 何恺明团队最新研究:提出一个端到端的3D目标检测器VoteNet
何恺明团队最新研究:提出一个端到端的3D目标检测器VoteNet
FAIR何恺明等人团队提出3D目标检测新框架VoteNet,直接处理原始数据,不依赖任何2D检测器。该模型设计简单,模型紧凑,效率高,在两大真实3D扫描数据集上实现了最先进的3D检测精度。
当前的3D目标检测方法受2D检测器的影响很大。为了利用2D检测器的架构,它们通常将3D点云转换为规则的网格,或依赖于在2D图像中检测来提取3D框。很少有人尝试直接检测点云中的物体。
近日,Facebook AI实验室(FAIR)和斯坦福大学的Charles R. Qi,Or Litany,何恺明,Leonidas J. Guibas等人发表最新论文,提出一个端到端的3D目标检测器VoteNet。
论文地址:
https://arxiv.org/pdf/1904.09664.pdf
在这篇论文中,研究人员回归第一原则,为点云数据构建了一个尽可能通用的3D检测pipeline。
然而,由于数据的稀疏性,直接从场景点预测边界框参数时面临一个主要挑战:一个3D物体的质心可能远离任何表面点,因此很难用一个步骤准确地回归。
为了解决这一问题,研究人员提出VoteNet,这是一个基于深度点集网络和霍夫投票的端到端3D目标检测网络。
该模型设计简单,模型尺寸紧凑,而且效率高,在ScanNet和SUN RGB-D两大真实3D扫描数据集上实现了最先进的3D检测精度。值得注意的是,VoteNet优于以前的方法,而且不依赖彩色图像,使用纯几何信息。
VoteNet点云框架:直接处理原始数据,不依赖2D检测器
3D目标检测的目的是对3D场景中的对象进行定位和识别。更具体地说,在这项工作中,我们的目标是估计定向的3D边界框以及点云对象的语义类。
与2D图像相比,3D点云具有精确的几何形状和对光照变化的鲁棒性。但是,点云是不规则的。因此,典型的CNN不太适合直接处理点云数据。
为了避免处理不规则点云,目前的3D检测方法在很多方面都严重依赖基于2D的检测器。例如,将Faster/Mask R-CNN等2D检测框架扩展到3D,或者将点云转换为常规的2D鸟瞰图像,然后应用2D检测器来定位对象。然而,这会牺牲几何细节,而这些细节在杂乱的室内环境中可能是至关重要。
在这项工作中,我们提出一个直接处理原始数据、不依赖任何2D检测器的点云3D检测框架。这个检测网络称为VoteNet,是点云3D深度学习模型的最新进展,并受到用于对象检测的广义霍夫投票过程的启发。
图1:基于深度霍夫投票模型的点云3D目标检测
我们利用了PointNet++,这是一个用于点云学习的分层深度网络,以减少将点云转换为规则结构的需要。通过直接处理点云,不仅避免了量化过程中信息的丢失,而且通过仅对感测点进行计算,利用了点云的稀疏性。
虽然PointNet++在对象分类和语义分割方面都很成功,但很少有研究使用这种架构来检测点云中的3D对象。
一个简单的解决方案是遵循2D检测器的常规做法,并执行dense object proposal,即直接从感测点提出3D边界框。然而,点云的固有稀疏性使得这种方法不适宜。
在图像中,通常在目标中心附近存在一个像素,但在点云中却不是这样。由于深度传感器仅捕获物体的表面,因此3D物体的中心很可能在远离任何点的空白空间中。因此,基于点的网络很难在目标中心附近聚集场景上下文。简单地增加感知域并不能解决这个问题,因为当网络捕获更大的上下文时,它也会导致包含更多的附近的对象和杂物。
为此,我们提出赋予点云深度网络一种类似于经典霍夫投票(Hough voting)的投票机制。通过投票,我们基本上生成了靠近对象中心的新的点,这些点可以进行分组和聚合,以生成box proposals。
与传统的多独立模块、难以联合优化的霍夫投票相比,VoteNet是端到端优化的。具体来说,在通过主干点云网络传递输入点云之后,我们对一组种子点进行采样,并根据它们的特征生成投票。投票的目标是到达目标中心。因此,投票集群出现在目标中心附近,然后可以通过一个学习模块进行聚合,生成box proposals。其结果是一个强大的3D物体检测器,它是纯几何的,可以直接应用于点云。
我们在两个具有挑战性的3D目标检测数据集上评估了我们的方法:SUN RGB-D数据集和ScanNet数据集。在这两个数据集上,仅使用几何信息的VoteNet明显优于使用RGB和几何甚至多视图RGB图像的现有技术。我们的研究表明,投票方案支持更有效的上下文聚合,并验证了当目标中心远离目标表面时,VoteNet能够提供最大的改进。
综上所述,我们工作的贡献如下:
在通过端到端可微架构进行深度学习的背景下,重新制定了霍夫投票,我们称之为VoteNet。
在SUN RGB-D和ScanNet两个数据集上实现了最先进的3D目标检测性能。
深入分析了投票在点云3D目标检测中的重要性。
深度霍夫投票(Deep Hough Voting)
传统的霍夫投票2D检测器包括离线和在线两个步骤。
首先,给定一组带有带注释的对象边界框的图像集,使用存储在图像补丁(或它们的特性)和它们到相应目标中心的偏移量之间的映射构建一个codebook。
在推理时,从图像中选择兴趣点以提取周围的补丁(patch)。然后将这些补丁与codebook中的补丁进行比较,以检索偏移量并计算投票。由于对象补丁倾向于一致投票,因此集群将在目标中心附近形成。最后,通过将集群投票追溯到它们生成的补丁来检索对象边界。
我们确定这种技术非常适合我们感兴趣的问题,有两个方面:
首先,投票是针对稀疏集合设计的,因此很自然地适合于点云。
其次,它基于自底向上的原理,积累少量的局部信息以形成可靠的检测。
然而,传统的霍夫投票是由多个独立的模块组成的,将其集成到点云网络仍然是一个开放的研究课题。为此,我们建议对不同的pipeline部分进行以下调整:
兴趣点(Interest points)由深度神经网络来描述和选择,而不是依赖手工制作的特性。
投票(Vote)生成是通过网络学习的,而不是使用代码本。利用更大的感受野,可以使投票减少模糊,从而更有效。此外,还可以使用特征向量对投票位置进行增强,从而实现更好的聚合。
投票聚合(Vote aggregation)是通过可训练参数的点云处理层实现的。利用投票功能,网络可以过滤掉低质量的选票,并生成改进的proposals。
Object proposals的形式是:位置、维度、方向,甚至语义类,都可以直接从聚合特征生成,从而减少了追溯投票起源的需要。
接下来,我们将描述如何将上述所有组件组合成一个名为VoteNet的端到端网络。
VoteNet 的架构
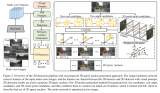
图2描述了我们提出的端到端检测网络VoteNet的架构。整个网络可以分为两部分:一部分处理现有的点来生成投票;另一部分处理虚拟点——投票——来提议和分类对象。
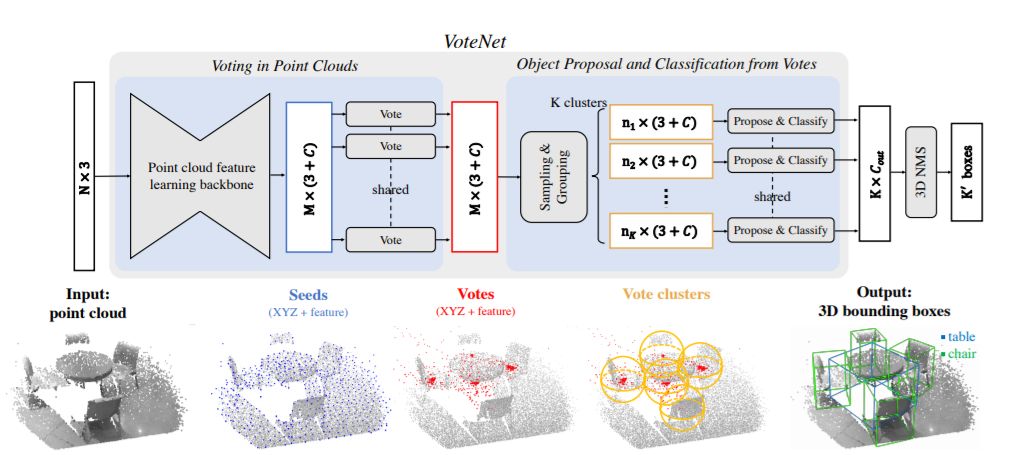
图2:用于点云中3D目标检测的VoteNet架构
给定一个包含N个点和XYZ坐标的输入点云,一个主干网络(使用PointNet++实现),对这些点进行采样和学习深度特性,并输出M个点的子集。这些点的子集被视为种子点。每个种子通过投票模块独立地生成一个投票。然后将投票分组为集群,并由proposal模块处理,生成最终的proposal。
实验和结果
我们首先在两个大型3D室内目标检测基准上,将我们基于霍夫投票的检测器与之前最先进的方法进行比较。
然后,我们提供了分析实验来了解投票的重要性、不同的投票聚合方法的效果,并展示了我们的方法在紧凑性和效率方面的优势。
最后,我们展示了我们的检测器的定性结果。论文附录中提供了更多的分析和可视化。
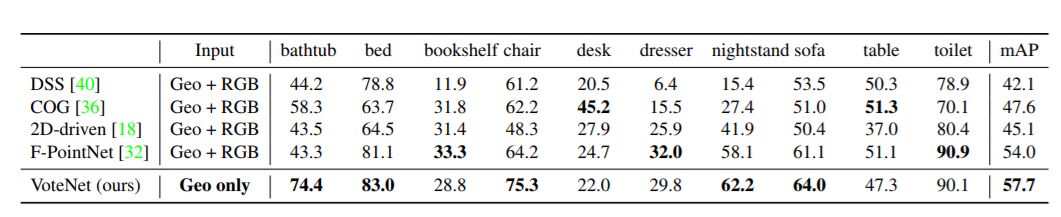
表1:SUN RGB-D val数据集上的3D目标检测结果
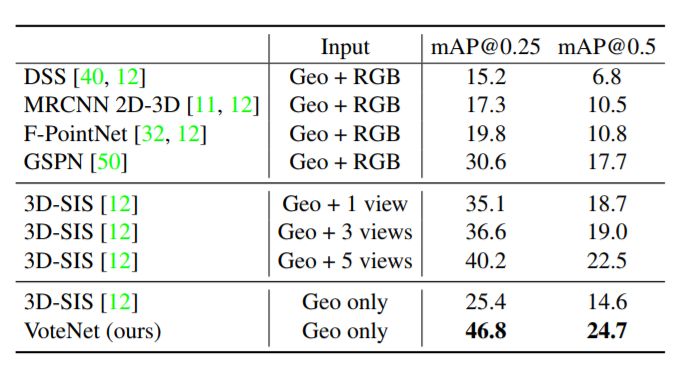
表2:ScanNetV2 val数据集上的3D目标检测结果
结果如表1和表2所示。在SUN RGB-D和ScanNet两个数据集中,VoteNet的性能都优于所有先前的方法,分别增加了3.7和6.5 mAP。
表1表明,当类别是训练样本最多的“椅子”时,我们的方法比以前的最优方法提高11 AP。
表2表明,仅使用几何输入时,我们的方法显著优于基于3D CNN的3D-SIS方法,超过了20 AP。
分析实验:投票好还是不投票好呢?
投票好还是不投票好呢?
我们采用了一个简单的基线网络,称之为BoxNet,它直接从采样的场景点提出检测框,而不需要投票。
BoxNet具有与VoteNet相同的主干,但它不采用投票机制,而是直接从种子点生成框。
表3显示,在SUN RGB-D和ScanNet上,相比BoxNet,投票机制的网络性能分别提高了7 mAP和~5 mAP。

表3:VoteNet和no-vote基线的比较
那么,投票在哪些方面有帮助呢?我们认为,由于在稀疏的3D点云中,现有的场景点往往远离目标中心点,直接提出的方案可能置信度较低或不准确。相反,投票让这些较低的置信点更接近,并允许通过聚合来强化它们的假设。
在图3中,我们在一个典型的ScanNetV2场景中演示了这种现象。从图中可以看出,与BoxNet(图左)相比,VoteNet(图右)提供了更广泛的“好”种子点的覆盖范围,显示了投票带来的稳健性。
图3:投票有助于增加检测上下文,从而增加了准确检测的可能性。
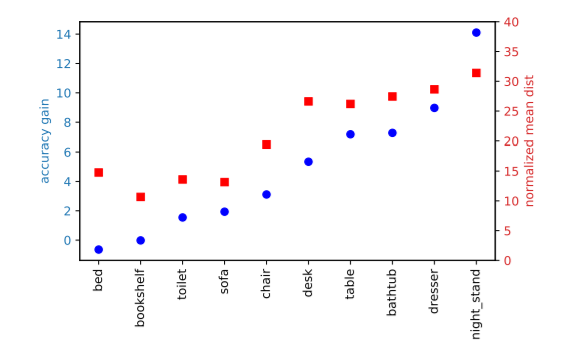
图4:当目标点远离目标中心的情况下,投票更有帮助
定性结果和讨论
图6和图7分别展示了ScanNet和SUN RGB-D场景中VoteNet检测结果的几个代表性例子。
可以看出,场景是非常多样化的,并提出了多种挑战,包括杂乱,偏见,扫描的伪像等。尽管有这些挑战,我们的网络仍显示出相当强大的结果。
例如,图6展示了如何在顶部场景中正确地检测到绝大多数椅子。我们的方法能够很好地区分左下角场景中连起来的沙发椅和沙发;并预测了右下角那张不完整的、杂乱无章的桌子的完整边界框。
图6:ScanNetV2中3D目标检测的定性结果。左:VoteNet的结果,右: ground-truth
图7:SUN RGB-D中3D目标检测的定性结果。(从左到右):场景的图像,VoteNet的3D对象检测,以及ground-truth注释
结论
在这项工作中,我们介绍了VoteNet:一个简单但强大的3D对象检测模型,受到霍夫投票的启发。
该网络学习直接从点云向目标质心投票,并学会通过它们的特性和局部几何信息来聚合投票,以生成高质量的object proposals。
该模型仅使用3D点云,与之前使用深度和彩色图像的方法相比,有了显著的改进。
在未来的工作中,我们将探索如何将RGB图像纳入这个检测框架,并在下游应用(如3D实例分割)汇总利用我们的检测器。我们相信霍夫投票和深度学习的协同作用可以推广到更多的应用领域,如6D姿态估计、基于模板的检测等,并期待在这方面看到更多的研究。
-
检测器
+关注
关注
1文章
860浏览量
47659 -
数据集
+关注
关注
4文章
1205浏览量
24656 -
深度学习
+关注
关注
73文章
5495浏览量
121044
原文标题:何恺明团队最新研究:3D目标检测新框架VoteNet,两大数据集刷新最高精度
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于ToF的3D活体检测算法研究
谷歌开发pipeline,在移动设备上可实时计算3D目标检测
自动驾驶检测器可同时实现3D检测精读和速度的提升
华为发布“5G+8K”3D VR端到端解决方案
洲明以裸眼3D技术助力数字经济
如何利用车载环视相机采集到的图像实现精准的3D目标检测
基于BEV的视觉3D目标检测器

CCV 2023 | SparseBEV:高性能、全稀疏的纯视觉3D目标检测器


Sparse4D-v3:稀疏感知的性能优化及端到端拓展
Nullmax提出多相机3D目标检测新方法QAF2D





 工商网监
工商网监
评论