 利用2.5GPU年的算力在7个数据集上训练了12000多个模型
利用2.5GPU年的算力在7个数据集上训练了12000多个模型
基于无监督的方式理解高维数据并将信息浓缩为有用的表示一直是深度学习领域研究的关键问题。其中一种方法是利用非耦合表示(disentangled representations)模型来捕捉场景中独立变化的特征。如果能够实现对于各种独立特征的描述,机器学习系统就可以用于真实环境中的导航,机器人或无人车利用这种方法可以将环境解构成一系列元素,并利用通用的知识去理解先前未见过的场景。
虽然非监督解耦方法已被广泛应用于好奇驱动的探索、抽象推理、视觉概念学习和域适应的强化学习中,但最近进展却无法让我们清晰了解不同方法的性能和方法的局限。为了深入探索这一问题,谷歌的研究人员在ICML2019上发表了一篇大规模深入研究非监督非耦合表示的论文”Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations”,对近年来绝大多数的非监督解耦表示方法进行探索、利用2.5GPU年的算力在7个数据集上训练了12000多个模型。基于大规模的实验结果,研究人员对这一领域的一些假设产生了质疑,并为解耦学习的未来发展方向给出了建议。与此同时,研究人员还同时发布了研究中所使用的代码和上万个预训练模型,并封装了disentanglement_lib供研究者进行实验复现和更深入的探索。
理解非耦合表示
为了更好地理解非耦合表示的本质,让我一起来看看下面动图中每个独立变化的元素。下面的每一张图代表了一个可以被编码到矢量表示中的因子,它可以独立控制图像中每个语义元素的属性。例如第一个可以控制地板的颜色,第二个则控制墙的颜色,最后一个则控制图片的视角。
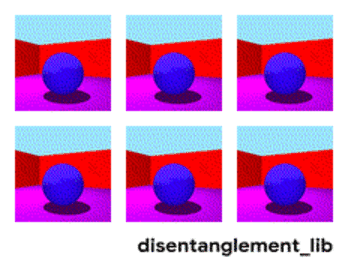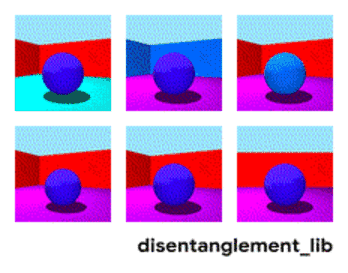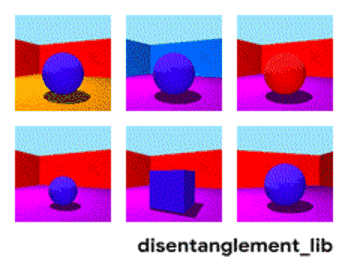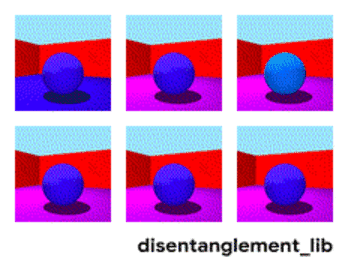
解耦表示的目标在于建立起一个能够独立捕捉这些特征的模型,并将这些特征编码到一个表示矢量中。下面的10个小图展示了基于FactorVAE方法学习十维表示矢量的模型,图中展示 了每一维对于图像对应信息的捕捉。从各个图中可以看出模型成功地解耦了地板、墙面的颜色,但是左下角的两个图片可以看到物体的颜色和大小的表示却依然相关没有解耦。
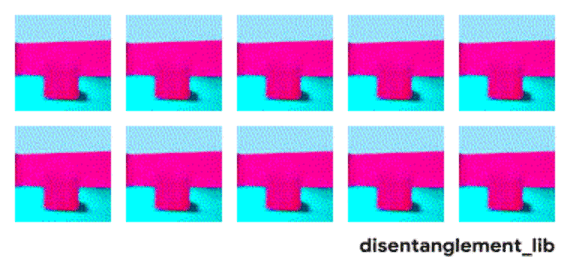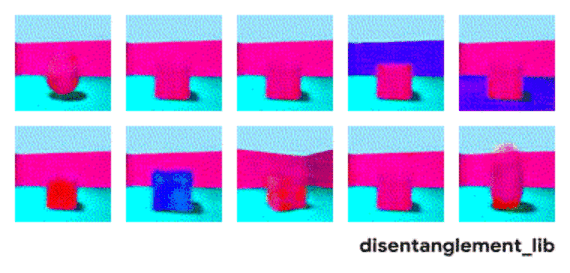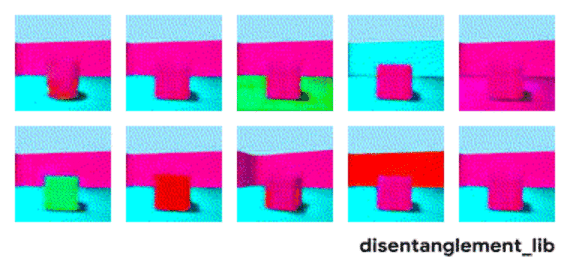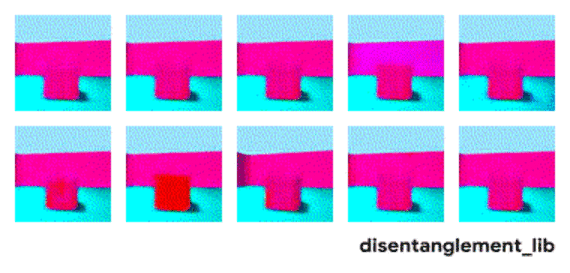
大规模研究的发现
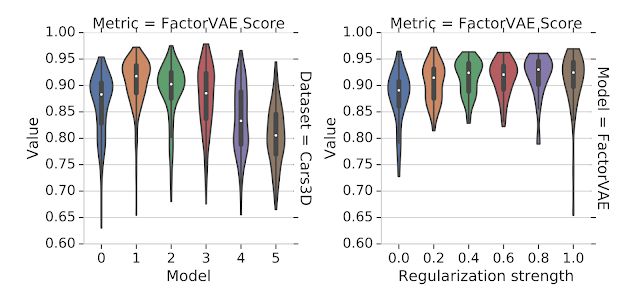
在直观地理解了解耦表示之后,让我们来看看科学家在研究中发现了什么。这一领域基于变分自编码器提出了各种各样的非监督方法来学习非耦合表示,同时给出了许多不同的性能度量方法,但却缺乏一个大规模的性能测评和对比研究。为此研究人员构建了一个大规模、公平性、可复现的实验基准,并系统的测试了六种不同的模型(BetaVAE, AnnealedVAE, FactorVAE, DIP-VAE I/II and Beta-TCVAE)和解耦性能度量方法(BetaVAE score, FactorVAE score, MIG, SAP, Modularity and DCI Disentanglement),在7个数据集上进行了12800个模型的训练后,研究人员们有了颠覆过去的发现:首先,是非监督学习的方式。研究人员在大量的实验后发现没有可靠的证据表明模型可以通过无监督的方式学习到有效的解耦表示,随机种子和超参数对于结构的影响甚至超过了模型的选择。换句话说,即使你训练的大量模型中有部分是解耦的,但这些解耦表示在不基于基准标签的情况下是无从确认和识别的。此外好的超参数在不同的数据集上并不一致,这意味着没有归纳偏置(inductive biases)是无法实现非监督解耦学习的(需要把对数据集的假设考虑进模型中)。对于实验中评测的模型和数据集,研究人员表示无法验证解耦对于downstream tasks任务有利的假设(这一假设认为基于解耦表示可以利用更少的标签来进行学习)。下图展示了研究中的一些发现,可以看到随机种子在运行中的影响超过了模型的选择(左)和正则化(右)的强度(更强的正则化并没有带来更多的解耦性能)。这意味着很差超参数作用下的好模型也许比很好超参数作用下的坏模型要好得多。
未来研究方向
基于这些全新的发现和研究结果,研究人员为解耦表示领域提出了四个可能的方向:1.在没有归纳偏置的条件下给出非监督解耦表示学习的理论结果是不可能的,未来的研究应该更多地集中于归纳偏置的研究以及隐式和显示监督在学习中所扮演的角色;2.为横跨多数据集的非监督模型寻找一个有效的归纳偏置将会成为关键的开放问题;3.应该强调解耦学习在各个特定领域所带来的实际应用价值,潜在的应用方向包括机器人、抽象推理和公平性等;4.在各种多样性数据集上的实验应该保证可重复性。
代码和工具包
为了让其他研究人员更好的复现结构,论文同时还发布了 disentanglement_lib工具包,其中包含了实验所需的模型、度量、训练、预测以及可视化代码工具。可以在命令行中用不到四行代码就能复现是论文中所提到的模型,也可以方便地改造来验证新的假设。最后 disentanglement_lib库易于拓展和集成,易于创建新的模型,并用公平的可复现的比较进行检验。由于复现所有的模型训练需要2.5GPU年的算力,所以研究人员同时开放了论文中提到的一万多个预训练模型可以配合前述工具使用。如果想要使用这个工具可以在这里找到源码:
https://github.com/google-research/disentanglement_lib
其中包含了以下内容:模型:BetaVAE, FactorVAE, BetaTCVAE, DIP-VAE度量:BetaVAE score, FactorVAE score, Mutual Information Gap, SAP score, DCI, MCE数据集:dSprites, Color/Noisy/Scream-dSprites, SmallNORB, Cars3D, and Shapes3D预训练模型:10800 pretrained disentanglement models依赖包:TensorFlow, Scipy, Numpy, Scikit-Learn, TFHub and Gin
git clone https://github.com/google-research/disentanglement_lib.git #下载gitcd disentanglement_lib #转到源码目录pip install .[tf_gpu] #安装依赖文件dlib_tests #验证安装
随后下载对应的数据文件:
dlib_download_data#在.bashrc写入路径export DISENTANGLEMENT_LIB_DATA=
随后就可以愉快地复现实验了,其中?是0-12599间的模型序号:dlib_reproduce --model_num=进行评测:dlib_aggregate_results
相信这篇文章的研究结果和代码工具将为接下来的研究提供更为明确的方向和便捷的途径,促进非耦合表示学习领域的发展。
-
谷歌
+关注
关注
27文章
6171浏览量
105466 -
gpu
+关注
关注
28文章
4743浏览量
128983 -
数据集
+关注
关注
4文章
1208浏览量
24717
原文标题:耗时2.5GPU年训练12800个模型,谷歌研究人员揭示非耦合表示的奥秘
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

名单公布!【书籍评测活动NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架构分析
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--全书概览
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--了解算力芯片GPU
在Ubuntu上使用Nvidia GPU训练模型
索尼发布新的方法,在ImageNet数据集上224秒内成功训练了ResNet-50
ICML 2019最佳论文新鲜出炉!
利用ImageNet训练了一个能降噪、超分和去雨的图像预训练模型

【一文看懂】大白话解释“GPU与GPU算力”






 工商网监
工商网监
评论