 机器学习的特征工程是将原始的输入数据转换成特征
机器学习的特征工程是将原始的输入数据转换成特征

一、简介
机器学习的特征工程是将原始的输入数据转换成特征,以便于更好的表示潜在的问题,并有助于提高预测模型准确性的过程。
找出合适的特征是很困难且耗时的工作,它需要专家知识,而应用机器学习基本也可以理解成特征工程。但是,特征工程对机器学习模型的应用有很大影响,有句俗话叫做“数据和特征决定了机器学习模型的性能上限”。
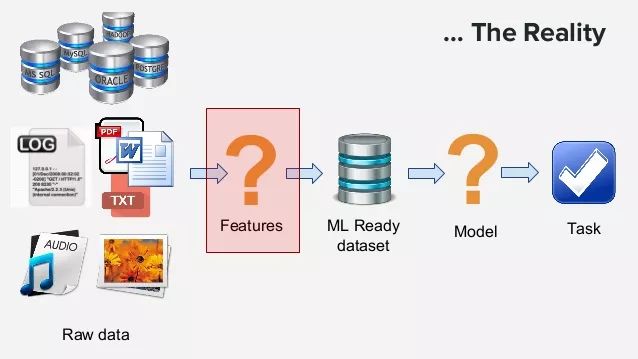
二、错误数据和缺失值
特征工程之前需要对缺失数据和错误数据进行处理。错误数据可以矫正,有的错误是格式错误,如日期的格式可能是“2018-09-19”和“20180920”这种混合的,要统一。
缺失数据的处理:
去掉所在行/列
取均值
中位数
众数
使用算法预测
三、特征的种类
机器学习的输入特征包括几种:
数值特征:包括整形、浮点型等,可以有顺序意义,或者无序数据。
分类特征:如ID、性别等。
时间特征:时间序列如月份、年份、季度、日期、小时等。
空间特征:经纬度等,可以转换成邮编,城市等。
文本特征:文档,自然语言,语句等,这里暂时不介绍处理。
四、特征工程技巧
4.1、分箱(Binning)
数据分箱(Binning)是一种数据预处理技术,用于减少轻微观察错误的影响。落入给定小间隔bin的原始数据值由代表该间隔的值(通常是中心值)代替。这是一种量化形式。 统计数据分箱是一种将多个或多或少连续值分组为较少数量的“分箱”的方法。例如,如果您有关于一组人的数据,您可能希望将他们的年龄安排到较小的年龄间隔。对于一些时间数据可以进行分箱操作,例如一天24小时可以分成早晨[5,8),上午[8,11),中午[11,14),下午[14,19),夜晚[10,22),深夜[19,24)和[24,5)。因为比如中午11点和12点其实没有很大区别,可以使用分箱技巧处理之后可以减少这些“误差”。
4.2、独热编码(One-Hot Encoding)
独热编码(One-Hot Encoding)是一种数据预处理技巧,它可以把类别数据变成长度相同的特征。例如,人的性别分成男女,每一个人的记录只有男或者女,那么我们可以创建一个维度为2的特征,如果是男,则用(1,0)表示,如果是女,则用(0,1)。即创建一个维度为类别总数的向量,把某个记录的值对应的维度记为1,其他记为0即可。对于类别不多的分类变量,可以采用独热编码。
4.3、特征哈希(Hashing Trick)
对于类别数量很多的分类变量可以采用特征哈希(Hashing Trick),特征哈希的目标就是将一个数据点转换成一个向量。利用的是哈希函数将原始数据转换成指定范围内的散列值,相比较独热模型具有很多优点,如支持在线学习,维度减小很多灯。具体参考数据特征处理之特征哈希(Feature Hashing)。
4.4、嵌套法(Embedding)
嵌套法(Embedding)是使用神经网络的方法来将原始输入数据转换成新特征,嵌入实际上是根据您想要实现的任务将您的特征投影到更高维度的空间,因此在嵌入空间中,或多或少相似的特征在它们之间具有小的距离。 这允许分类器更好地以更全面的方式学习表示。例如,word embedding就是将单个单词映射成维度是几百维甚至几千维的向量,在进行文档分类等,原本具有语义相似性的单词映射之后的向量之间的距离也比较小,进而可以帮助我们进一步进行机器学习的应用,这一点比独热模型好很多。
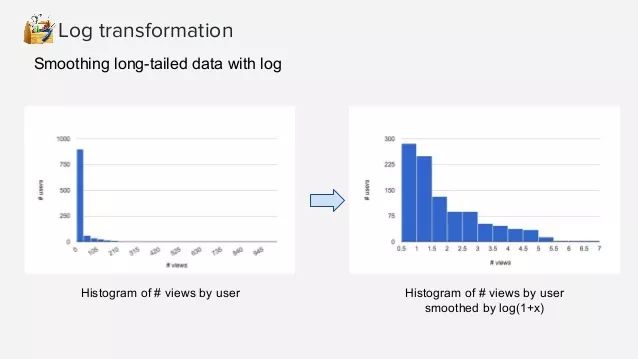
4.5、取对数(Log Transformation)
取对数就是指对数值做log转换,可以将范围很大的数值转换成范围较小的区间中。Log转换对分布的形状有很大的影响,它通常用于减少右偏度,使得最终的分布形状更加对称一些。它不能应用于零值或负值。对数刻度上的一个单位表示乘以所用对数的乘数。在某些机器学习的模型中,对特征做对数转换可以将某些连乘变成求和,更加简单,这不属于这部分范围了。
如前所述,log转换可以将范围很大的值缩小在一定范围内,这对某些异常值的处理也很有效,例如用户查看的网页数量是一个长尾分布,一个用户在短时间内查看了500个和1000个页面都可能属于异常值,其行为可能差别也没那么大,那么使用log转换也能体现这种结果。
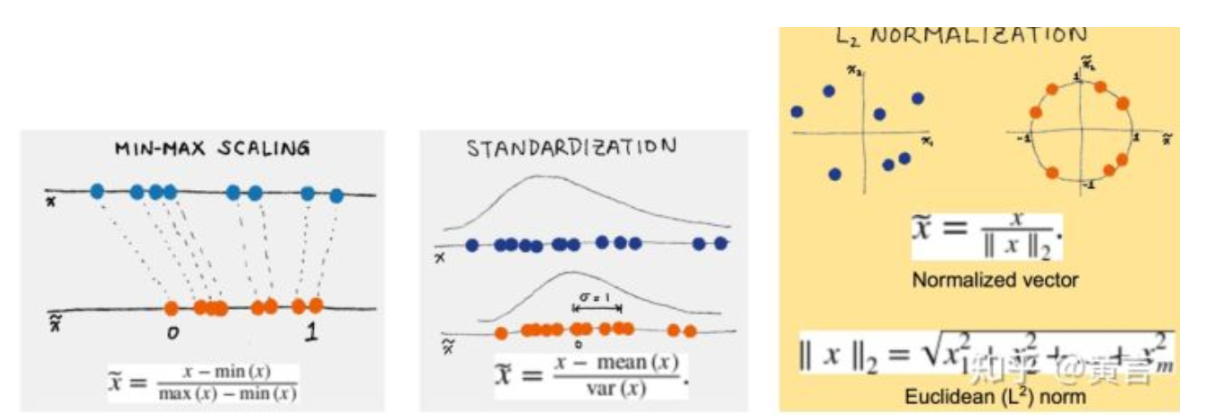
4.6、特征缩放(Scaling)
特征缩放是一种用于标准化独立变量或数据特征范围的方法。 在数据处理中,它也称为数据标准化,并且通常在数据预处理步骤期间执行。特征缩放可以将很大范围的数据限定在指定范围内。由于原始数据的值范围变化很大,在一些机器学习算法中,如果没有标准化,目标函数将无法正常工作。例如,大多数分类器按欧几里德距离计算两点之间的距离。 如果其中一个要素具有宽范围的值,则距离将受此特定要素的控制。因此,应对所有特征的范围进行归一化,以使每个特征大致与最终距离成比例。
应用特征缩放的另一个原因是梯度下降与特征缩放比没有它时收敛得快得多。
特征缩放主要包括两种:
最大最小缩放(Min-max Scaling)
标准化缩放(Standard(Z) Scaling)
4.7、标准化(Normalization)
在最简单的情况下,标准化意味着将在不同尺度上测量的值调整到概念上的共同尺度。在更复杂的情况下,标准化可以指更复杂的调整,其中意图是使调整值的整个概率分布对齐。在一般情况下,可能有意将分布与正态分布对齐。
在统计学的另一种用法中,标准化上将不同单位的数值转换到可以互相比较的范围内,避免总量大小的影响。标准化后的数据对于某些优化算法如梯度下降等也很重要。
在回归模型中加入交互项是一种非常常见的处理方式。它可以极大的拓展回归模型对变量之间的依赖的解释。具体参见回归模型中的交互项简介(Interactions in Regression)。
五、时间特征处理
几乎所有的时间特征都要处理,时间特征有序列性,其顺序有意义。这里简单列举几种处理方式。
5.1、分箱法
这是最常用的方法,如前面所述。有时候11点与12点之间差别并没有意义,可以采用上述分箱法处理。
5.2、趋势线(Treadlines)
多使用趋势量而不是总量来编码,例如使用上个星期花销,上个月花销,去年的花销,而不是总花销。两个总花销相同的客户可能在消费行为上有很大差别。
5.3、事件贴近(Closeness to major events)
假日之前几天,每个月第一个周六等。这种重要时间节点附近的值可能更有意义。
5.4、时间差(Time Difference)
上次用户交互的时间到这次用户交互时间间隔,这种时间差别意义也很大。
-
神经网络
+关注
关注
42文章
4846浏览量
108377 -
机器学习
+关注
关注
67文章
8570浏览量
137422 -
数据预处理
+关注
关注
1文章
20浏览量
3012
原文标题:机器学习:特征工程相关技术简介
文章出处:【微信号:Imgtec,微信公众号:Imagination Tech】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录

为什么特征工程如此重要?把数据转换成图像
机器学习之特征提取 VS 特征选择

特征选择和机器学习的软件缺陷跟踪系统对比



数据准备指南:10种基础特征工程方法的实战教程




评论