 OpenAI新模型Sparse Transformer,预测长度超过去30倍
OpenAI新模型Sparse Transformer,预测长度超过去30倍
OpenAI提出新的神经网络模型“稀疏Transformer”,能够预测文本、图像和声音等序列的后续内容,该模型是对注意力机制的一个改进,预测长度达到之前最佳水平的30倍。
目前人工智能研究的一大挑战是对复杂数据(如图像,视频或声音)中的大范围微妙的相互依赖性进行建模。稀疏Transformer降低了传统注意力机制模型的计算复杂度,将其直接应用于不同的数据类型中。以前,在这些数据上使用的模型是针对某个专门领域设计的,难以扩展到超过几千个元素的序列规模上应用。
此次OpenAI提出的模型可以使用数百个层对数万个元素的序列进行建模,在多个域中实现最先进的性能。稀疏Transformer能够帮助我们构建具有更强的理解世界能力的AI系统。
深度注意力机制
在稀疏Transformer中,每个输出元素都与每个输入元素相连,它们之间的权重是根据环境动态计算的,这个过程称为注意力。虽然这样会让模型比固定连接模式的模型更加灵活,但在实践中需要为每个层和注意力头N×N注意力矩阵,面对元素数量众多的数据类型时会消耗大量的内存,比如图像或原始音频数据。
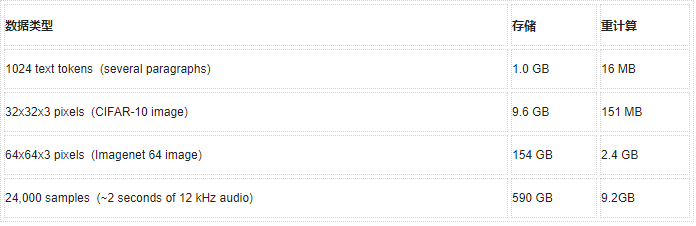
当矩阵存储在内存中或在后向传递期间重新计算时,深度Transformer的内存消耗情况(64层、4个注意力头)。作为参考,用于深度学习的标准GPU通常配备12-32GB的内存
减少内存消耗一种方法是在反向传播期间从检查点重新计算注意力矩阵,这是深度学习中的一种成熟技术,以增加计算量为代价来减少内存使用。在计算Transformer的注意力矩阵时,意味着最大的内存成本与层数无关,这使我们能够以比以前更大的深度训练神经网络。
实际上,我们发现深度达128层的Transformer在常用数据集基准任务(如CIFAR-10)上的表现优于较浅层的网络。
为了更深入地训练这些模型,我们对Transformer中的操作顺序进行了几次调整,并修改了初始方案。
稀疏注意力机制:显著降低计算复杂度
然而,即使是计算单个注意力矩阵,对于非常大的输入也是不切实际。因此我们使用稀疏注意力模式,即每个输出位置仅计算来自输入位置子集的权重。当子集相对于整个输入集较小时,即使对于非常长的序列,所得到的注意力计算也是容易处理的,算法复杂度为O(N *sqrt {N}),而不是O(N^2)。
为了评估该方法的可行性,我们首先将深度Transformer在图像上的学习注意模式进行可视化,发现许多模型表现出可解释和结构化的稀疏模式。下面的每个图像显示给定的注意头处理哪些输入像素(以白色突出显示)以便预测图像中的下一个值。
当输入部分聚焦在小的子集上并显示出高度的规则性时,该层就是易于稀疏化的。下图为CIFAR-10图像上的128层模型示例。
左图为19层,右图为20层
学习后的128层CIFAR-10网络的多个层的注意力模式(白色高亮部分)。这些层学会将注意力分散在两个维度上。其中第19层总结了每一行的信息,第20层则按列聚合这些信息,从而能够对全面注意力操作进行有效分解。
左图为第6层,右图为第36层
一些层学会了访问位置存储器,无论输入数据或时间步长如何,通常都会访问类似的位置(第6层)。还有的层学习了高度依赖数据的访问模式(第36层)。
虽然许多图层显示出了稀疏结构,某些层还清晰地显示出在整个图像上延伸的动态注意力。为了让网络保持学习这些模式的能力,我们进行了注意力矩阵的二维分解,网络可以通过两个稀疏注意力步骤来关注所有位置。
(左)普通transformer,(中)范围注意力,(右)固定注意力
第一个版本,大范围注意力,大致相当于参与其行和列的每个位置,并且类似于上面的网络学习的注意力模式。(注意,列注意力可以等效地表示成转置矩阵的行注意力)。第二个版本是固定注意力,注意固定列和最新列元素之后的元素,我们发现这种模式在数据不适合二维结构(如文本)时很有用。
实验结果:创造多个数据集上的新纪录
稀疏Transformer在CIFAR-10,Enwik8和Imagenet 64上创造了密度估计的最新记录。如下表所示:
| CIFAR-10 | BITS PER DIM |
| PixelCNN++ (Oord et al, 2016) | 2.92 |
| Image Transformer (Parmar et. al, 2018) | 2.90 |
| PixelSNAIL (Chen et al., 2017) | 2.85 |
| Sparse Transformer 59M (256W, 128L, 2H) | 2.80 |
| ENWIK8 | BITS PER BYTE |
| Deeper Self-Attention (Al-Rfou et al, 2018) | 1.06 |
| Transformer-XL 88M (Dai et al., 2018) | 1.03 |
| Transformer-XL 277M (Dai et al., 2018) | 0.99 |
| Sparse Transformer 95M (512W, 30L, 8H) | 0.99 |
| IMAGENET 64X64 | BITS PER DIM |
| PixelCNN++ (Oord et al, 2016) | 3.57 |
| Parallel Multiscale (Reed et al, 2017) | 3.7 |
| SPN 150M (Menick & Kalchbrenner, 2018) | 3.52 |
| Sparse Transformer 152M (512W, 48L, 16H) | 3.44 |
在一系列数据集上的密度建模表现,M为网络中使用的参数数量(百万),W为网络宽度,L为层数,H为注意力头数量。
我们还发现,除了速度明显更快之外,稀疏注意力模型的损失也要低于完全注意力模型。这可能表明我们的稀疏模式存在有用的归纳偏差,或是密集关注的潜在优化问题。
使用稀疏注意力的Transformer似乎有一个全局结构的概念,可以通过查看图像完成来定性评估。我们对64×64 ImageNet上训练的模型进行了可视化,如下图所示:
Prompt
Completions
Ground truth
我们还利用未调整的softmax temperature 1.0下生成了完全无条件的样图。这些模型使用最大似然目标进行训练,众所周知,这类训练的目标是覆盖所有数据模式(包括可能不存在的数据),而不是增加小部分数据的保真度。从这些具有未调整温度的模型中生成样图,可以让我们看到模型认为存在于真实世界中图像的完整分布。结果,一些样本看起来很奇怪。
模型采样
真实数据
生成原始音频波形
稀疏Transformer也可以通过简单地改变位置嵌入,自适应地生成原始音频。随着深度学习扩展到新型数据类型,可以使用这类网络作为确定归纳偏差的有用工具。
该模型在原始古典音乐剪辑上进行训练,并使用稀疏注意力生成长度为65000的序列,相当于大约5秒的原始音频,我们在每个片段中将几个样本连接在了一起。
关于代码发布和开源
通常,实现稀疏注意力将涉及在数据块中将查询和关键矩阵单独“切片”,因此为了简化实验,我们实现了一组块稀疏内核,这些内核可以在GPU上高效执行这些操作。我们开源了这些内核,并在Github上提供示例稀疏注意函数。
未来方向和局限
我们提出的稀疏注意力模式只是长序列高效建模方向的初步模式。我们认为,探索稀疏性的不同模式和组合的用途不仅于此,学习稀疏模式对于下一代神经网络体系结构来说是一个很有前途的方向。
即使经过改进,自回归序列生成对于非常高分辨率的图像或视频来说仍然是不切实际的。不过,我们提出的优化注意力操作可能是一次有益的探索,可以和其他(如多尺度方法)方法相结合来对高维数据进行建模。
-
神经网络
+关注
关注
42文章
4787浏览量
101444 -
图像
+关注
关注
2文章
1091浏览量
40647 -
模型
+关注
关注
1文章
3400浏览量
49430
原文标题:OpenAI提出Sparse Transformer,文本、图像、声音都能预测,序列长度提高30倍
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何计算transformer模型的参数量
【大语言模型:原理与工程实践】大语言模型的基础技术
OpenAI 深夜抛出王炸 “ChatGPT- 4o”, “她” 来了
你了解在单GPU上就可以运行的Transformer模型吗
超大Transformer语言模型的分布式训练框架

transformer模型详解:Transformer 模型的压缩方法
OpenAI发布文生视频大模型Sora、英伟达市值超谷歌
7万张H100打造的OpenAI文生视频Sora功能原理详解|Sora注册全攻略





 工商网监
工商网监
评论