 迷茫的后端 想做大数据可以少走很多弯路
迷茫的后端 想做大数据可以少走很多弯路
随着大数据、人工智能的火热,很多程序员都不甘现状,寻求更广阔的发展。但高薪工作也意味着高压,对于很多工作了三五年的程序员来说,更不想放弃现有的技术基础,去重新学习新领域的技术。但大数据作为一个飞速发展的热门领域,一半以上的专业人才却是转行而来……
1
数据是未来的“一切”
很多向大数据方向发展的人,都是看到了这个行业未来无限广阔的前景和“钱景”。大数据并不是新名词,但近几年大数据、人工智能向各行各业逐渐渗透,数据也随之井喷式增长。早年掌握大量用户数据的互联网公司,已经向世人展现数据在不同应用场景中的巨大价值:
“天然”大数据公司亚马逊从海量购买数据中获得信息、预测用户行为;谷歌已成为网民的“意图数据库”;LinkedIn的猎头价值;滴滴等出行、物流配送业务利用交易数据进行实时定价,使利润最大化;还有的借助大数据相关技术,创造出新的业务模式——比如利用算法做个性化内容推荐的今日头条、一点资讯……
“一旦进入大数据的世界,企业的手中将握有无限可能。你会发现数据越大,结果越好。为什么有的企业在商业上不断犯错?那是因为他们没有足够的数据对运营和决策提供支持。”
亚马逊CTO Werner Vogels
数据人才的旺盛需求源自一个根本性的变化:科技公司现如今都成了数据公司。大到 BAT 等互联网巨头,小到创业公司,都在向数据驱动型企业转变,挖掘数据、解读数据、用数据洞察助力企业业务发展变得更加重要,导致行业内人才的供给相对不足,薪资也非常可观。
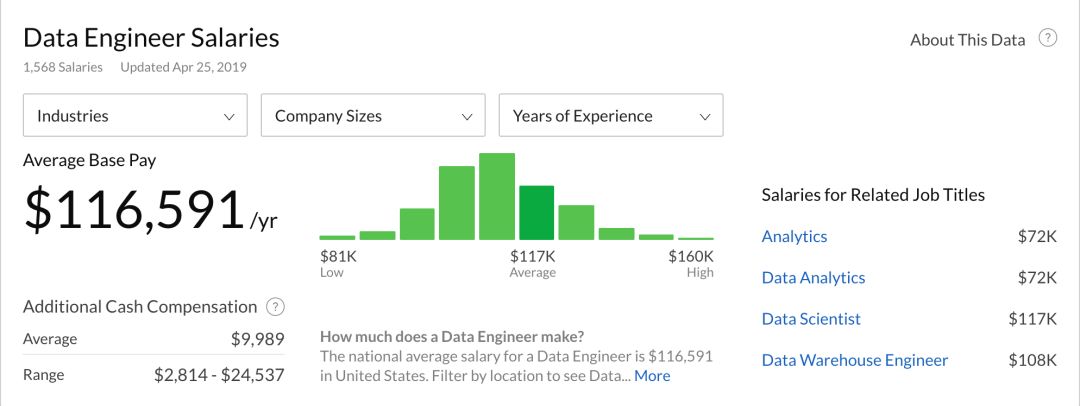
*数据工程师平均薪资(取自2019/4/25,Glassdoor)
Glassdoor 最新数据显示,美国数据工程师平均年薪为 116k 美金(约合月薪 6w+ 人民币),比数据分析师高出60%。北美就业情况是中国的晴雨表,对比其他数据岗位,国内的数据工程师需求急速上升。
2
数据工程师转行人士占46%
随着企业需求的增长,数据工程师数量也随之急速增长,其中,接近一半的比例是从其他相关岗位转行而来。越来越多的程序员、工程师转而向大数据方向发展,不仅仅是岗位的高薪,也是为了顺应时代。并且从企业对数据人才的需求增长来看,这一趋势并不会有所放缓。
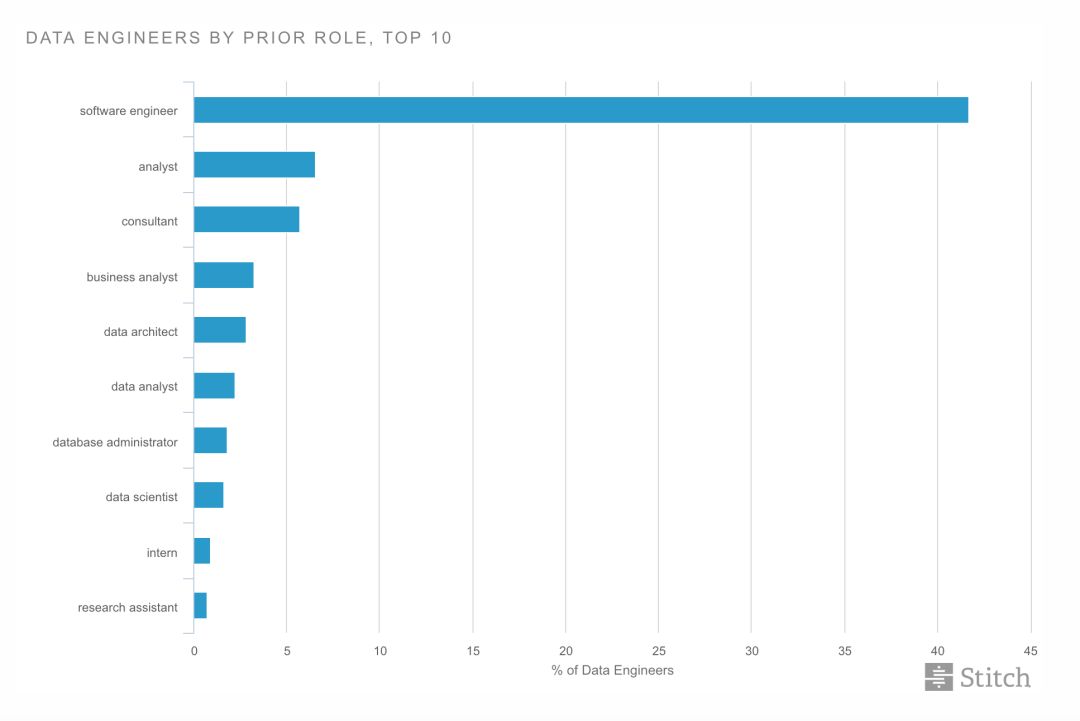
* 数据工程师的岗位来源前 10,排名最高的分别是软件工程师(41.67%)、分析师、咨询师、商业分析师。数据来源:Stitch,点击可查看大图
大数据行业之所以转行人士占比大,也是因为转行的门槛相对不高:
首先,大数据本身的年龄不大。其他岗位动辄“10年开发经验”的要求比比皆是,但大数据相关岗位往往更看重能力,不会对工作年限有过高要求,无形之中为刚毕业的学生、转行人士提供了很多机会。
其次,大多数企业对大数据人才需求并不明确。大数据不是单一的学科,需要多方向的内容支撑。因此当企业需求不明确时,很多人本来在从事软件工程师、后端、甚至是算法等岗位,只需补充对应的技术内容,很容易转型大数据方向,还有很多想成为数据科学家的人,通过数据工程师“曲线救国”。
3
需要走多少弯路,才能成为数据工程师?
回答这个问题之前,你首先要知道数据工程师需要做什么,各种新技术和产品的出现,数据工程师这个角色也发生了较大的变化。
几年前的数据工程师,主要管理数据进出数据库,在 SQL 或 Procedural SQL 中创建管道,并在数据仓库中加载数据,创建统一、标准化的数据集结构以供后期分析。但 2018 年以来,他们不再仅仅为数据的后期分析提供支持,还要负责整个数据流,保证任何数据都能够正常操作,并方便其他使用者获取。
这里的新技术和新产品,主要指的是大数据及其相关技术、DOE、机器学习、Spark&Real-time、云开发和无服务器等。
大数据:
2006年,Hadoop 的开源大大改变了数据格局,存储大量数据变得更容易,更便宜。最初,在 Hadoop 上进行开发非常复杂,需要用 Java 开发 Map Reduce 作业。直到 2010 年 Hive 开源,更多传统数据工程师才能更容易进入这个大数据时代。
DOE:
随着大数据的发展,大型互联网公司面临的最大挑战是:缺少运行复杂数据流的工具。Spotify 在2012年开源 Luigi,在 2015 年开源 Airbnb Airflow,这些编排引擎本质上是把数据流作为代码。Python 是大多数编排引擎的编译语言。
机器学习:
在 Hadoop 出现之前,我们通常在一台机器上训练机器学习模型,并且以非常特殊的方式进行应用。对于大型互联网公司而言,需要利用先进的软件开发技术以更好地训练机器学习模型并应用到生产中,比如使用 Mahout 之类的框架。
Spark&Real-time:
2014 年 Spark 发布了用于 python 的 MLlib,也将大数据上的机器学习计算民主化。关于 Hadoop 和 Spark 的选择问题,也一直在讨论中。作为两个顶级的 Apache 项目,Spark 在性能、成本、可用性、安全性和机器学习等多个角度,都比 Hadoop 略胜一筹,或许 Spark 在未来会成为大数据领域更年轻的“统治者”。
云开发和无服务器:
迁移到云对数据工程师而言有多重影响。“云”打破了物理限制,对于大多数用户而言,它意味着存储和计算趋于无限化。这样一来,就不再需要对服务器进行不断的优化。而且,通过允许扩展和减少资源来实现云,使得处理数据工程中典型的高峰批处理作业变得更加容易。
大数据行业,甚至是整个程序员行业,都是需要不停学习、不停经历技术迭代的,想要成为一名新时代下的数据工程师,就必须不断学习新技术以适应这快速的变化。
Udacity 全新上线的数据工程师纳米学位课程,将帮助想要进入该领域的人学到必备的专业技能,并在实际场景中进行应用,进而找到理想的工作。
或许很多人对 Udacity 并不陌生。Udacity 由 Google X 实验室的无人车之父 Sebastian Thrun 创立,课程与 Amazon、Google、Kaggle 等全球领先企业联合开发。在 MOOC 发展较为成熟的美国,Udacity 为毕业生颁发的「纳米学位」相当于“名企敲门砖”。
2016 年登陆中国后,与更多中国企业达成合作,腾讯、京东、唯品会等互联网名企,都将 Udacity 纳米学位项目作为员工的内部培训内容,入职的 Udacity 毕业生甚至可以获得公司的“学费返还”,纳米学位在中国的影响也在逐渐扩大。
-
互联网
+关注
关注
54文章
11163浏览量
103419 -
大数据
+关注
关注
64文章
8895浏览量
137503 -
后端
+关注
关注
0文章
31浏览量
2267
原文标题:迷茫的后端:想做大数据,没有这么多弯路要走
文章出处:【微信号:LinuxHub,微信公众号:Linux爱好者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
虹科直播 | 掌握这些,少走弯路!叶正祥老师教你NVH常见问题诊断技巧!

ADS1299后端数据是通过写好的exe程序来处理的?
缓存对大数据处理的影响分析
raid 在大数据分析中的应用
智慧城市与大数据的关系
IP 地址大数据分析如何进行网络优化?

请教,SIM卡PCB走线,这个CKL时钟线和数据线DATA要等长嘛,一条走顶层一条走底层如图这样可以嘛
使用CYW20829的BLE进行最大数据发送应用,BLE丢失数据如何解决?
前后端数据传输约定探讨





 工商网监
工商网监
评论