 如何解决爬虫被封的问题
如何解决爬虫被封的问题

如果你在爬虫过程中有遇到“您的请求太过频繁,请稍后再试”,或者说代码完全正确,可是爬虫过程中突然就访问不了,那么恭喜你,你的爬虫被对方识破了,轻则给予友好提示警告,严重的可能会对你的ip进行封禁,所以代理ip那就尤为重要了。今天我们就来谈一下代理IP,去解决爬虫被封的问题。
网上有许多代理ip,免费的、付费的。大多数公司爬虫会买这些专业版,对于普通人来说,免费的基本满足我们需要了,不过免费有一个弊端,时效性不强,不稳定,所以我们就需要对采集的ip进行一个简单的验证。
1.目标采集
本文主要针对西刺代理,这个网站很早之前用过,不过那个时候它还提供免费的api,现在api暂不提供了,我们就写个简单的爬虫去采集。
打开西刺代理,有几个页面,果断选择高匿代理。
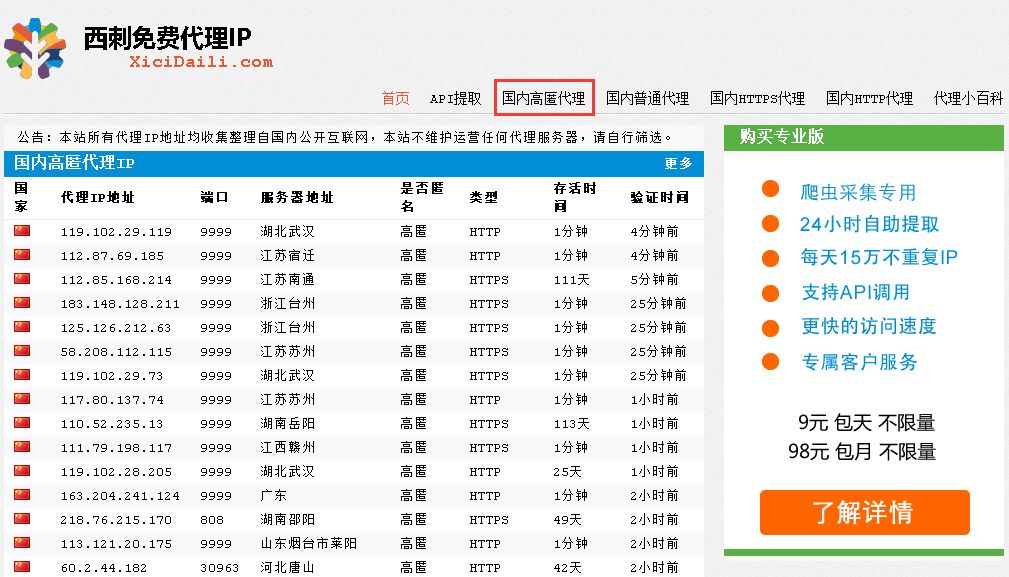
Chrome浏览器右键检查查看network,不难发现,每个ip地址都在td标签中,对于我们来说就简单许多了,初步的想法就是获取所有的ip,然后校验可用性,不可用就剔除。

定义匹配规则
importreip_compile=re.compile(r'
2.校验 这里我使用淘宝ip地址库检验可用性
目前提供的服务包括:1. 根据用户提供的IP地址,快速查询出该IP地址所在的地理信息和地理相关的信息,包括国家、省、市和运营商。2. 用户可以根据自己所在的位置和使用的IP地址更新我们的服务内容。我们的优势:1. 提供国家、省、市、县、运营商全方位信息,信息维度广,格式规范。2. 提供完善的统计分析报表,省准确度超过99.8%,市准确度超过96.8%,数据质量有保障。
2.2、接口说明
请求接口(GET):http://ip.taobao.com/service/getIpInfo.php?ip=[ip地址字符串]例:http://ip.taobao.com/service/getIpInfo2.php?ip=111.177.181.44
响应信息:(json格式的)国家 、省(自治区或直辖市)、市(县)、运营商
返回数据格式:
{"code":0,"data":{"ip":"210.75.225.254","country":"u4e2du56fd","area":"u534eu5317","region":"u5317u4eacu5e02","city":"u5317u4eacu5e02","county":"","isp":"u7535u4fe1","country_id":"86","area_id":"100000","region_id":"110000","city_id":"110000","county_id":"-1","isp_id":"100017"}}
其中code的值的含义为,0:成功,1:失败。
注意:为了保障服务正常运行,每个用户的访问频率需小于10qps。我们先通过浏览器测试一下
输入地址http://ip.taobao.com/service/getIpInfo2.php?ip=111.177.181.44

再次输入一个地址http://ip.taobao.com/service/getIpInfo2.php?ip=112.85.168.98
代码操作
importrequestscheck_api="http://ip.taobao.com/service/getIpInfo2.php?ip="api=check_api+iptry:response=requests.get(url=api,headers=api_headers,timeout=2)print("ip:%s 可用"%ip)exceptExceptionase:print("此ip %s 已失效:%s"%(ip,e))
3.代码
代码中加入了异常处理,其实自己手写的demo写不写异常处理都可以,但是为了方便其他人调试,建议在可能出现异常的地方加入异常处理。
importrequestsimportreimportrandomfrombs4importBeautifulSoupua_list=[ "Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/72.0.3626.109Safari/537.36", "Mozilla/5.0(X11;Linuxx86_64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/62.0.3202.75Safari/537.36", "Mozilla/5.0(Macintosh;IntelMacOSX10_13_6)AppleWebKit/537.36(KHTML,likeGecko)Chrome/72.0.3626.119Safari/537.36", "Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/45.0.2454.101Safari/537.36" ]defip_parse_xici(page):""":param page:采集的页数:return:""" ip_list=[] forpginrange(1,int(page)): url='http://www.xicidaili.com/nn/'+str(pg) user_agent=random.choice(ua_list) my_headers={ 'Accept':'text/html,application/xhtml+xml,application/xml;', 'Accept-Encoding':'gzip,deflate,sdch', 'Accept-Language':'zh-CN,zh;q=0.8', 'Referer':'http://www.xicidaili.com/nn', 'User-Agent':user_agent } try: r=requests.get(url,headers=my_headers) soup=BeautifulSoup(r.text,'html.parser') exceptrequests.exceptions.ConnectionError: print('ConnectionError') else: data=soup.find_all('td') #定义IP和端口Pattern规则 ip_compile=re.compile(r'
运行代码:
日志
4.为你的爬虫加入代理ip
建议大家可以把采集的ip存入数据库,这样每次爬虫的时候直接调用即可,顺便提一下代码中怎么加入代理ip。
importrequestsurl='www.baidu.com'headers={ "User-Agent":"Mozilla/5.0(Macintosh; IntelMacOSX10_13_6)AppleWebKit/537.36(KHTML, likeGecko)Chrome/72.0.3626.119Safari/537.36",}proxies={ "http":"http://111.177.181.44:9999", #"https":"https://111.177.181.44:9999", } res=requests.get(url=url,headers=headers,proxies=proxies)
好了,妈妈再也不担心我爬虫被封了,代码可从文中复制粘贴。
-
IP
+关注
关注
5文章
1885浏览量
156829 -
代码
+关注
关注
30文章
4977浏览量
74420 -
爬虫
+关注
关注
0文章
87浏览量
8183
原文标题:听说你的爬虫被封了?
文章出处:【微信号:atleadai,微信公众号:LeadAI OpenLab】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Python数据爬虫学习内容
应对反爬虫的策略
如何提高爬虫采集效率
网络爬虫之关于爬虫http代理的常见使用方式
网络爬虫nodejs爬虫代理配置
Golang爬虫语言接入代理?
0基础入门Python爬虫实战课
python网络爬虫概述
python爬虫入门教程之python爬虫视频教程分布式爬虫打造搜索引擎
爬虫是如何实现数据的获取爬虫程序如何实现



评论