 人工智能最后一公里,Google和英伟达谁能跑得赢?
人工智能最后一公里,Google和英伟达谁能跑得赢?
Google Coral Edge TPU和NVIDIA Jetson Nano大比拼!本文从分别对两款最新推出的EdgeAI芯片做了对比,分析了二者各自的优劣势。
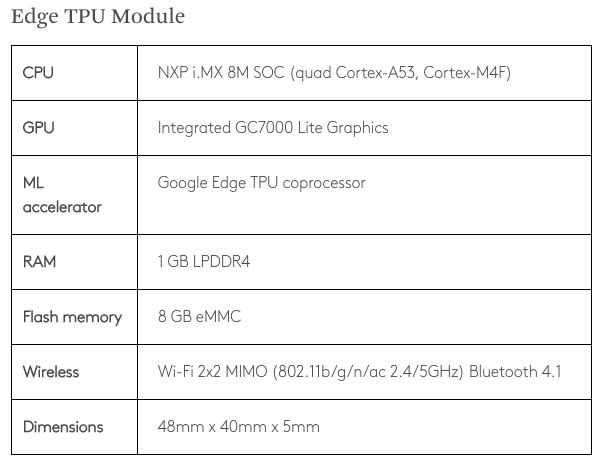
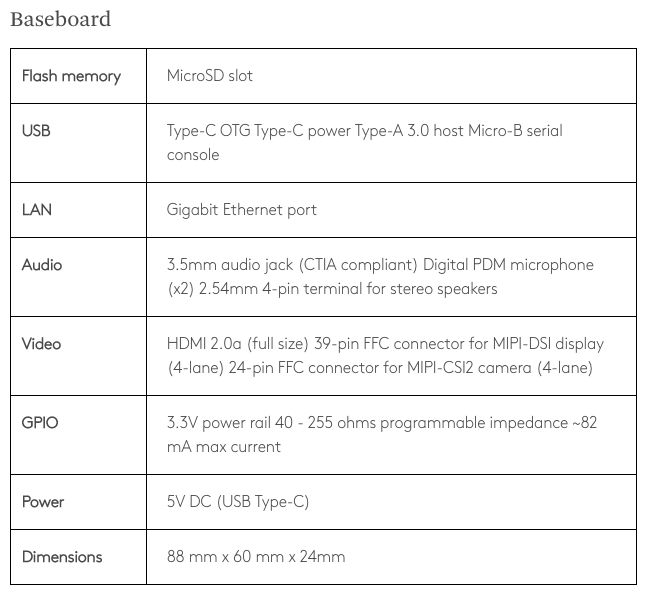
Google刚刚在3月份推出了Coral Edge TPU,是一款售价不到1000元人民币的开发板(Coral Dev Board),由Edge TPU模块和 Baseboard 组成。参数如下:
英伟达同样在上个月发布了最新的NVIDIA Jetson Nano,Jetson Nano是一款类似于树莓派的嵌入式电脑设备,其搭载了四核Cortex-A57处理器,GPU则是拥有128个NVIDIA CUDA核心的NVIDIA麦克斯韦架构显卡,内存4GB LPDDR4,存储则为16GB eMMC 5.1,支持4K 60Hz视频解码。
目前位置并没有太多关于这两款产品的评测报告。今天新智元为大家带来一篇由网友Sam Sterckval对两款产品的评测,除此以外他还测试了i7-7700K + GTX1080(2560CUDA),Raspberry Pi 3B +,以及一个2014年的MacBook pro包含一个i7-4870HQ(没有支持CUDA的内核)。
Sam使用MobileNetV2作为分类器,在imagenet数据集上进行预训练,直接从Keras使用这个模型,后端则使用TensorFlow。使用GPU的浮点权重,以及CPU和Coral Edge TPU的8bit量化tflite版本。
首先,加载模型以及一张喜鹊图像。先执行1个预测作为预热,Sam发现第一个预测总是比随后的预测更能说明问题。然后Sleep 1秒,确保所有的线程的活动都终止,然后对同一图像进行250次分类。
对所有分类使用相同的图像,能够确保在整个测试过程中保持接近的数据总线。
对比结果
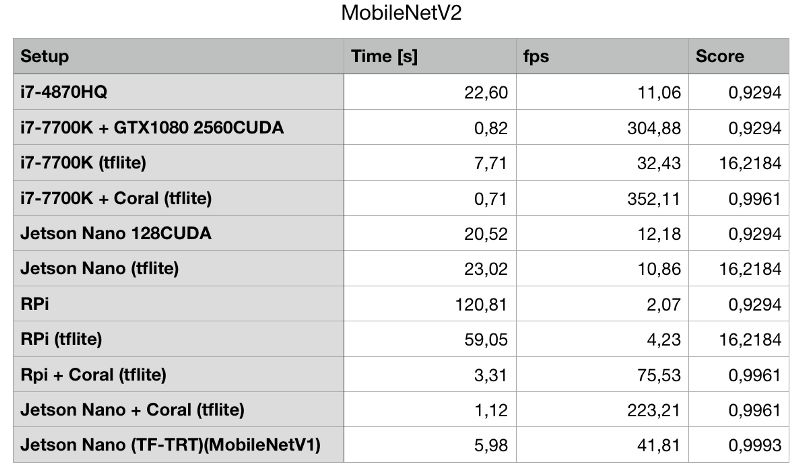
先来看最终的结果:
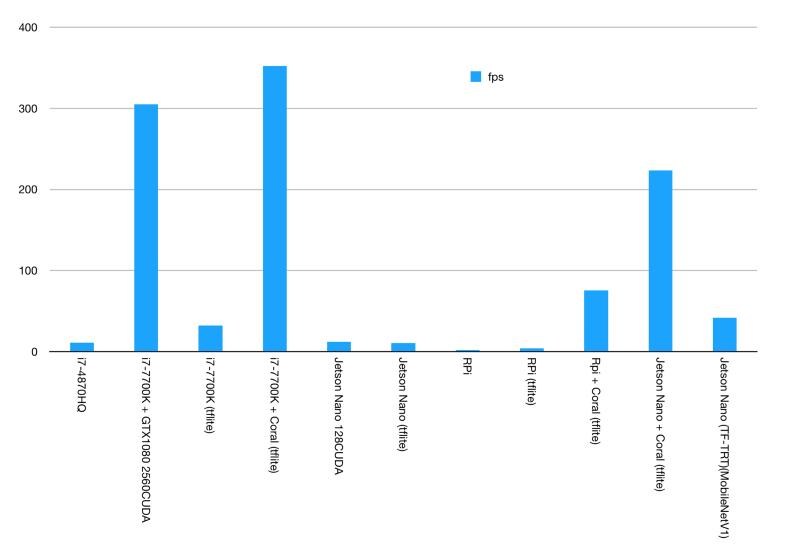
线性刻度,FPS
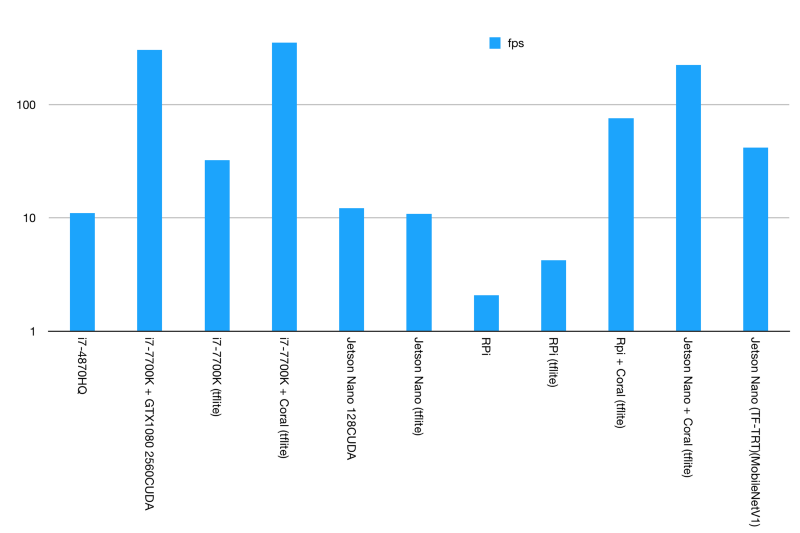
对数刻度,FPS
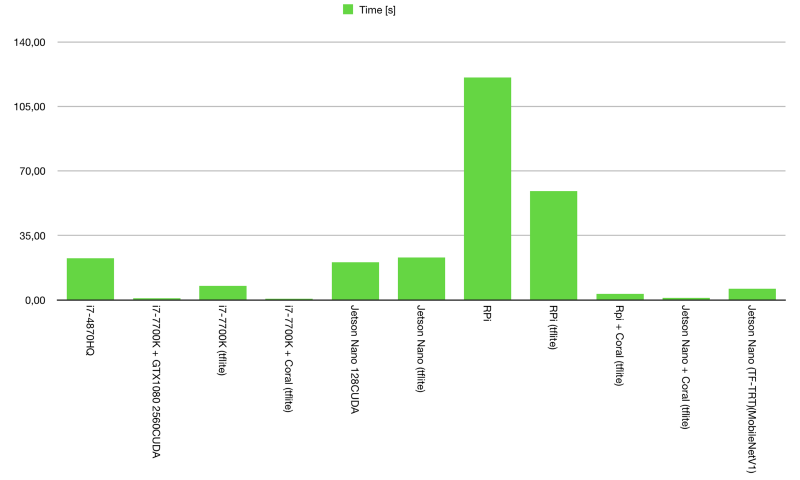
线性刻度,推理时间(250x)
Sam发现使用CPU的量化tflite模型得分是不同的,但似乎它总是返回与其它产品相同的预测结果,他怀疑模型有点奇怪,但能确保它不会影响性能。
对比分析
第一个柱状图中我们可以看到有3个比较突出的数据,其中两个2个是由Google Coral Edge TPU USB加速器实现的,第3个是由英特尔i7-7700K辅助NVIDIA GTX1080实现。
我们再仔细对比一下就会发现,GTX1080实际上完全无法跟Google的Coral对飚。要知道GTX1080的最大功率为180W,而Coral Edge TPU只有2.5W。
NVIDIA Jetson Nano的得分并不高。虽然它有一个支持CUDA的GPU,但实际上并没比那台2014年MBP的i7-4870HQ快太多,但毕竟还是比这款四核,超线程的CPU要快。
然而相比i7 50W的能耗,Jetson Nano平均能耗始终保持在12.5W,也就是说功耗降低75%,性能提升了10%。
NVIDIA Jetson Nano
尽管Jetson Nano并没有在MobileNetV2分类器中表现出令人印象深刻的FPS率,但它的优势非常明显:
它很便宜,能耗低,更重要的是,它运行TensorFlow-gpu或任何其他ML平台的操作,和我们平时使用的其他设备一样。只要我们的脚本没有深入到CPU体系结构中,就可以运行与i7 + CUDA GPU完全相同的脚本,也可以进行训练!Sam强烈希望NVIDIA应该使用TensorFlow预加载L4T。
来源:NVIDIA
Google Coral Edge TPU
Sam毫不掩饰的表达了他对Google Coral Edge TPU的精心设计以及高效率的喜爱。下图我们可以对比Edge TPU有多小。
Penny for scale,来源:谷歌
Edge TPU就是所谓的“ASIC”(专用集成电路),这意味着它具有FET等小型电子部件,以及能够直接在硅层上烧制,这样它就可以加快在特定场景下的推力速度。但Edge TPU无法执行反向传播。
Google Coral Edge TPU USB加速器
下图显示了Edge TPU的基本原理。
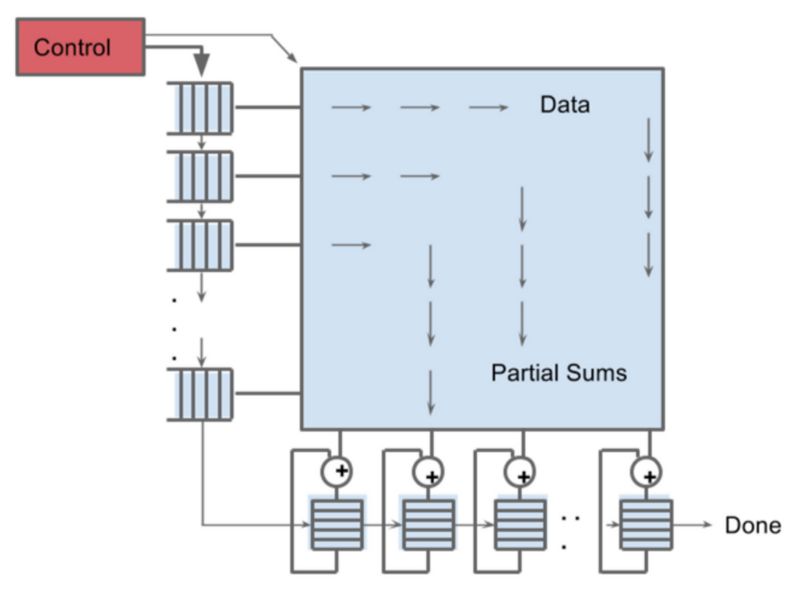
来源:谷歌
像MobileNetV2这样的网络主要由后面带有激活层的卷积组成。公式如下:
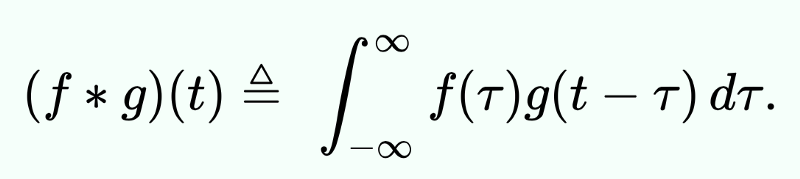
卷积
这意味着将图像的每个元素(像素)与内核的每个像素相乘,然后将这些结果相加,以创建新的“图像”(特征图)。这正是Edge TPU的主要工作。将所有内容同时相乘,然后以疯狂的速度添加所有内容。这背后没有CPU,只要你将数据泵入左边的缓冲区就可以了。
我们看到Coral在性能/瓦特的对比中,差异如此大的原因,它是一堆电子设备,旨在完成所需的按位操作,基本上没有任何开销。
总结
为什么GPU没有8位模型?
GPU本质上被设计为细粒度并行浮点计算器。而Edge TPU设计用于执行8位操作,并且CPU具有比完全位宽浮点数更快的8位内容更快的方法,因为它们在很多情况下必须处理这个问题。
为何选择MobileNetV2?
主要原因是,MobileNetV2是谷歌为Edge TPU提供的预编译模型之一。
Edge TPU还有哪些其他产品?
它曾经是不同版本的MobileNet和Inception,截至上周末,谷歌推出了一个更新,允许我们编译自定义TensorFlow Lite模型。但仅限于TensorFlow Lite模型。而反观Jetson Nano就没有这方面的限制。
Raspberry Pi + Coral与其他人相比
为什么连接到Raspberry Pi时Coral看起来要慢得多?因为Raspberry Pi只有USB 2.0端口。
i7-7700K在Coral和Jetson Nano上的速度都会更快一些,但仍然无法和后两者比肩。因此推测瓶颈是数据速率,不是Edge TPU。
来源:NVIDIA
-
芯片
+关注
关注
455文章
50816浏览量
423627 -
人工智能
+关注
关注
1791文章
47279浏览量
238499 -
英伟达
+关注
关注
22文章
3776浏览量
91104
原文标题:最新千元边缘AI芯片比拼:谷歌Coral和英伟达Jetson谁更厉害?
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
软银升级人工智能计算平台,安装4000颗英伟达Hopper GPU
解决验证“最后一公里”的挑战:芯神觉Claryti如何助力提升调试效率







 工商网监
工商网监
评论