 读、写、擦除是SSD对NAND的三大基本操作
读、写、擦除是SSD对NAND的三大基本操作
读、写、擦除是SSD对NAND的三大基本操作,但是针对NAND自身的特性和多样化的I/O模型,SSD怎么读、写、擦除是门高级艺术,也由此衍生了很多技术。
比如垃圾回收(GC),一个优质的GC明白在什么时候,挑选哪些Block,将上面的数据搬到哪去。
GC的基本原理
(如上图)左侧两个Block中的有效数据被搬移/整合到一个新的Block,然后这两个Block将被擦除,形成两个可以写入数据的新Block。
关于GC的研究,可以看Memblaze金一同学的这个文章。
有个问题,GC怎么才能知道垃圾是垃圾呢?讨论这个问题需要先回到数据存储的过程,开始是这样的。
当有数据删除之后,SSD并不能及时的知道谁是脏数据。形成了这样的局面
只有操作系统往标注DEL的位置上写数据时,盘才知道这是垃圾。
不然这些数据将一直被GC认为是有效数据搬移。为了更高效的执行GC,让操作系统和文件系统高效的和SSD主控交流删除文件的信息。
就出现了TRIM。
A trim command (known as TRIM in the ATA command set, and UNMAP in the SCSI command set) allows an operating system to inform a solid-state drive (SSD) which blocks of data are no longer considered in use and can be wiped internally.——Wikipediahttps://en.wikipedia.org/wiki/Trim_(computing)
维基百科给的这段介绍,在NVMe SSD上解释就是,TRIM让操作系统通过Trim命令(NVMe协议中有定义)告诉SSD哪些地址上的数据可以擦除,从而提升垃圾回收的效率。
Memblaze就是这么干的,
我们总结了TRIM的三大价值:
降低写放大
提升写性能
提高设备寿命
对于NVMe来说,Trim是让GC长了一对翅膀。说着简单,但是要通过Trim达到降低写放大的目标而不影响设备性能,其中NAND无效块的擦写时机、Tirm和其他一系列SSD核心算法的配合非常有讲究。
TRIM实现难在哪这里就不详细讨论了,有兴趣的可以看Ron写的文章《SSD Trim 详解》
NVMe Spec对TRIM命令有详细的规定,所以使NVMe Cli就可以对TRIM功能进行验证
接下来就结合NVMe Spec的规定,发出我们的一条TRIM命令,然后做个验证。
1
准备设备和环境
使用Memblaze官网Pblaze5 910/916系列产品中的4T U.2NVMe进行验证测试。
nvme list的信息如下 firmware version:001008R0
写入数据:从NVMe 10GiB的位置往后写10G的数据,数据pattern是0x12345678
[root@localhost~]#fio--thread--direct=1--allow_file_creat=0--ioengine=libaio--rw=write--bs=128k--iodepth=128--numjobs=1--name=nvme0n1--filename=/dev/nvme0n1--offset=10g--size=10g--verify=pattern--do_verify=0--verify_pattern=0x12345678nvme0n1:(g=0):rw=write,bs=(R)128KiB-128KiB,(W)128KiB-128KiB,(T)128KiB-128KiB,ioengine=libaio,iodepth=128fio-3.12Starting1threadJobs:1(f=1):[W(1)][-.-%][w=3165MiB/s][w=25.3kIOPS][eta00m:00s]nvme0n1:(groupid=0,jobs=1):err=0:pid=4787:MonMar415:59:352019write:IOPS=25.2k,BW=3156MiB/s(3309MB/s)(10.0GiB/3245msec)slat(nsec):min=3204,max=81924,avg=9364.20,stdev=2437.54clat(usec):min=1177,max=17333,avg=5058.82,stdev=387.21lat(usec):min=1187,max=17347,avg=5068.25,stdev=387.16clatpercentiles(usec):|1.00th=[4555],5.00th=[5014],10.00th=[5014],20.00th=[5014],|30.00th=[5014],40.00th=[5014],50.00th=[5080],60.00th=[5080],|70.00th=[5080],80.00th=[5080],90.00th=[5080],95.00th=[5080],|99.00th=[5145],99.50th=[6063],99.90th=[11207],99.95th=[13042],|99.99th=[16909]bw(MiB/s):min=3145,max=3166,per=100.00%,avg=3157.17,stdev=7.59,samples=6iops:min=25160,max=25334,avg=25257.33,stdev=60.68,samples=6lat(msec):2=0.11%,4=0.48%,10=99.30%,20=0.11%cpu:usr=3.73%,sys=25.09%,ctx=74895,majf=0,minf=13IOdepths:1=0.1%,2=0.1%,4=0.1%,8=0.1%,16=0.1%,32=0.1%,>=64=99.9%submit:0=0.0%,4=100.0%,8=0.0%,16=0.0%,32=0.0%,64=0.0%,>=64=0.0%complete:0=0.0%,4=100.0%,8=0.0%,16=0.0%,32=0.0%,64=0.0%,>=64=0.1%issuedrwts:total=0,81920,0,0short=0,0,0,0dropped=0,0,0,0latency:target=0,window=0,percentile=100.00%,depth=128Runstatusgroup0(alljobs):WRITE:bw=3156MiB/s(3309MB/s),3156MiB/s-3156MiB/s(3309MB/s-3309MB/s),io=10.0GiB(10.7GB),run=3245-3245msecDiskstats(read/write):nvme0n1:ios=62/79409,merge=0/0,ticks=1/401029,in_queue=401403,util=96.86%[root@localhost~]#
2
依据NVMe Spec准备测试文件和命令
使用nvmecli将这10G的数据trim掉,利用强大的strace命令跟踪一下command的耗时,粗略的计算下Trim的速度。
首先需要按照NVMe Spec协议中的Dataset Manager设置(如下图),创建一个4096byte的二进制文件。一个range最多trim32bit(0xffffffff*512byte 大约2047GiB)的LBA。
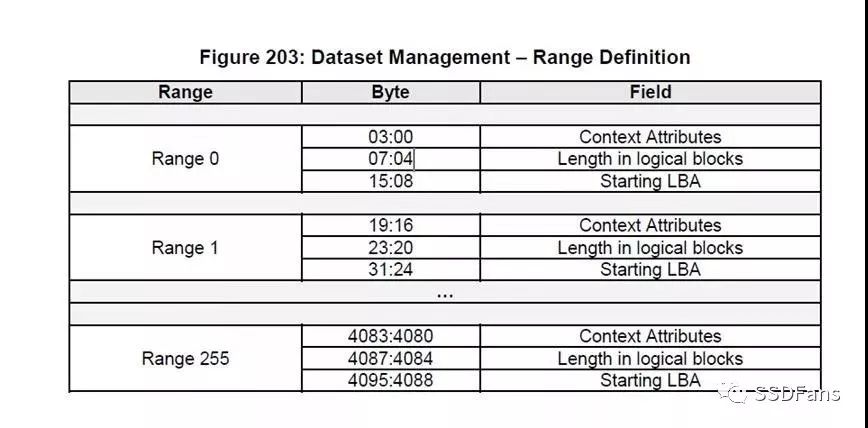
Length in logical blocks和Starting LBA的计算
10G数据按照512byte的format格式得出是:
10*1024*1024*1024/512=20971520个(LBA)
Fio中offset=10g,因此start LBA也是 :
10*1024*1024*1024/512=20971520
利用python创建二进制文件代码如下(简单的写个)
importarraybuf=array.array("B",[0x00]*4096)defsetValue(buf,offset,num,value):#Commonfunctiontosetunsignedintegervaluewithinthegivenrange#offset&numareinbytesforthisfunctionseries.ifnum==1:buf[offset]=valueelse:foriinxrange(num):buf[offset+i]=(value>>(8*i))&0xffreturnbufdefwriteBinaryFile(buf,filepath):withopen(filepath,"wb")asf:buf.tofile(f)#Length in logical blocks :offset=4 num=4 value=20971520buf=setValue(buf,4,4,20971520)#StartingLBAoffset=8num=8value=20971520buf=setValue(buf,8,8,20971520)writeBinaryFile(buf,“/root/trim.bin”)
下面是NVMe Spec里TRIM命令的规范,使用nvmecli 发送NVMe command需要照着填写
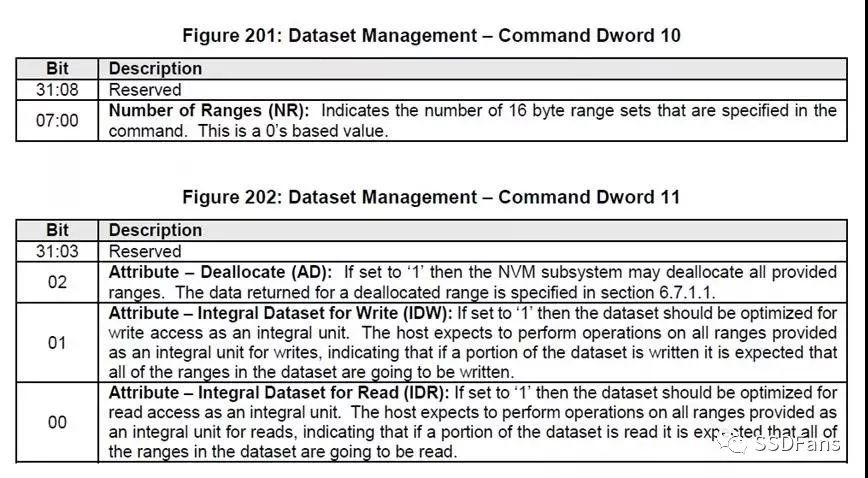
Dword11 :二进制:0b 0100=0x04
3
准备工作做足了,接下来就是发!
发TRIM时候,在命令前加上strace –ttt,可以粗略的计算TRIM的速度。
[root@localhost~]#strace–tttnvmeio-passthru/dev/nvme0--opcode=0x09--namespace-id=1--cdw10=0x00--cdw11=0x04--input-file=trim.bin--data-len=4096–write
我们经过计算得出TRIM耗时0.00124s,所以Trim的速度大约是:10 /0.00124= 8064.516GiB/s 大约8TB/s
4
TRIM后立即数据验证
[root@localhost~]#fio--thread--direct=1--allow_file_creat=0--ioengine=libaio--rw=read--bs=128k--iodepth=128--numjobs=1--name=nvme0n1--filename=/dev/nvme0n1--offset=10g--size=10g--verify=pattern--do_verify=1--verify_pattern=0x00nvme0n1:(g=0):rw=read,bs=(R)128KiB-128KiB,(W)128KiB-128KiB,(T)128KiB-128KiB,ioengine=libaio,iodepth=128fio-3.12Starting1threadJobs:1(f=1):[V(1)][-.-%][r=3176MiB/s][r=25.4kIOPS][eta00m:00s]nvme0n1:(groupid=0,jobs=1):err=0:pid=9241:MonMar421:37:352019read:IOPS=25.4k,BW=3171MiB/s(3325MB/s)(10.0GiB/3229msec)slat(usec):min=9,max=225,avg=11.21,stdev=3.14clat(usec):min=1938,max=11585,avg=5010.57,stdev=1313.65lat(usec):min=1948,max=11595,avg=5021.85,stdev=1313.57clatpercentiles(usec):|1.00th=[2147],5.00th=[2868],10.00th=[3294],20.00th=[3884],|30.00th=[4293],40.00th=[4621],50.00th=[4948],60.00th=[5342],|70.00th=[5735],80.00th=[6194],90.00th=[6783],95.00th=[7242],|99.00th=[8029],99.50th=[8225],99.90th=[8717],99.95th=[9110],|99.99th=[9765]bw(MiB/s):min=3168,max=3176,per=100.00%,avg=3172.88,stdev=3.26,samples=6iops:min=25348,max=25410,avg=25383.00,stdev=26.07,samples=6lat(msec):2=0.47%,4=22.76%,10=76.75%,20=0.01%cpu:usr=45.94%,sys=29.43%,ctx=22554,majf=0,minf=25IOdepths:1=0.1%,2=0.1%,4=0.1%,8=0.1%,16=0.1%,32=0.1%,>=64=99.9%submit:0=0.0%,4=100.0%,8=0.0%,16=0.0%,32=0.0%,64=0.0%,>=64=0.0%complete:0=0.0%,4=100.0%,8=0.0%,16=0.0%,32=0.0%,64=0.0%,>=64=0.1%issuedrwts:total=81920,0,0,0short=0,0,0,0dropped=0,0,0,0latency:target=0,window=0,percentile=100.00%,depth=128Runstatusgroup0(alljobs):READ:bw=3171MiB/s(3325MB/s),3171MiB/s-3171MiB/s(3325MB/s-3325MB/s),io=10.0GiB(10.7GB),run=3229-3229msecDiskstats(read/write):nvme0n1:ios=79930/0,merge=0/0,ticks=394735/0,in_queue=395214,util=96.95%[root@localhost~]#
可以看到加上--verify_pattern=0x00之后,err= 0,证明TRIM后数据都变成0了,至于更细节的说明,在此不再赘述。
通过一系列的介绍和实验验证,我们看到了TRIM的价值和实现原理。在TRIM的帮助下,NVMe SSD的GC等操作效率更高,进而达到降低写放大,提高产品性能和寿命的效果。
-
NAND
+关注
关注
16文章
1702浏览量
136953 -
SSD
+关注
关注
21文章
2909浏览量
118326 -
数据存储
+关注
关注
5文章
987浏览量
51276
原文标题:TRIM,让你的SSD再次飞起来
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
SSD是什么意思,什么是SSD
nand flash擦除写入不成功
为什么我无法调用SFUD的擦除操作呢?
嵌入式系统中Nand Flash写平衡的研究
电池管理器件的读/写操作
Linux下flash操作读、写、擦除步骤

三星Z-SSD、英特尔 Optane SSD 加大数据中心、服务器领域应用
如何彻底擦除和销毁SSD的技巧
PIC何谓读-修改-写,导致的问题及其解决之道






 工商网监
工商网监
评论