 Tensorflow 2.0版本如何帮助我们快速构建表格数据的神经网络分类模型
Tensorflow 2.0版本如何帮助我们快速构建表格数据的神经网络分类模型
以客户流失数据为例,看 Tensorflow 2.0 版本如何帮助我们快速构建表格(结构化)数据的神经网络分类模型。
变化
表格数据,你应该并不陌生。毕竟, Excel 这东西在咱们平时的工作和学习中,还是挺常见的。

在之前的教程里,我为你分享过,如何利用深度神经网络,锁定即将流失的客户。里面用到的,就是这样的表格数据。
时间过得真快,距离写作那篇教程,已经一年半了。
这段时间里,出现了2个重要的变化,使我觉得有必要重新来跟你谈谈这个话题。
这两个变化分别是:
首先,tflearn 框架的开发已经不再活跃。

tflearn 是当时教程中我们使用的高阶深度学习框架,它基于 Tensorflow 之上,包裹了大量的细节,让用户可以非常方便地搭建自己的模型。
但是,由于 Tensorflow 选择拥抱了它的竞争者 Keras ,导致后者的竞争优势凸显。
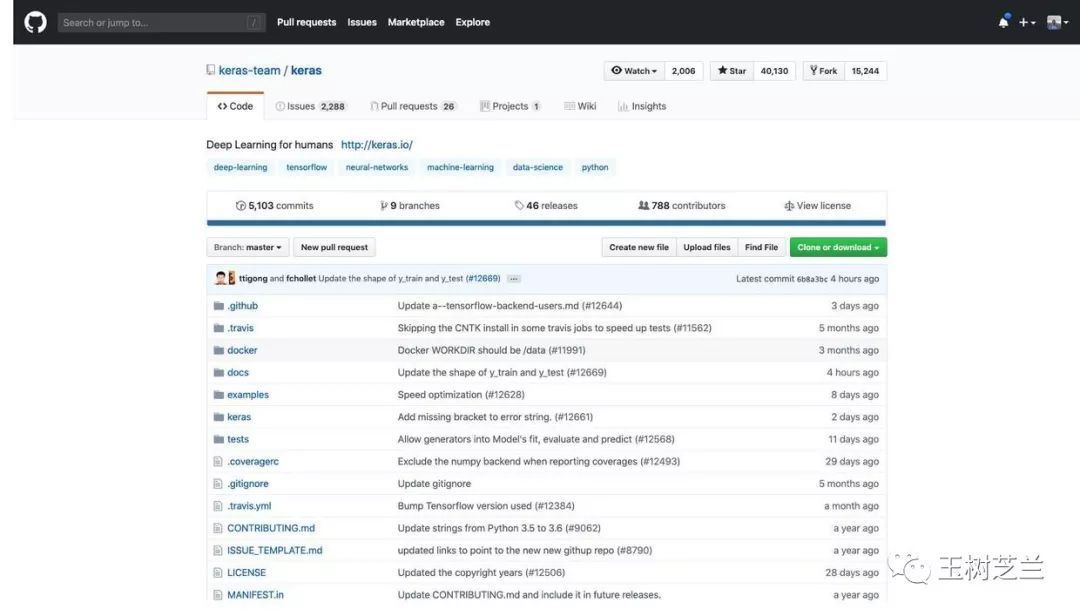
对比二者获得的星数,已经不在同一量级。
观察更新时间,tflearn 已经几个月没有动静;而 Keras 几个小时之前,还有更新。
我们选择免费开源框架,一定要使用开发活跃、社区支持完善的。只有这样,遇到问题才能更低成本、高效率地解决。
看过我的《Python编程遇问题,文科生怎么办?》一文之后,你对上述结论,应该不陌生。
另一项新变化,是 Tensorflow 发布了 2.0 版本。
相对 1.X 版本,这个大版本的变化,我在《如何用 Python 和 BERT 做中文文本二元分类?》一文中,已经粗略地为你介绍过了。简要提炼一下,就是:
之前的版本,以计算图为中心。开发者需要为这张图服务。因此,引入了大量的不必要术语。新版本以人为中心,用户撰写高阶的简洁语句,框架自动将其转化为对应的计算图。
之前的版本,缺少目前竞争框架(如 PyTorch 等)包含的新特性。例如计算图动态化、运行中调试功能等。
但对普通开发者来说,最为重要的是,官方文档和教程变得对用户友好许多。不仅写得清晰简明,更靠着Google Colab的支持,全都能一键运行。我尝试了 2.0 版本的一些教程样例,确实感觉大不一样了。

其实你可能会觉得奇怪—— Tensorflow 大张旗鼓宣传的大版本改进,其实也无非就是向着 PyTorch早就有的功能靠拢而已嘛。那我干脆去学 PyTorch 好了!
如果我们只说道理,这其实没错。然而,还是前面那个论断,一个框架好不好,主要看是否开发活跃、社区支持完善。这就是一个自证预言。一旦人们都觉得 Tensorflow 好用,那么 Tensorflow 就会更好用。因为会有更多的人参与进来,帮助反馈和改进。
看看现在 PyTorch 的 Github 页面。
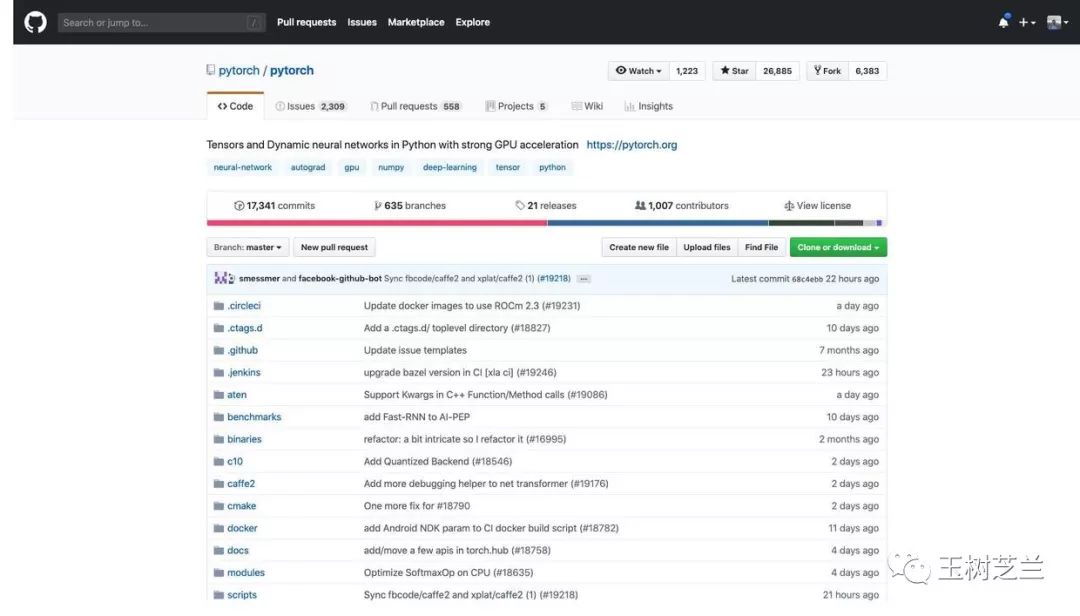
受关注度,确实已经很高了。
然而你再看看 Tensorflow 的。

至少在目前,二者根本不在一个数量级。
Tensorflow 的威力,不只在于本身构建和训练模型是不是好用。那其实只是深度学习中,非常小的一个环节。不信?你在下图里找找看。
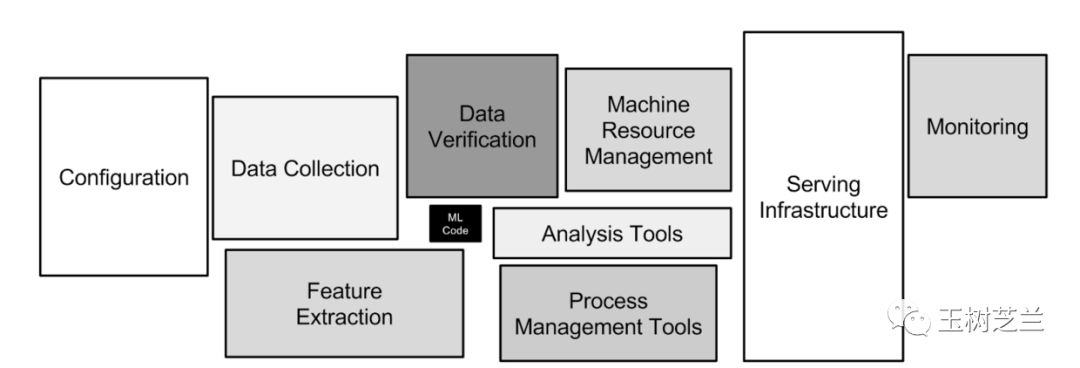
真正的问题,在于是否有完整的生态环境支持。其中的逻辑,我在《学 Python ,能提升你的竞争力吗?》一文中,已经为你详细分析过了。
而 Tensorflow ,早就通过一系列的布局,使得其训练模型可以直接快速部署,最快速度铺开,帮助开发者占领市场先机。

如果你使用 PyTorch ,那么这样的系统,是相对不完善的。当然你可以在 PyTorch 中训练,然后转换并且部署到 Tensorflow 里面。毕竟三巨头达成了协议,标准开放,这样做从技术上并不困难。

但是,人的认知带宽,是非常有限的。大部分人,是不会选择在两个框架甚至生态系统之间折腾的。这就是路径依赖。
所以,别左顾右盼了,认认真真学 Tensorflow 2.0 吧。
这篇文章里面,我给你介绍,如何用 Tensorflow 2.0 ,来训练神经网络,对用户流失数据建立分类模型,从而可以帮你见微知著,洞察风险,提前做好干预和防范。
数据
你手里拥有的,是一份银行欧洲区客户的数据,共有10000条记录。客户主要分布在法国、德国和西班牙。

数据来自于匿名化处理后的真实数据集,下载自 superdatascience 官网。
从表格中,可以读取的信息,包括客户们的年龄、性别、信用分数、办卡信息等。客户是否已流失的信息在最后一列(Exited)。
这份数据,我已经上传到了这个地址,你可以下载,并且用 Excel 查看。
环境
本文的配套源代码,我放在了这个 Github 项目中。请你点击这个链接(http://t.cn/EXffmgX)访问。

如果你对我的教程满意,欢迎在页面右上方的 Star 上点击一下,帮我加一颗星。谢谢!
注意这个页面的中央,有个按钮,写着“在 Colab 打开” (Open in Colab)。请你点击它。
然后,Google Colab 就会自动开启。
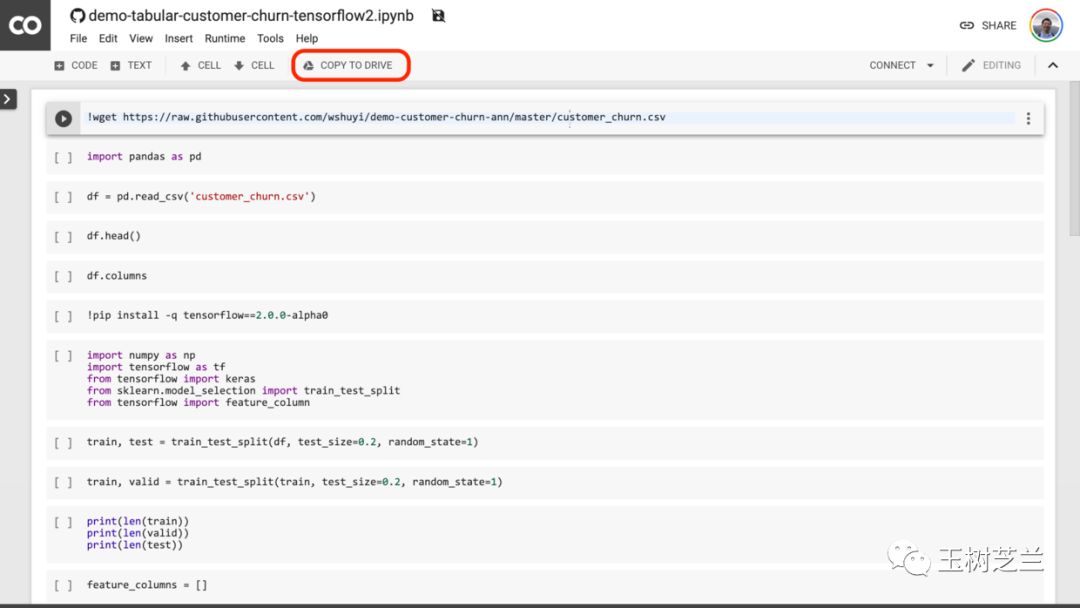
我建议你点一下上图中红色圈出的 “COPY TO DRIVE” 按钮。这样就可以先把它在你自己的 Google Drive 中存好,以便使用和回顾。

Colab 为你提供了全套的运行环境。你只需要依次执行代码,就可以复现本教程的运行结果了。
如果你对 Google Colab 不熟悉,没关系。我这里有一篇教程,专门讲解 Google Colab 的特点与使用方式。
为了你能够更为深入地学习与了解代码,我建议你在 Google Colab 中开启一个全新的 Notebook ,并且根据下文,依次输入代码并运行。在此过程中,充分理解代码的含义。
这种看似笨拙的方式,其实是学习的有效路径。
代码
首先,我们下载客户流失数据集。
!wgethttps://raw.githubusercontent.com/wshuyi/demo-customer-churn-ann/master/customer_churn.csv
载入 Pandas 数据分析包。
importpandasaspd
利用 read_csv 函数,读取 csv 格式数据到 Pandas 数据框。
df=pd.read_csv('customer_churn.csv')
我们来看看前几行显示结果:
df.head()

显示正常。下面看看一共都有哪些列。
df.columns

我们对所有列,一一甄别。
RowNumber:行号,这个对于模型没用,忽略
CustomerID:用户编号,这个是顺序发放的,忽略
Surname:用户姓名,对流失没有影响,忽略
CreditScore:信用分数,这个很重要,保留
Geography:用户所在国家/地区,这个有影响,保留
Gender:用户性别,可能有影响,保留
Age:年龄,影响很大,年轻人更容易切换银行,保留
Tenure:当了本银行多少年用户,很重要,保留
Balance:存贷款情况,很重要,保留
NumOfProducts:使用产品数量,很重要,保留
HasCrCard:是否有本行信用卡,很重要,保留
IsActiveMember:是否活跃用户,很重要,保留
EstimatedSalary:估计收入,很重要,保留
Exited:是否已流失,这将作为我们的标签数据
确定了不同列的含义和价值,下面我们处理起来,就得心应手了。
数据有了,我们来调入深度学习框架。
因为本次我们需要使用 Tensorflow 2.0 ,而写作本文时,该框架版本尚处于 Alpha 阶段,因此 Google Colab 默认使用的,还是 Tensorflow 1.X 版本。要用 2.0 版,便需要显式安装。
!pipinstall-qtensorflow==2.0.0-alpha0
安装框架后,我们载入下述模块和函数,后文会用到。
importnumpyasnpimporttensorflowastffromtensorflowimportkerasfromsklearn.model_selectionimporttrain_test_splitfromtensorflowimportfeature_column
这里,我们设定一些随机种子值。这主要是为了保证结果可复现,也就是在你那边的运行结果,和我这里尽量保持一致。这样我们观察和讨论问题,会更方便。
首先是 Tensorflow 中的随机种子取值,设定为 1 。
tf.random.set_seed(1)
然后我们来分割数据。这里使用的是 Scikit-learn 中的 train_test_split 函数。指定分割比例即可。
我们先按照80:20的比例,把总体数据分成训练集和测试集。
train,test=train_test_split(df,test_size=0.2,random_state=1)
然后,再把现有训练集的数据,按照80:20的比例,分成最终的训练集,以及验证集。
train,valid=train_test_split(train,test_size=0.2,random_state=1)
这里,我们都指定了 random_state ,为的是保证咱们随机分割的结果一致。
我们看看几个不同集合的长度。
print(len(train))print(len(valid))print(len(test))

验证无误。下面我们来做特征工程(feature engineering)。
因为我们使用的是表格数据(tabular data),属于结构化数据。因此特征工程相对简单一些。
先初始化一个空的特征列表。
feature_columns=[]
然后,我们指定,哪些列是数值型数据(numeric data)。
numeric_columns=['CreditScore','Age','Tenure','Balance','NumOfProducts','EstimatedSalary']
可见,包含了以下列:
CreditScore:信用分数
Age:年龄
Tenure:当了本银行多少年用户
Balance:存贷款情况
NumOfProducts:使用产品数量
EstimatedSalary:估计收入
对于这些列,只需要直接指定类型,加入咱们的特征列表就好。
forheaderinnumeric_columns:feature_columns.append(feature_column.numeric_column(header))
下面是比较讲究技巧的部分了,就是类别数据。
先看看都有哪些列:
categorical_columns=['Geography','Gender','HasCrCard','IsActiveMember']
Geography:用户所在国家/地区
Gender:用户性别
HasCrCard:是否有本行信用卡
IsActiveMember:是否活跃用户
类别数据的特点,在于不能直接用数字描述。例如 Geography 包含了国家/地区名称。如果你把法国指定为1, 德国指定为2,电脑可能自作聪明,认为“德国”是“法国”的2倍,或者,“德国”等于“法国”加1。这显然不是我们想要表达的。
所以我这里编了一个函数,把一个类别列名输入进去,让 Tensorflow 帮我们将其转换成它可以识别的类别形式。例如把法国按照 [0, 0, 1],德国按照 [0, 1, 0] 来表示。这样就不会有数值意义上的歧义了。
defget_one_hot_from_categorical(colname):categorical=feature_column.categorical_column_with_vocabulary_list(colname,train[colname].unique().tolist())returnfeature_column.indicator_column(categorical)
我们尝试输入 Geography 一项,测试一下函数工作是否正常。
geography=get_one_hot_from_categorical('Geography');geography

观察结果,测试通过。
下面我们放心大胆地把所有类别数据列都在函数里面跑一遍,并且把结果加入到特征列表中。
forcolincategorical_columns:feature_columns.append(get_one_hot_from_categorical(col))
看看此时的特征列表内容:
feature_columns

6个数值类型,4个类别类型,都没问题了。
下面该构造模型了。
我们直接采用 Tensorflow 2.0 鼓励开发者使用的 Keras 高级 API 来拼搭一个简单的深度神经网络模型。
fromtensorflow.kerasimportlayers
我们把刚刚整理好的特征列表,利用 DenseFeatures 层来表示。把这样的一个初始层,作为模型的整体输入层。
feature_layer=layers.DenseFeatures(feature_columns);feature_layer

下面,我们顺序叠放两个中间层,分别包含200个,以及100个神经元。这两层的激活函数,我们都采用 relu 。
relu 函数大概长这个样子:

model=keras.Sequential([feature_layer,layers.Dense(200,activation='relu'),layers.Dense(100,activation='relu'),layers.Dense(1,activation='sigmoid')])
我们希望输出结果是0或者1,所以这一层只需要1个神经元,而且采用的是 sigmoid 作为激活函数。
sigmoid 函数的长相是这样的:

模型搭建好了,下面我们指定3个重要参数,编译模型。
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])
这里,我们选择优化器为 adam 。
因为评判二元分类效果,所以损失函数选的是 binary_crossentropy。
至于效果指标,我们使用的是准确率(accuracy)。
模型编译好之后。万事俱备,只差数据了。
你可能纳闷,一上来不就已经把训练、验证和测试集分好了吗?
没错,但那只是原始数据。我们模型需要接收的,是数据流。
在训练和验证过程中,数据都不是一次性灌入模型的。而是一批次一批次分别载入。每一个批次,称作一个 batch;相应地,批次大小,叫做 batch_size 。
为了方便咱们把 Pandas 数据框中的原始数据转换成数据流。我这里编写了一个函数。
defdf_to_tfdata(df,shuffle=True,bs=32):df=df.copy()labels=df.pop('Exited')ds=tf.data.Dataset.from_tensor_slices((dict(df),labels))ifshuffle:ds=ds.shuffle(buffer_size=len(df),seed=1)ds=ds.batch(bs)returnds
这里首先是把数据中的标记拆分出来。然后根据把数据读入到 ds 中。根据是否是训练集,我们指定要不要需要打乱数据顺序。然后,依据 batch_size 的大小,设定批次。这样,数据框就变成了神经网络模型喜闻乐见的数据流。
train_ds=df_to_tfdata(train)valid_ds=df_to_tfdata(valid,shuffle=False)test_ds=df_to_tfdata(test,shuffle=False)
这里,只有训练集打乱顺序。因为我们希望验证和测试集一直保持一致。只有这样,不同参数下,对比的结果才有显著意义。
有了模型架构,也有了数据,我们把训练集和验证集扔进去,让模型尝试拟合。这里指定了,跑5个完整轮次(epochs)。
model.fit(train_ds,validation_data=valid_ds,epochs=5)

你会看到,最终的验证集准确率接近80%。
我们打印一下模型结构:
model.summary()

虽然我们的模型非常简单,却也依然包含了23401个参数。
下面,我们把测试集放入模型中,看看模型效果如何。
model.evaluate(test_ds)

依然,准确率接近80%。
还不错吧?
……
真的吗?
疑惑
如果你观察很仔细,可能刚才已经注意到了一个很奇特的现象:

训练的过程中,除了第一个轮次外,其余4个轮次的这几项重要指标居然都没变!
它们包括:
训练集损失
训练集准确率
验证集损失
验证集准确率
所谓机器学习,就是不断迭代改进啊。如果每一轮下来,结果都一模一样,这难道不奇怪吗?难道没问题吗?
我希望你,能够像侦探一样,揪住这个可疑的线索,深入挖掘进去。
这里,我给你个提示。
看一个分类模型的好坏,不能只看准确率(accuracy)。对于二元分类问题,你可以关注一下 f1 score,以及混淆矩阵(confusion matrix)。
如果你验证了上述两个指标,那么你应该会发现真正的问题是什么。
下一步要穷究的,是问题产生的原因。
回顾一下咱们的整个儿过程,好像都很清晰明了,符合逻辑啊。究竟哪里出了问题呢?
如果你一眼就看出了问题。恭喜你,你对深度学习已经有感觉了。那么我继续追问你,该怎么解决这个问题呢?
欢迎你把思考后的答案在留言区告诉我。
对于第一名全部回答正确上述问题的读者,我会邀请你作为嘉宾,免费(原价199元)加入我本年度的知识星球。当然,前提是你愿意。
小结
希望通过本文的学习,你已掌握了以下知识点:
Tensorflow 2.0 的安装与使用;
表格式数据的神经网络分类模型构建;
特征工程的基本流程;
数据集合的随机分割与利用种子数值保持一致;
数值型数据列与类别型数据列的分别处理方式;
Keras 高阶 API 的模型搭建与训练;
数据框转化为 Tensorflow 数据流;
模型效果的验证;
缺失的一环,也即本文疑点产生的原因,以及正确处理方法。
希望本教程对于你处理表格型数据分类任务,能有帮助。
-
神经网络
+关注
关注
42文章
4771浏览量
100755 -
深度学习
+关注
关注
73文章
5503浏览量
121154 -
tensorflow
+关注
关注
13文章
329浏览量
60535
原文标题:怎样搞定分类表格数据?有人用TF2.0构建了一套神经网络 | 技术头条
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论