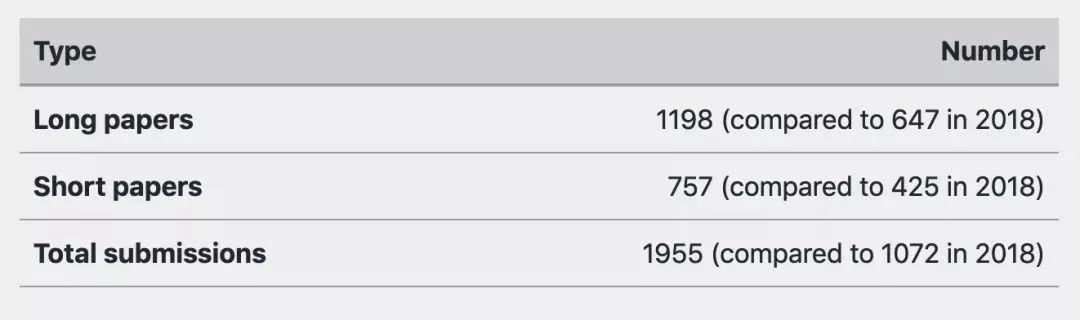
据官方统计,NAACL2019共收到1955篇论文,接收论文424篇,录取率仅为22.6%。其中长论文投稿1198篇,短论文757篇。
今天,大会揭晓了本届会议的最佳论文奖项,包括最佳专题论文、最佳可解释NLP论文、最佳长论文、最佳短论文和最佳资源论文。
其中,谷歌BERT论文获得最佳长论文奖项,可谓名至实归。
最佳长论文:谷歌BERT模型
最佳长论文(Best Long Paper)
BERT:PretrainingofDeepBidirectionalTransformersforLanguageUnderstanding
JacobDevlin,Ming-WeiChang,KentonLeeandKristinaToutanova
https://arxiv.org/abs/1810.04805
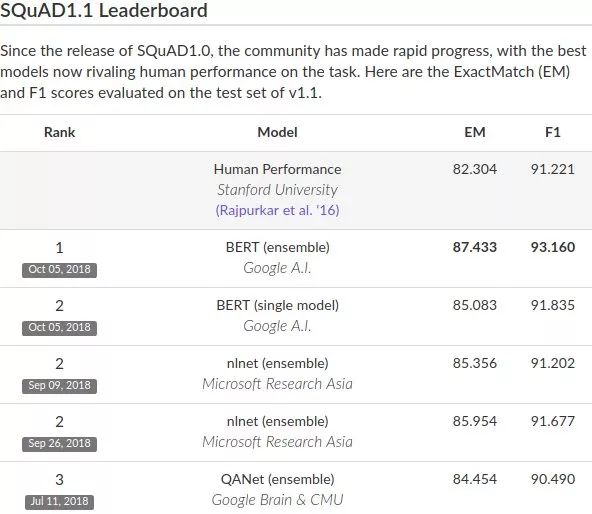
谷歌AI团队在去年10月发布的BERT模型,在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类!并且还在11种不同NLP测试中创出最佳成绩,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7%(绝对改进率5.6%)等。
自BERT模型发布以来,许多基于BERT的改进模型不断在各种NLP任务刷新成绩。毫不夸张地说,BERT模型开启了NLP的新时代!
首先来看下谷歌AI团队做的这篇论文。

BERT的新语言表示模型,它代表Transformer的双向编码器表示。与最近的其他语言表示模型不同,BERT旨在通过联合调节所有层中的上下文来预先训练深度双向表示。因此,预训练的BERT表示可以通过一个额外的输出层进行微调,适用于广泛任务的最先进模型的构建,比如问答任务和语言推理,无需针对具体任务做大幅架构修改。
论文作者认为现有的技术严重制约了预训练表示的能力。其主要局限在于标准语言模型是单向的,这使得在模型的预训练中可以使用的架构类型很有限。
在论文中,作者通过提出BERT:即Transformer的双向编码表示来改进基于架构微调的方法。
BERT提出一种新的预训练目标:遮蔽语言模型(maskedlanguagemodel,MLM),来克服上文提到的单向性局限。MLM的灵感来自Cloze任务(Taylor,1953)。MLM随机遮蔽模型输入中的一些token,目标在于仅基于遮蔽词的语境来预测其原始词汇id。
与从左到右的语言模型预训练不同,MLM目标允许表征融合左右两侧的语境,从而预训练一个深度双向Transformer。除了遮蔽语言模型之外,本文作者还引入了一个“下一句预测”(nextsentenceprediction)任务,可以和MLM共同预训练文本对的表示。
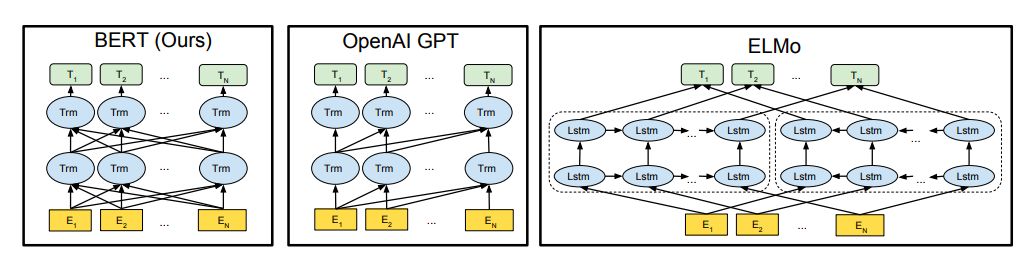
预训练模型架构的差异。BERT使用双向Transformer。OpenAIGPT使用从左到右的Transformer。ELMo使用经过独立训练的从左到右和从右到左LSTM的串联来生成下游任务的特征。三个模型中,只有BERT表示在所有层中共同依赖于左右上下文。
参考阅读:
NLP历史突破!谷歌BERT模型狂破11项纪录,全面超越人类!
最佳专题论文:减轻机器学习系统的偏见
最佳专题论文(Best Thematic Paper)
What’sinaName?ReducingBiasinBiosWithoutAccesstoProtectedAttributes
AlexeyRomanov,MariaDeArteaga,HannaWallach,JenniferChayes,ChristianBorgs,AlexandraChouldechova,SahinGeyik,KrishnaramKenthapadi,AnnaRumshiskyandAdamKalai
https://128.84.21.199/abs/1904.05233

越来越多的研究提出了减轻机器学习系统偏见的方法。这些方法通常依赖于对受保护属性(如种族、性别或年龄)的可用性。
然而,这提出了两个重要的挑战:
(1)受保护的属性可能不可用,或者使用它们可能不合法;
(2)通常需要同时考虑多个受保护的属性及其交集。
在减轻职业分类偏见的背景下,我们提出了一种方法,用于阻隔个人真实职业的预测概率与他们名字的单词嵌入之间的相关性。
这种方法利用了词嵌入中编码的社会偏见,从而无需访问受保护属性。最重要的是,这种方法只要求在训练时访问个人姓名,而不是在部署时。
我们使用了一个大规模的在线传记数据集来评估我们提出的方法的两种变体。我们发现,这两种变体同时减少了种族和性别偏见,而分类器的总体真实阳性率几乎没有降低。
最佳可解释NLP论文:用量子物理的数学框架建模人类语言
最佳可解释NLP论文 (Best Explainable NLP Paper)
CNM:AnInterpretableComplex-valuedNetworkforMatching
QiuchiLi,BenyouWangandMassimoMelucci
https://128.84.21.199/abs/1904.05298

本文试图用量子物理的数学框架对人类语言进行建模。
这个框架利用了量子物理中精心设计的数学公式,将不同的语言单元统一在一个复值向量空间中,例如,将单词作为量子态的粒子,句子作为混合系统。我们构建了一个复值网络来实现该框架的语义匹配。
由于具有良好约束的复值组件,网络允许对显式物理意义进行解释。所提出的复值匹配网络(complex-valuednetworkformatching,CNM)在两个基准问题回答(QA)数据集上具有与强大的CNN和RNN基线相当的性能。
最佳短论文:视觉模态对机器翻译的作用
最佳短论文(Best Short Paper)
Probing the Need for Visual Context in Multimodal Machine Translation
OzanCaglayan,PranavaMadhyastha,LuciaSpeciaandLoïcBarrault
https://arxiv.org/abs/1903.08678

目前关于多模态机器翻译(MMT)的研究表明,视觉模态要么是不必要的,要么仅仅是有帮助的。
我们假设这是在任务的惟一可用数据集(Multi30K)中使用的非常简单、简短和重复的语句的结果,其中源文本被呈现为上下文。
然而,在一般情况下,我们认为可以将视觉信息和文本信息结合起来进行实际的翻译。
在本文中,我们通过系统的分析探讨了视觉模态对最先进的MMT模型的贡献。我们的结果表明,在有限的文本上下文中,模型能够利用视觉输入生成更好的翻译。这与当前的观点相矛盾,即要么是因为图像特征的质量,要么是因为它们集成到模型中的方式,MMT模型忽视了视觉模态。
最佳资源论文:常识性问答的新数据集
最佳资源论文(Best Resource Paper)
CommonsenseQA:AQuestionAnsweringChallengeTargetingCommonsenseKnowledge
AlonTalmor,JonathanHerzig,NicholasLourieandJonathanBerant
https://arxiv.org/abs/1811.00937

在回答一个问题时,除了特定的上下文外,人们往往会利用他们丰富的世界知识。
最近的工作主要集中在回答一些有关文件或背景的问题,很少需要一般常识背景。
为了研究基于先验知识的问答任务,我们提出了CommonsenseQA:一个具有挑战性的用于常识性问答的新数据集。
为了获取超出关联之外的常识,我们从ConceptNet(Speeretal.,2017)中提取了与单个源概念具有相同语义关系的多个目标概念。参与者被要求撰写多项选择题,其中要提到源概念,并依次区分每个目标概念。这鼓励参与人员创建具有复杂语义的问题,这些问题通常需要先验知识。
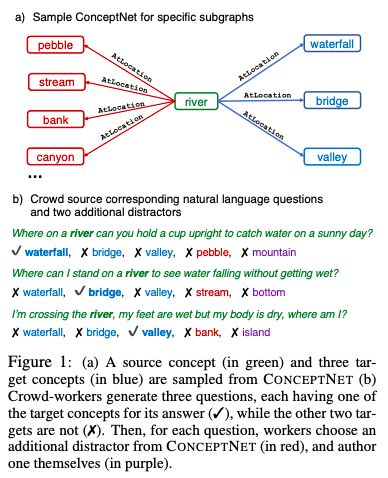
我们通过这个过程创建了12247个问题,并用大量强大的基线说明了我们任务的难度。我们最好的基线是基于BERT-large(Devlinetal.,2018)的,获得56%的准确率,远低于人类表现,即89%的准确度。
-
谷歌
+关注
关注
27文章
6151浏览量
105243 -
语言模型
+关注
关注
0文章
517浏览量
10261 -
自然语言处理
+关注
关注
1文章
618浏览量
13541
原文标题:自然语言处理顶会NAACL最佳论文出炉!谷歌BERT名至实归获最佳长论文
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
自然语言处理与机器学习的关系 自然语言处理的基本概念及步骤
ASR与自然语言处理的结合
自然语言处理与机器学习的区别
经纬恒润功能安全AI 智能体论文成功入选EMNLP 2024!

中科驭数联合处理器芯片全国重点实验室获得“CCF芯片大会最佳论文奖”
谷歌DeepMind被曝抄袭开源成果,论文还中了顶流会议

用于自然语言处理的神经网络有哪些
自然语言处理技术有哪些
自然语言处理模式的优点
自然语言处理是什么技术的一种应用
自然语言处理包括哪些内容
自然语言处理技术的原理的应用
神经网络在自然语言处理中的应用
大语言模型背后的Transformer,与CNN和RNN有何不同






 工商网监
工商网监
评论