 聊一聊聊天“机器人的落地及进阶实战”
聊一聊聊天“机器人的落地及进阶实战”
近年来,聊天机器人技术及产品得到了快速的发展。聊天机器人作为人工智能技术的杀手级应用,发展得如火如荼,各种智能硬件层出不穷。
本次公开课中,AI科技大本营联合电子工业出版社博文视点邀请到上海瓦歌智能科技有限公司总经理,狗尾草科技人工智能研究院院长邵浩老师,他将在3月21日的公开课中为大家讲解聊天机器人落地及进阶实战。
本课程将全面阐述聊天机器人的技术框架及工程实现细节,并对于聊天机器人的下一代范式:虚拟生命,进行了详细的剖析,同时,聚焦知识图谱在实现认知智能过程中的重要作用,给出了知识图谱的落地实践。
本课程适合工程一线的研发人员,可以通过本课程了解聊天机器人的实现细节。适合高校学生,可以通过本课程学习聊天机器人的技术框架及典型算法。
以下为公开课速记整理
邵浩:今天跟大家聊一聊聊天“机器人的落地及进阶实战”。我是来自深圳狗尾草智能科技有限公司的邵浩,现在负责公司人工智能研究院的工作,主要是做聊天机器人相关产品。

今天想跟大家聊的内容包括这几个方面,包括以下几个部分:
第一部分,跟大家讲一讲聊天机器人总体产生的背景和技术架构;
第二部分,会跟大家聊一聊聊天机器人在工程实现的方方面面,这里我会配合一些代码,跟大家解释一下它每个模块、每个功能是怎么实现的,希望大家听完这部分之后,可以自己动手去搭一个聊天机器人;
第三部分,想跟大家聊一聊知识图谱在虚拟生命中的应用及技术路径,并会简单介绍虚拟生命,也就是我们发现聊天机器人的种种问题之后,想着是不是有更好的办法去解决聊天机器人所面临的很多问题;
最后一部分,花5-10分钟时间跟大家聊聊工程落地的其他问题。
简单介绍就到这里,我们言归正传。
聊天机器人概述
首先介绍一下背景。大家现在对人工智能的感觉是什么样子?无论是AlphaGo,还是AlphaGo Zero,战胜人类最顶尖的围棋选手;还是Project Debater,一个参加人类辩论赛的机器人,在今年1月份创造了不俗的成绩;还是波士顿动力这种行云流水般的机器人和机器狗,它也是人工智能非常好的一个应用,而且像OpenAI曾经在去年DOTA2比赛中也很厉害。DeepMind最近在搞《星际争霸2》的比赛,人工智能正在突破一项又一项人类的想象空间,所以我们对人工智能现在有一个非常直观的印象是什么?人工智能是上天入地无所不能的,所以我们会觉得,无论是媒体中现在所说到的机器人觉醒,还是人类毁灭,就变成了非常自然的一个事情。
我们如果带着这样的感觉去看聊天机器人的话是什么样的呢?我们有什么样的使用感受?各位同学可能跟我一样,凡是有这个聊天机器人产品,我们大概用了1、2天,在新鲜感过去之后,就发现这个东西再也不会开了,或者再也不会跟它聊天了,到底什么原因造成这种现象?除了误识音、准确率不高之外,我们对这些问题还是很宽容的。但是我们上次在媒体上看到一篇报道——外国用户使用亚马逊的Echo音箱的时候发生了什么事?他晚上正在睡觉,突然这个灯亮起来了,然后冷笑了两声!这个太恐怖、太吓人了、太毛骨悚然了!如果是我碰到这种情况,在大半夜时这个音箱突然自己笑了,除了拔掉它的插头,把它从楼上面扔下去摔得粉碎之外,也没有什么好的办法解我的心头之恨,所以我们可以看到这个聊天机器人产品实在表现不佳。
说到聊天机器人产品为什么做得这么差?我作为一个从业者还是很宽容的,因为我知道聊天机器人的边界在什么地方,所以我在问聊天机器人产品的时候就在想:这个聊天机器人产品可能这个地方技术有问题,所以我不去问或者尽量避免去问它。但是普通的用户对聊天机器人产品是没有那么宽容的,我花了那么多钱买这个聊天机器人音箱,我希望的是可以跟我自然对话的机器人,但是这个达不到之后,他就会埋怨开发者。
用户一般对我们这个产品的宽容度真的是很低的,他们觉得你们技术做得真的很差,其实我们行业从业者们觉得很委屈的,这个事情不能怪我们,是根据技术现在发展的程度所决定的。像微软亚洲研究院副院长周明老师曾经说过,语言智能是人工智能皇冠上的明珠,如果我们把这个美女当作我们所有的技术的话,人工智能就是她头上的这顶皇冠,而语言智能就是皇冠上的这颗明珠。什么意思?自然语言处理本身就是非常难的事!
我举个简单的例子,大家就明白了,比如我说一句话叫“明明明明明白白白喜欢他,但是他就是不说。”我问同学们,是谁喜欢谁?是谁又不说?这句话很难。我再说一句话,比如“我没有看见他拿了你的钱包”,如果我们在不同的语气、不同音调和重音的情况下,这句话的含义是完全不一样的。比如说“我没有看见他拿了你的钱包”(重音在“看见”上),这个意思就是我没有看见他拿了你的钱包,我可能听别人说他拿了你的钱包,但是我没有亲眼见到,或者“我没有看见他拿了你的钱包”(重音在“钱包”上),就是说他拿了你的别的什么东西,但是他没有拿了你的钱包。
所以我们在理解一句话时,它其实是跟上下文,跟说话者的世界观、说话者的情绪、所在的环境、听者的世界观都是非常相关的,一句“你好吗?”或者一句“吃了吗?”在不同人物中的对话的含义是完全不一样的,所以NLP技术本身就是非常难的事,
当然,还是要做,为什么要做呢?
我曾经在其他的报告也说过,微软在2016年就提出这样一个口号,叫“对话即平台”,它认为语言是人类交互最自然的方式,从远古时代开始,人类就用语言进行狩猎时的互相协作、互相呼应,在自己丰收时,在村子里跟大家八卦八卦,促进大家的友谊,所以语言是人类最自然的一种交互方式。但是受限于硬件和软件,我们之前跟电脑基本上是用键盘和鼠标进行交互的,所以我们现在深度学习、大数据、GPU的硬件提升之后,可以直接使用语言跟机器进行交互了,这也是为什么2016年微软提出“对话即平台”的这个概念。
聊天机器人生态技术体系
我们看一下聊天机器人怎样分类的,它可以分为三个大的生态体系:一是框架,二是产品,三是平台。
怎么理解?Echo是一种产品,Apple的Siri是一种产品,公子小白是一种产品,IBM Watson是一种产品,小冰也是一种聊天机器人产品。这些产品有不同的展现形式,比如Siri的载体是手机、微信或者微博;我们有一款音箱,它的载体是它的硬件,这些产品一定要有一个载体去进行承载,这个载体就叫做聊天机器人的平台,这个平台可能包括像微信、LINE、MSN等等这样一些平台。我们可以理解为是利用这个框架来造这个产品的一个平台,国外的有Alexa、LUIS、Wit,国内有一些比如像ruyi、UNIT都属于聊天机器人的框架。
我们再往产品这个方向看,产品主要分为两大类方向,第一大类叫被动交互,第二大类叫主动交互。所谓被动交互就是我问它答,我跟它说一句,它跟我说一句,这叫被动交互。我们刚才讲到了被动交互,被动交互其实分为好几种。
聊天机器人的工程实践(代码解释)
接下来的代码实战环节,会跟大家从闲聊、到任务对话、到问答,跟大家完全梳理一下聊天机器人的所有分类。很多聊天机器人都做不到主动交互,因为它需要很强的知识图谱知识和场景设计,比如在你心情不好时给你推荐一个什么音乐,这是主动交互方面,现在做得不是特别好。安利一下,我们出了一本书,叫《聊天机器人技术原理与应用》,感兴趣的同学们可以看一下。
现在开始进入实战环节,我从最简单的开始,不需要有任何知识储备,就可以去做一个聊天机器人,一直到我们自己去搭一个聊天机器人的框架,并且利用Python去实现这个聊天机器人。
快速上手
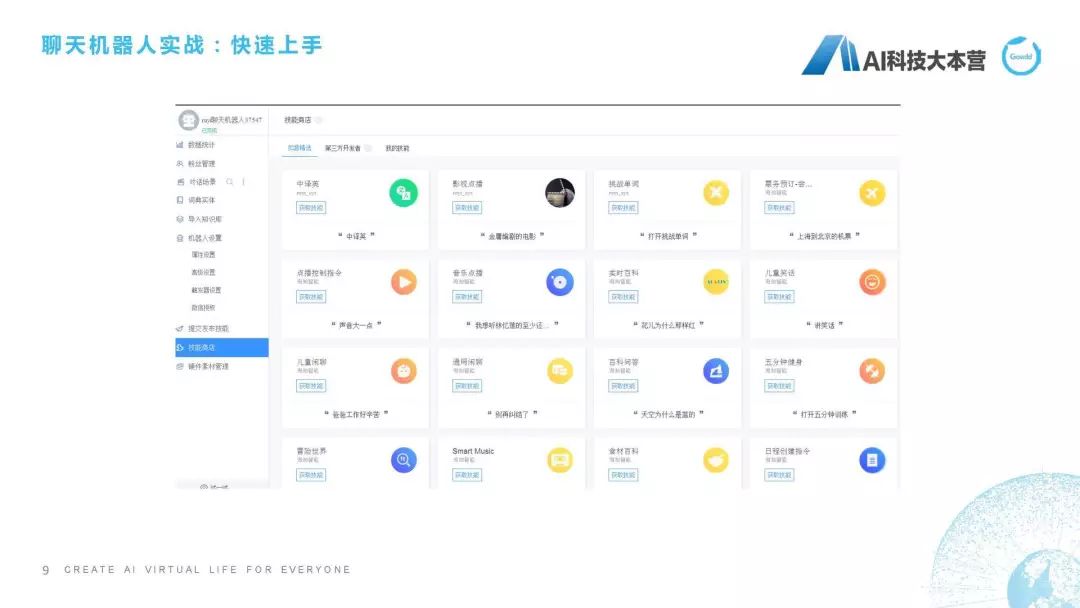
第一步带大家看一下这个“快速上手”。我给大家准备的是这个例子,大家可以看一下我的网页,我给大家准备的例子是一个叫ruyi的平台,它的网址是ruyi.ai,打开这个网页以后有一个叫“魔戒”的技能插件工具,这个时候它上面有一句话叫“我要产机器人”,登陆一下,我们就可以利用它的平台去造一个机器人了。这里可以看到我现在建了很多聊天机器人,我可以新建一个,为了节省时间,我直接管理我现有的聊天机器人。可以让机器人具有不能的技能,在技能商店里可以让机器人拥有中译英的技能、影视点播技能、挑战单词技能、儿童闲聊的技能,点击“获取技能”,它就可以直接部署,部署之后我就可以直接跟它聊天了,这个功能已经嵌入进去了。还有一种,是我们可以在对话场景里去建立一些新的意图,这个意图相当于你配了一些语料,然后它回答一些特定的语料,比如我这里建立了一个新意图叫“寒暄”,这个意思就是当用户说“Hi”或者“Hello”或者“你好”的时候,机器人回答是“Hi”/“Hello”/“你好,好久不见。”这个ruyi机器人如果我们按照这个技能去设置一下,我们可以试一下,比如我说“Hello”,它就会说“你好,好久不见”,我再说一句“Hello”,它会随机在这两个回复里选择一个进行回复。其实大家不需要任何基础知识,就可以去造一个自己的聊天机器人,我们是利用ruyi.ai的平台去做这个事情,这是最简单的操作方法。
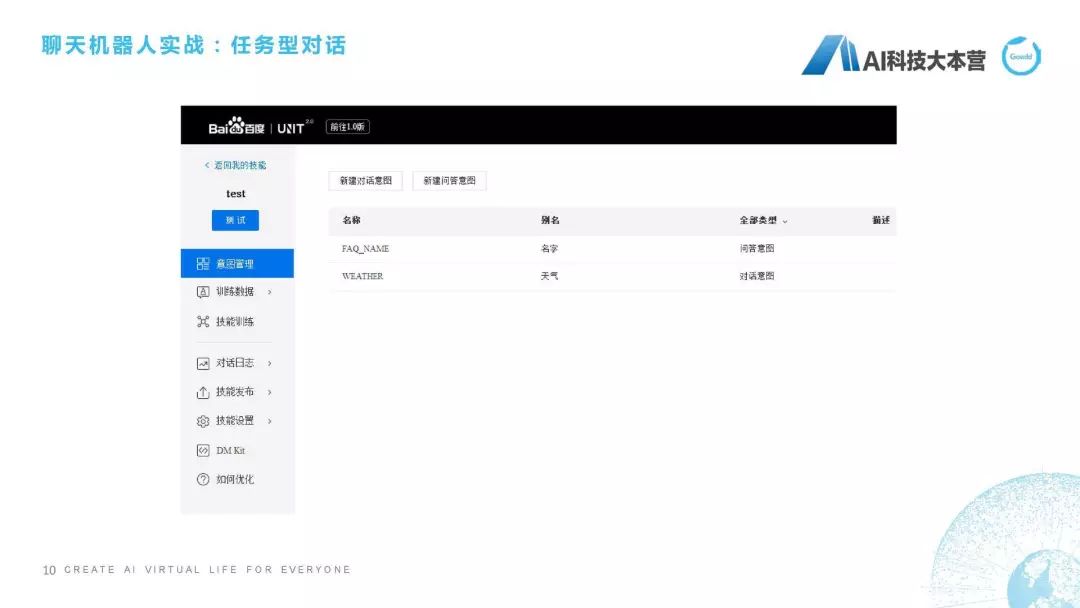
接下来,我们再讲稍微难一点的一个平台。这个平台叫做百度的UNIT,百度的UNIT现在做得很好,我们去看一下这个百度UNIT怎么用的,网址是unit.baidu.com,这个很漂亮,鼠标移动过去有一些很炫的效果。进入UNIT之后,还是为了节省时间,我不直接去新建一个机器人了,我直接在我今天下午建好的机器人上进行一个测试,我建了一个叫“测试”的机器人,它同样跟ruyi一样可以添加一些技能,比如我可以添加打电话、电影、天气、机票、闲聊等等这样一些技能,而且它还有一个比较好的功能是什么?我可以自定义去配一些技能,比如在我的技能里可以配一个叫test的功能,我在这个test里设置了一个“天气”,就是问天气的意图、对话。
怎么去做这个事呢?讲这个平台时,我为什么说它比刚才的那个ruyi稍微难了一点?它这里面需要牵扯到我们对槽位的理解。我们先不解释什么叫槽位,我们先看一下我设定这个意图是怎么设定的。我设定这个意图叫“weather”,它的别名是“天气”。它怎么做呢?我设计一个词槽叫“city(城市)”,也就是说当我在问机器人一个问题时,我必须把“城市”这个词槽的信息告诉机器人,如果我没有告诉机器人的话,它就会自动的反问说“你在哪个城市?”这个时候我们如果去这样设置的话,在我说到比如“今天上海天气如何”时,它就可以说“现在播报上海的天气情况”,它会在会话过程中检查我是不是已经有了“ctiy”这样一个槽位。这就是我们讲了非常简单的两个平台。
刚才我提到为了用UNIT需要去了解这个槽位是什么意思。槽位是什么意思?我再跟大家详细解释一下。我们看一下这样一个对话,比如说我现在在办公室,跟大家讲这个话题,我很困,我跟这个聊天机器人说“能不能帮我订一杯星巴克的咖啡送到办公室”,聊天机器人可能回复说“好的,点你最爱喝的大杯美式可以吗?”它其实就是个任务型对话,任务型对话就是为了满足特定的任务指标,比如订票、订咖啡、订餐。在任务型对话里,一般会牵扯槽位提取和填充,槽位就是在这个任务里所需要的这些关键信息。
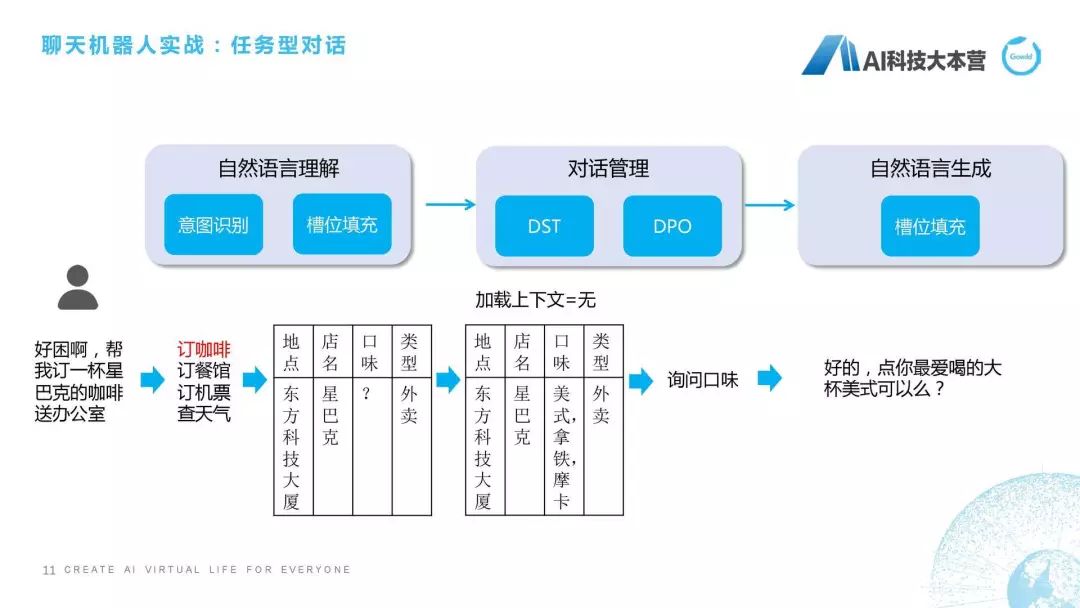
我们看一下它的处理流程,当这句话进来之后我们首先会在NLU自然语言理解部分做个意图识别,可以用规则的方法去做,可以用分类器的方法去做,也可以用现有的深度学习方法去做,这都没有问题的。如果我们判断这句话的意图是订咖啡,接下来要做的什么事情?接下来要做的就是把咖啡需要的这些槽位,如地点、店名、口味、类型填进去,这个方法里面又牵扯到很多自然语言处理的技术,这里就不是我们这次课的重点关注内容,我们只关注我可以在这个句子里去抽取到这些信息。比如说地点,它是东方科技大厦,是根据我GPS定位,定位到我是东方科技大厦,店名是星巴克,类型是外卖。因为我说的是“帮我订一杯送到办公室”,并没有说口味,机器人在这一步时并不知道我想要什么口味的咖啡,这时就有问题了,不知道什么口味怎么帮你点呢?这个对话现在进入到我们所说的“对话管理”模块,对话管理分为两部分,第一部分叫DST,第二部分叫DPO(以前我们叫DPL)。DST的意思就是“对话状态跟踪”,DPO的意思是“对话策略优化”。DST所做的事情就是跟踪它的状态,并且看一下有没有上下文,可能他在上文里直接说“我想喝美式”,这就不需要再去猜测用户口味了,如果我们发现这个上下文是没有的话,我就需要去猜测他的口味到底是什么,这里我直接写了,它可能根据用户之前点的咖啡的偏好,我直接排了个序,美式第一,拿铁第二,摩卡第三。这时它就需要做一个决策了,这时是要反问用户喝什么口味呢?还是直接给用户回复一句话,帮他点一个默认的咖啡呢?这里就需要跟产品的设定来进行回复。
我们不希望聊天机器人在功能型对话中有太多的多轮交互,我们希望一句话就能够理会我什么意思。就跟皇帝和太监一样,皇帝一个眼神,这个太监就知道马上要做什么事情,这个是最棒的。但是聊天机器人没有那么聪明,我们尽可能的让产品设计得比较聪明。那怎么设计?比如这句话就是设计场景,我们知道用户最喜欢喝美式,这句话可能就说“那我点你最爱喝的大杯美式可以吗?”这一方面询问了用户的口味,另一方面又节省了对话轮数,这是任务型对话的处理流程。当然,最后自然语言生成时也需要用槽位把这句话生成出来,这是我们所说的任务型对话的基本概念。理解这个东西,就理解了我们在UNIT进行天气槽位的填充。
聊天机器人三种不同形态的实现
接下来我们开始介绍聊天机器人三种不同的形态是怎么去实现的。检索式机器人最简单的做法是什么?比如用户对这个产品说“你穿的衣服好漂亮”。机器人会回复“谢谢你的赞美”,它一般是怎么做的?当你说“你穿的衣服好漂亮”的时候,它会在一个很大的语料库里去搜索,搜索这里面哪一句话跟我现在问的问句是最接近的,然后把最近这句话的回复直接回复给用户,这个看起来是不是很简单?所以其实如果你掌握了检索式方法的话,就完全可以做一个非常棒的机器人。只要你写足够多的语料,用更好的相似度算法,这个聊天机器人就会表现得非常好。但这个情况只出现在单轮的过程中,如果在多轮的情况下,检索式的方法肯定就挂掉了。这里最关键的是什么东西?最关键的是匹配。
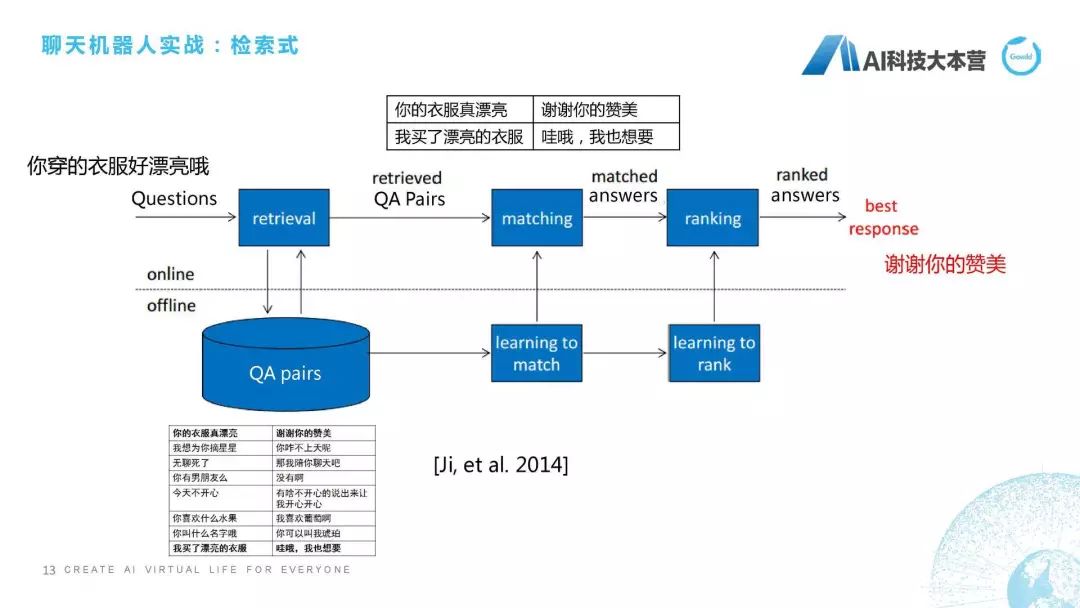
我们再看一下它基本的技术流程是怎么走的,比如我说刚才那句话“你穿得衣服好漂亮”。它是作为一个问句,我们就需要做一个retrieval,这个retrieval是搜索,我们从大量文件语料对里去搜索跟我这句话最接近的一些句子,并且把这个候选集给筛选出来,有了候选集之后,我们就会做一个排序,这两句话到底哪句话跟我这句话的相似度最高,然后我再把它这句话的回复来回复给用户,这是它基本的检索式的流程,这用2014年一篇论文中提到的经典模型,我就直接拿来用了。
(1) 基于文本相似度
接下来开始介绍基于文本相似度、基于语义相似度以及基于深度学习的检索式方法,也就是说对于检索式方法,我们现在这里说3种比较基本的技术。

第一种,基于文本相似度的方法。什么叫文本相似度?举个例子“你穿的衣服好漂亮哦”,“你的衣服真漂亮”这两句话,大家直面上感觉非常相似,它怎么相似?因为它的字、它的词有很多重合,这就是文本相似度的直观感受。我们知道文本相似度算法有很经典的比如边际距离、TF-IDF、BM25,这种都是非常经典的算法,我这里对算法部分就不做更多深入的描述了,大家如果感兴趣的话,推荐大家去听一个课程CS 224N,这个课程是斯坦佛大学Christopher Manning教授零几年上的一门课,应该就是叫NLP(自然语言处理)这门课,它对经典的自然语言处理算法都做了非常好的解释。
那么我们一般的做法是,这种相似度算法一般是用到字符串匹配,我们知道字符串匹配的速度一般非常慢,但是我们可以借助相似度的检索引擎提升它的搜索效率。这里有两个,一个叫ElasticSearch(ES),另一个叫HNSW,如果感兴趣的话,大家可以在后面课程的PDF、PPT里去看一下这两个项目。

接下来实战里是用这个基于ES相似度检索引擎,给大家实现一个检索式的聊天机器人,我这里列的基本是核心的代码,就不在这里给大家演示了,PPT可能看得更清楚一点。ES怎么去用?这个很简单,我们直接去Import这个ElasticSearch,首先要配置一下ES的信息,信息包括什么?它的主机IP,比如说我这里是172.27.1.203,端口号是9201,然后数据库名称是什么?我们把它起了一个叫similarity_chat,它的表名称叫什么?比如我们起个名字叫“qa_corpus”。
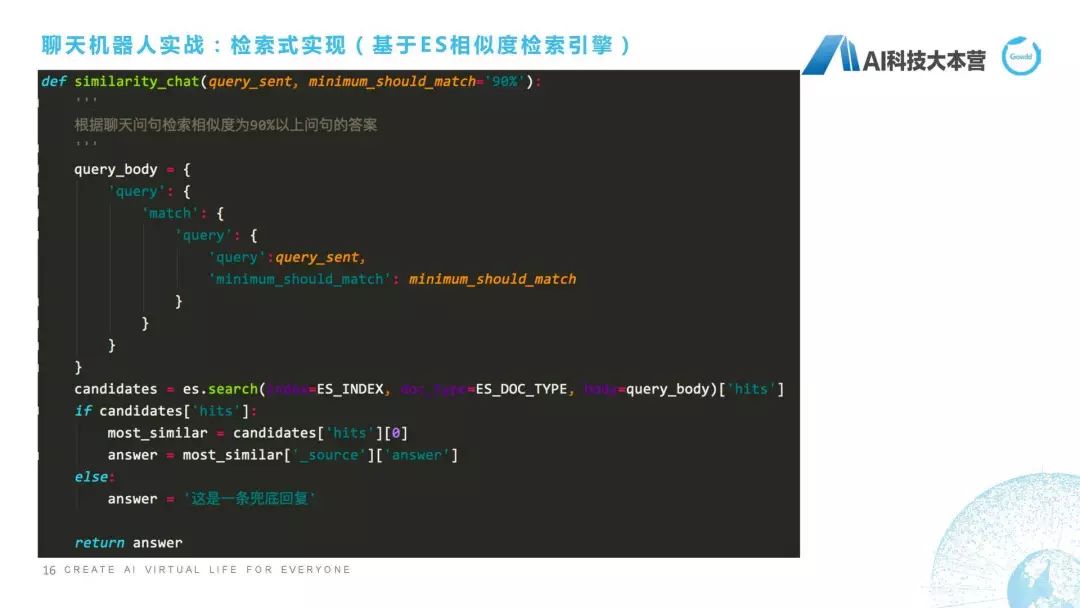
接下来就是正常的流程了,比如我们首先要初始化一个对象,小写的es这个对象,这个对象里所有信息是来源于我们刚才配置的es信息,这里面是端口号和IP。接下来我们想往这个es里去添数据,因为我们想把这样一批数据添加到es里去,13页里这些数据,怎么去添呢?这里我们define一个方法,这个方法叫insert_one_data,就是我们插入一条问答语料,怎么去插入?一个问答语料包括两部分,一个叫Query,一个叫Answer,就是一个Q,一个A,然后我们会调用一个es的index方法,这个index方法其实是直接封装好的插入语料的方法。它是怎么去做?如果这个数据库不存在的话,它会直接生成一个新的叫这个名称的数据库,并且建立一个表叫“qa_corpus”。然后对于每一条数据,除了Query和Answer,这是两列数据,一个Query,一个Answer,还自动生成一个id,相当于我们最后生成的数据是三列数据,第一列是Query,第二列是Answer,第三列是id,这是我们预先存了这样一些句子。
接下来要做什么事?接下来要做检索,我们来了一个问句之后,定义了一个方法叫“similarity_chat”,我们对这个问句进行检索,跟我刚才数据库里哪一句话最接近,然后我们人为设置了一个90%的阈值。相似度为90%以上的答案返回作为最好的候选答案。Body的格式就是query还有这个minimum_should_match,就是它90%的值。然后我们用es这个search的方法去找到它的候选集,找到候选集之后去比较这个阈值,如果所有的阈值都低于我们设计的90%的话,它就直接返回一个兜底回复,比如else,answer这是一条兜底回复,然后return answer,这是我们的整个实现方法。
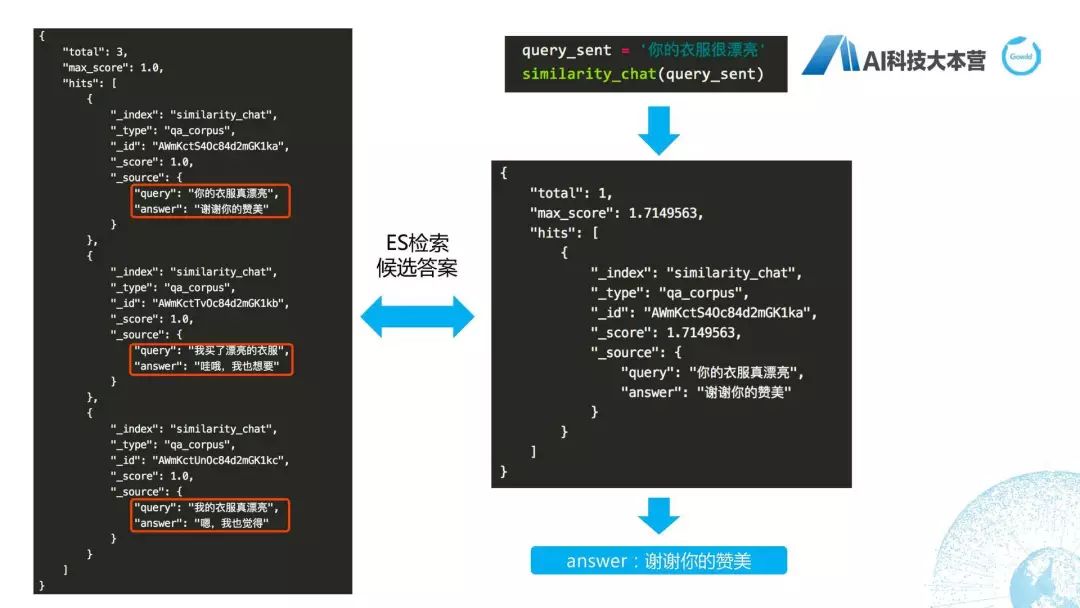
具体流程在上面看一下,首先,左边这个图是我们插入的三条语料,插入三条语料的Query和Answer分别是“你的衣服真漂亮”、“谢谢你的赞美”,然后还有这两句。我们现在有一个query_sent是“你的衣服很漂亮”,我们调用刚才我们已经设定好的“similarity_chat”这个方法把这个query_sent灌进去,然后检索出最好的句子是第一个。也就是说我们其实在这里直接利用了ES默认的相似度的分值的计算方法,这个计算方法在这里其实可以跟大家说一下,大家可以在里面去改自己的计算方法,因为我们知道匹配度的分值是可以自己去做很多的优化的。所以,这里面大家可以根据自己的实际情况去调整分值的计算方法,然后做一个比较个性化的自己的检索引擎,最后得到这个答案是“谢谢你的赞美”,整体的用ES作为检索式的方法就简单跟大家介绍到这里。

简单总结一下,基于ES相似度检索引擎的优势在于什么呢?文本相似度它本身是具有一定泛化支持的,比如你加一个语气词“啊”或者“哦”,或者加一个逗号、加一个标点,它都可以在相似度检索方面起到比较好的泛化效果。当然,这个泛化它本身又是一个比较重要的一个可以单独拎出来讲的模块。比如我们现在常用的方法叫机器翻译,我们可以用机器翻译的方法对大量语句进行泛化的设计,使我们的聊天机器人可以支持更多泛化语句。第二点优势,ES里自带的BM25算法有很多权重可以调整,在短文本的情况下比边际距离还要合理得很多。
劣势也很明显,我举两个例子,大家就很明白了,比如说“你好漂亮”、“我觉得你很好看”,大家看看这个文本相似度,它里面哪几个字是一样的?“你”是一样的“好”是一样的,其他字都不一样,语义相似但是文本字符不是很相似的情况下,这个文本相似度算法可能就没有那么好,但它语义是非常相似的。第二种情况是否定词怎么办?比如“我喜欢你”和“我不喜欢你”它的意思是完全相反的,但是在文本相似度检索时,如果我们没有对否定字进行限制,它这两个得分是非常高的,“我喜欢你”和“我不喜欢你”的得分是非常高的,这个情况就非常难以应对。我们一般的处理方法是什么?第一种方法是规则,比如说我可以设定一些否定词的过滤规则,遇见“不”的情况下跟原有句子是相反的意思,或者怎么样利用文本语义相似度的方法来去进行相似度的检索,我们接下来跟大家讲第二块,就是基于语义相似度怎么去做。
(2) 基于语义相似度

第二种,基于语义相似度。语义相似度一般来说是三步走,我这里列的三条是三步走策略,第一步,先要把一个句子中单词变成向量化的表示,向量化表示的方法实在太多了,而且有很多人讲过专项的talk,这里我就不讲嵌入式怎么做的了,如果感兴趣的话可以读一下Word2vec这种原始论文,或者看一下我们现在这种ELMo、Transformer、Bert这些语言模型的动态词向量是怎么做的。词向量这块我就不去解释了。词向量的输出就是把一个单词变成一个向量,比如变成一个200维或者300维的向量,这是单词的向量表示。
第二步是做句子的向量表示,比如刚才我举的例子“我喜欢你”它是三个词,我、喜欢、你,我们把这三个词的向量拿过来之后怎么把句子的向量做出来,这就需要有一些方法,比如加和平均,比如向量极值,比如最近用得比较多的FastText、Skip-Thought、Quick-Thoughts,这都是非常好用的一些方法,大家可以具体的情况去把句子的向量表示出来。其实可以用一些预训练的向量,比如腾讯应该有一个预训练好的大规模语料上的向量,大家可以拿来用。
第三步是计算向量距离,我们有了两个句子的向量之后,下一步就要去计算它的相似度,也就是它的向量距离。一般的做法可能采用欧氏距离或者余弦相似度,也就是说我们得到一个分值。或者基于深度学习的一些方法,也是延续着刚才我们PPT里讲计算文本相似度的语义相似度的方法。在匹配算法方面,我这边只列了一些最早提出来的或者最经典的算法,如果大家感兴趣的话,这后面还有非常多论文可以去读,包括最近也新出很多这方面的论文。
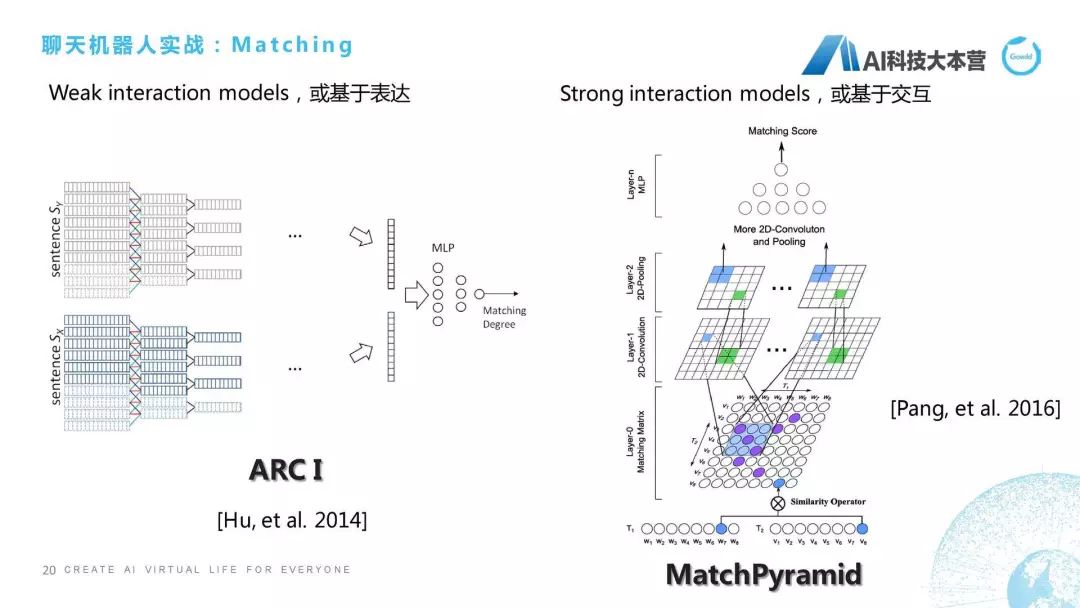
我们从最早的讲,2014年华为的诺亚方舟实验室这篇论文中提出两种算法,一种算法是基于表达的,一种算法是基于交互的。两者最大的区别在于对于句子算相似度的时候,基于表达的算法是对这两个句子分别进行卷积、池化,进行向量化之后通过多层感知机得到它的匹配度。像MatchPyramid这种算法就是基于交互的,这种算法一开始就把两个句子给揉起来了。我们相当于一种是分开去算,两个兄弟先分开,然后最后再分家产;还有这种两个兄弟先揉在一起了,揉成一个矩阵,这里面有一些相似度的Operator,大家看原始论文时,Operator是有两种,一个是点乘,一个是最大化。我们把这个句子里面的比如这8个词,每一个词都进行一个相似度的操作,就变成了8×8的矩阵,然后在此之上我们做卷积、池化这样的操作,通过最后的多层感知器得到它最后的分值。所以基本上只有这两个方向,一个叫基于表达的Matching方法,一个叫基于交互的Matching方法。大家感兴趣的话可以深入的去看一下论文。
(3) 基于深度学习
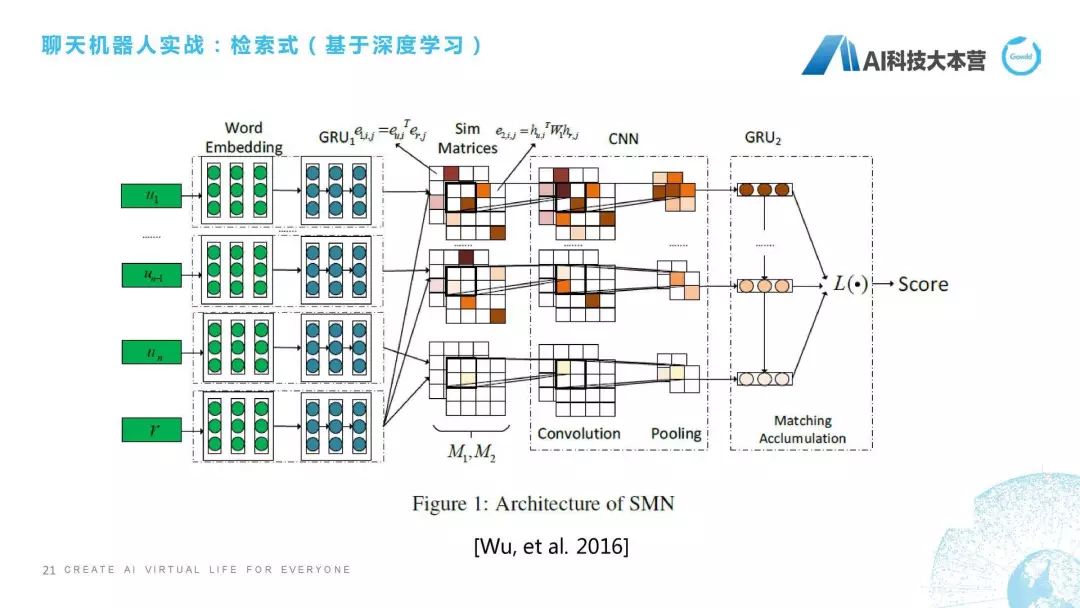
第三种,检索式还有一种是基于深度学习的检索式方法。这个我选了一篇比较经典的论文,跟大家简单讲一下它的思想。微软小冰团队在2016年提出一个方法,它不仅考虑词级别的,还考虑句子级别的相似度。什么意思呢?简单解释一下,我们这里有4个句子:u(1)、u(n-1)、u(n)、r,中间还有很多句子,我们假定它是4个句子,它现在想算u跟r相似度,怎么算呢?它会把每个词做个嵌入,也就是做向量化,然后把这个词跟r的这个词直接做点乘,也就是得到M2这个矩阵,得到这个矩阵之后通过对句子做GRU,它最后得到的隐状态我们做一下余弦相似度计算,得到的是M1这个矩阵,所以M1和M2这两个矩阵分别代表词和句层面的相似度,再往后就是通过CNN,还有一个GRU,最后得到一个Score。这个就是我们有一些基于深度学习的检索式方法,我也不深入进行介绍了。刚才已经跟大家讲完了基于文本相似度的、基于语义相似度的、基于深度学习的检索式方法。
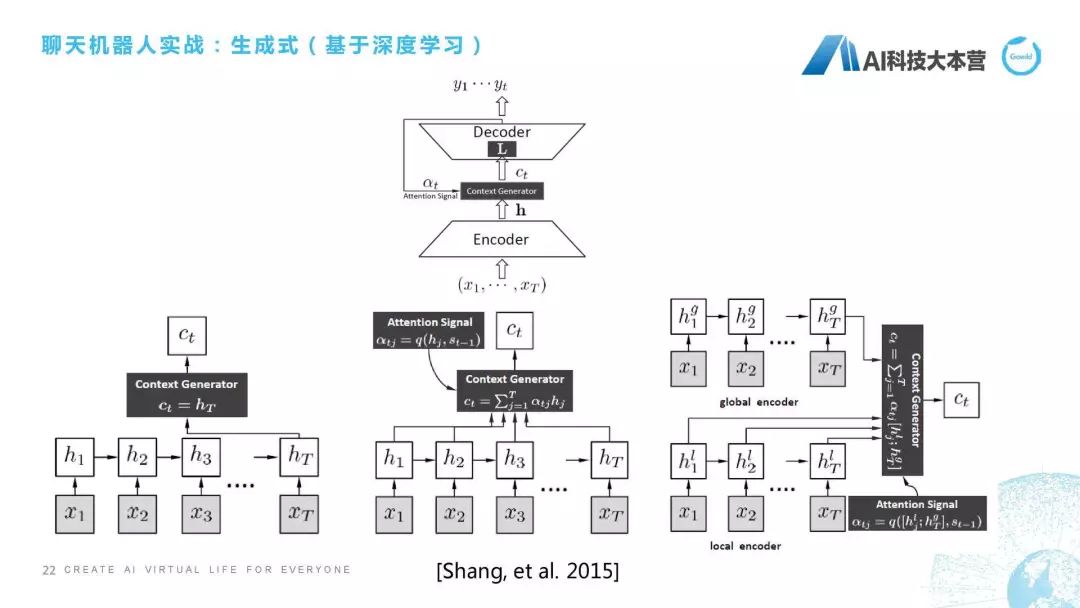
(4) 基于生成式的深度学习方法
第四种,跟大家聊一下基于生成式的深度学习方法。这是最早一篇论文,应该也是华为做的一篇论文,他们当时做的是怎样通过一句话直接生成它最后的这个回复,就是通过x(1)到x(t),直接生成y(1)到y(t),他们提出三种不同的方法。有一个是直接从这个隐状态得到它的context,还有一种方法是里面加了attention,采用加权的方式利用这个attention来得到最后的句子,还有一个是有一个contextAttention,还有一个词层面的Attention,它们称之为是local和global这两个Attention生成的回复。在这后面也出现了很多生成式的方法,因为这个talk是基于实战的,所以我们对理论方面不做过多的深入解释。
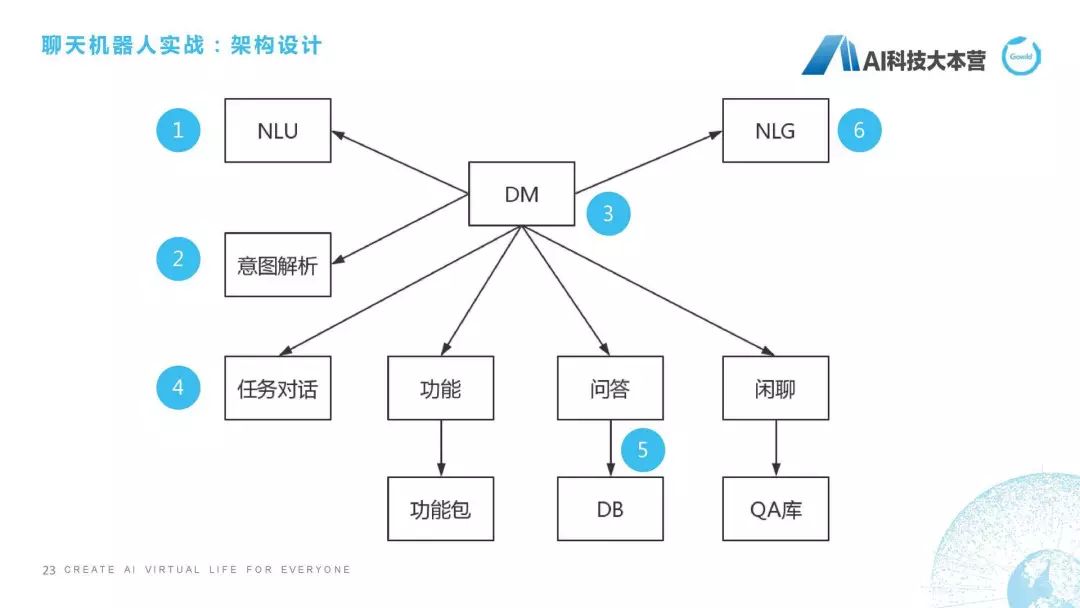
架构设计
最后来到最复杂的一块了,如果我们想从0到1利用自己的Python代码去创造一个聊天机器人,应该怎么去做?第一步,要先把架构给设计出来。这个聊天机器人的架构应该分几个部分,我们肯定是要用Python去写一个DM(对话管理)这个模块,然后这个模块会接收自然语言理解(NLU)的一些信息,同时,它会对句子进行一个意图解析,同时它会根据意图解析的结果选择一项功能,比如它是任务对话,还是功能对话,还是问答,还是闲聊,它有不同的处理方式,最后回复的时候我们还有一个NLG的模块,这就是整个聊天机器人简单的一个架构。

接下来这个序号是我要跟大家把这几个模块全过一遍:第一个,NLU,第二个,意图解析,第三,DM,第四,任务对话,第五,问答,第六,NLG。为什么不讲功能和闲聊?功能假定可以直接使用ruyi、UNIT的技能包,我们这里面就不做开发了。我刚才也讲过了闲聊,我们直接用检索式的方法做闲聊,我们用很多语料库直接做检索式的闲聊就结束了。这是我们说的架构设计。
NLU
第一点,NLU怎么做。让大家失望了,NLU里没有代码,为什么没有代码?因为很多开源的项目在做NLU的事情,NLU其实非常多的模块,至少我们现在用的模块就有十几、二十个,这里包括什么?分词、词性标注、依存、情感分析、实体链接、实体发现、语义消歧、主体识别、句子有效性判断等等,这个并不是一节课能讲完的。但我建议大家,如果你真的想以简单的方式去实现一个聊天机器人的话,我们为什么有好的东西不用呢?Jieba分词是很好的一个开源项目,中科院还有一个NLPIR,哈工大有一个LTP,斯坦佛有CoreNLP,我们还有最经典的NLTK的包,还有HanLP、AllenNLP。在NLU这块如果自己做的话实在是非常烦,比如分词、依存自己做的话,这个时间就花费得太多了,最好的办法是我用别人的东西,我去加一些自己的个性化,这就是我NLU所要跟大家讲的内容。
意图分类
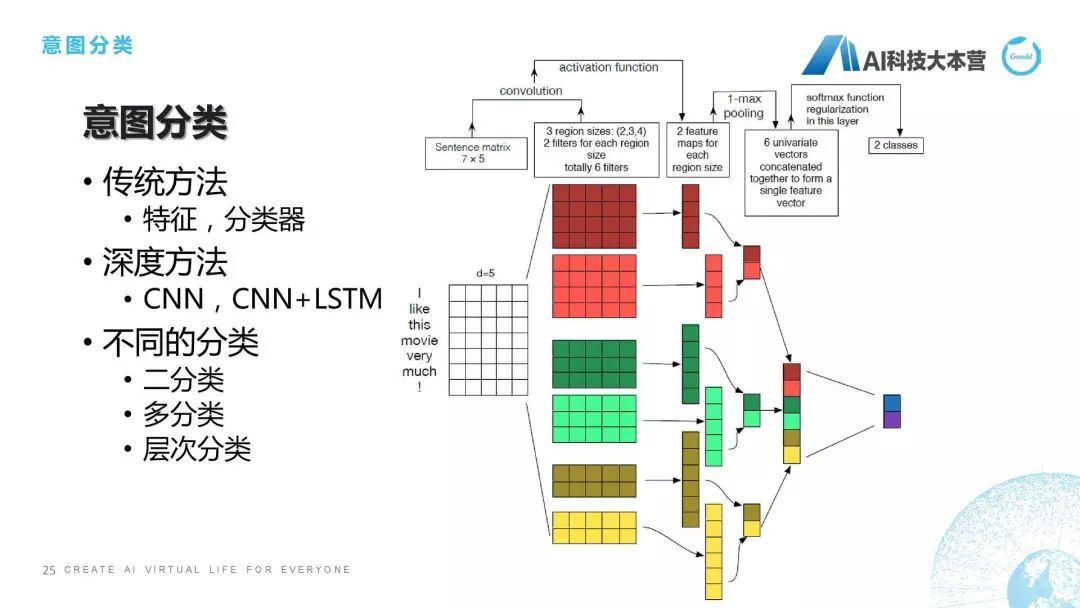
第二点,意图分类。想跟大家聊一下意图分类最容易实现的方法,整个方法的分类其实是有几种的,比如:传统方法,传统方法里面我们可以用特征,用一些分类器,然后直接对这个意图,比如我们用决策树或者SVM直接对句子进行分类。当然还可以用深度方法,比如CNN或者CNN+LSTM来进行分类。右边这个图给的就是这样一个深度分类的方法,它是对一个句子进行了一个embedding之后,I是一个单词,它是一个5维的向量,这是一个举例,然后它每个词都有一个向量,这个矩阵拿过来之后,我们就会有一些卷积、池化的操作,最后得到的是二分类的一个结果,这也是利用深度学习的方法去做的。但是我们在工程中还需要考虑什么呢?还需要考虑我们到底是二分类、多分类,还是层次分类。二分类很简单,1和0。多分类也很简单,比如情感里面有“正中负”。层次分类就比较复杂了,比如我们的产品里共有五层分类,300多种意图,所以我在做的时候,用什么方法才能保证它有比较高的RECALL。这就是我们在工程中所需要做的问题,其实是很复杂的事情。
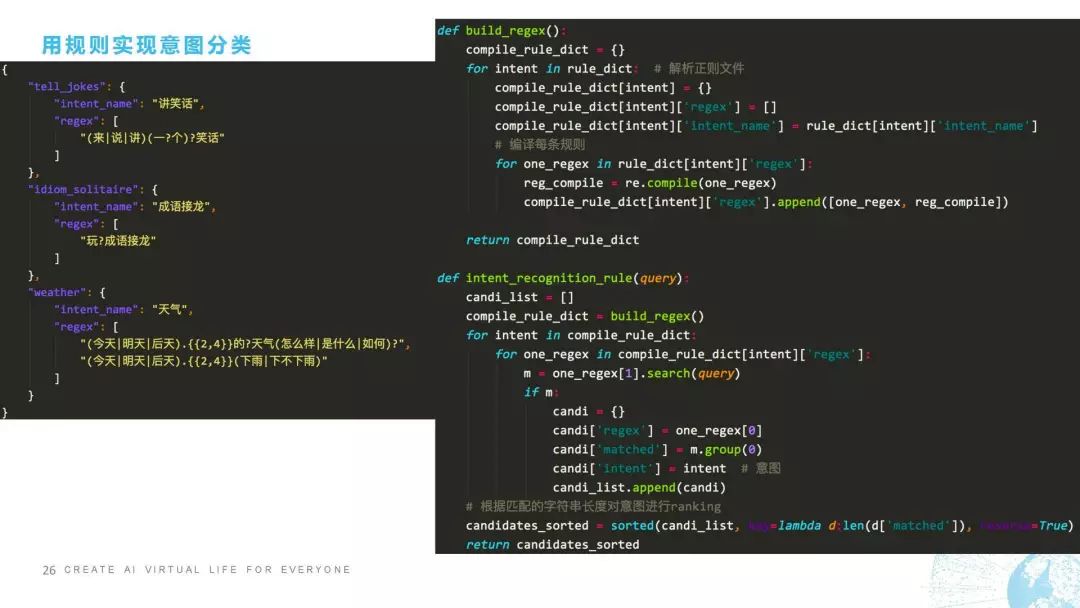
接下来我跟大家聊怎样用规则方法实现意图分类,用规则方法实现意图分类是非常准确的,但是它缺点在于我们要对每一个句子都进行规则的覆盖,而且当规则实在是太多的时候模型就会变得非常难维护,这是它的缺点。我们来看一下规则怎么去做,比如我这里举了一个事例是三种不同的意图,一个是“讲笑话”,一个叫“成语接龙”,还有一个叫“天气”。它所对应的规则是这样写的,比如“来一个笑话”这可以覆盖,“说一个笑话”可以覆盖,“讲笑话”也可以覆盖,“说笑话”也可以覆盖,这是一个规则,剩下的是同理。
怎么去做呢?我们看一下,右边有两个函数,第一个函数叫build,第二个函数叫intent_recognition。这个函数的作用是正则编译,正则编译大家应该也很清楚,我们对正则表达式进行预编译的话,可以有效加快正则的匹配速度,这个是编译,我就不讲了。第二个是在意图分类的上面,如果有query进来之后,candidate_list一开始是空的,然后我们把正则编译之后,从正则里面去选择正则对这个句子进行匹配,匹配之后我们会对匹配到的字符串的长度对意图进行ranking。也就是说它可能匹配到不同的意图,这个时候我们就需要根据它匹配的字符串的长度来对意图进行排序,最后把所有的candidate进行排序之后输出,这是我们在用规则实现意图分类时的一段代码。
神药:fastText
如果大家不想那么麻烦,还有一种包治百病的神药叫fastText,是在2018年广泛地被工程界所采用的一种分类方法。当然,现在这个方法被Bert和ELMo、Transformer这种更先进的算法所替代,也不是超越吧,大家还是一起做,有时做一些Stacking方法时去用,我们也会用到Bert或者新的GPT这种算法。但是fastText本身对意图分类的效果是非常明显的,而且它由于是基于字符子串的,所以它的性能也非常高,它不仅速度快,性能也非常高,所以在2018年我们笑称fastText是“包治百病的神药”,这个神药对工程界的分类起到非常大的促进作用。

我们看一下fastText怎么用,很简单!它的代码是非常简单的,我们只需要准备带有分类标签的数据集就行了。分类数据集这里是已经分好词的,比如这句话的label是weather,这句话的label是music,这句话的label是news,我们准备了几万条的数据集,把它分为测试集、验证集、训练集,之后我们就import fasttext,然后定义一个训练函数,定义一个预测函数,训练函数的话比如直接用train_supervised就行了,然后我们还可以算它的precision,recall还有F1,这是训练。用的时候怎么用?我们把model提出来,然后去predict这个sentence的label,然后return这个label就结束了。fasText是非常好用的一个算法。
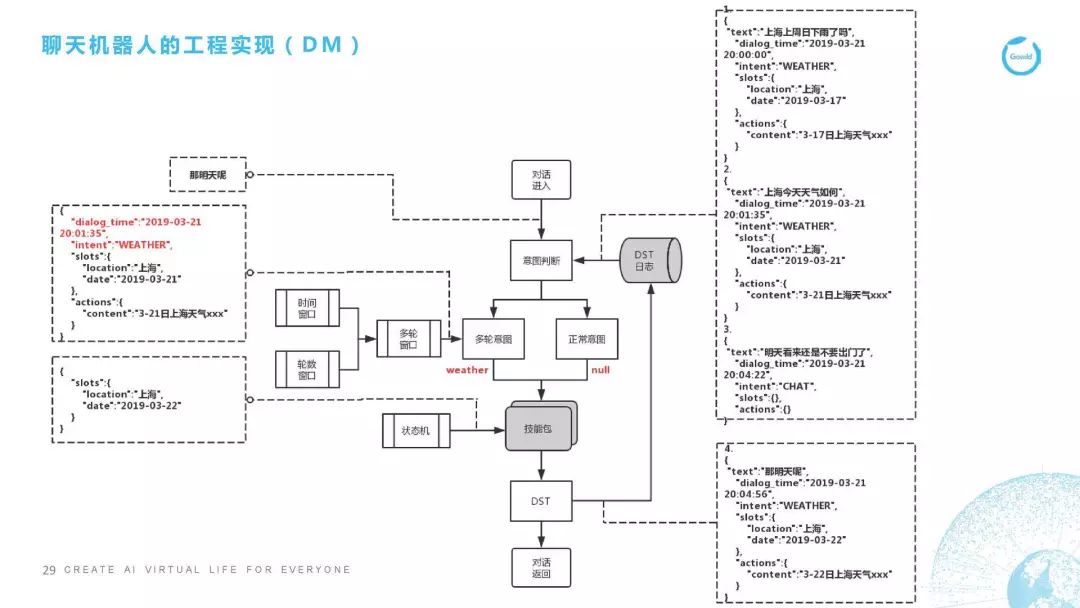
DM(对话管理)
第三点,下面这个部分开始讲DM。DM的代码在这里没有贴,因为这个实在是太复杂了。我跟大家讲一下整个框架是怎么实现的,DM是对对话进行控制,很多情况下是对多轮对话进行控制。我这里举了个典型的多轮对话,这里举的例子是天气,我这里列了1、2、3,是用户在前三轮所说的一些话,比如说用户第一句说“上海上周日下雨了吗?”它的对话时间是3月21号的8点,它的意图是天气,地点是上海,时间是2019年3月17号,因为它是上周日下雨了么。我们抽取这些信息之后,就会给它回复一个3月17号的上海天气是什么样子,它下雨了没有。这是用户问的第一句话,以下是同理的。
用户第二句话问的是“上海今天的天气如何”,所以它最后的回复是3月21号的上海天气。第三句话用户说了一个不相干的,用户觉得好像今天天气很差,怎么办呢,他说了一句“明天就不要出门了吧”,这个时候我们开始说重点的了。重点就是用户当在第四句话时说“那明天呢,怎么办?”我们看一下它的处理流程,“那明天呢”这句话进入了意图分析之后,我们发现这句话的正常意图分值是非常低的,也就是说它不像是个正常的意图,在意图判断时我们已经加载了上下文,也就是说它上文的日志,这时我们用分类器模型判断或者用一些规则,判断它可能是属于某个多轮意图。这个多轮意图是属于哪一个呢?我们就要去找这个窗口,这里面有两个窗口,一个叫时间窗口,一个叫轮数窗口,比如轮数窗口我们这里设定的是3轮,3轮内的内容都会抓取,时间窗口是5分钟,5分钟内的数据都会抓取,这些数据都抓取之后,我们判断它确实是天气意图下面的一句话。这句话有了之后我们填充槽位,“那明天呢”我们判断他是在问天气,那这个天气的槽位信息是什么?明天是时间信息,那地点是哪里?地点我们直接沿用上一轮他问这个天气的地点的槽位信息。所以最后我们的槽位信息其实是“上海”是地点,时间是“3月22号”,就是明天上海的天气是怎么样的。这里面用状态机,然后去决定我们接下来要做什么样的操作,这里会经过DST的步骤。同时,我们在回复之后也把这些日志加入到日志的log数据库里去,最后会返回一个对话,这是DM的操作流程。
基于特定任务的对话实例
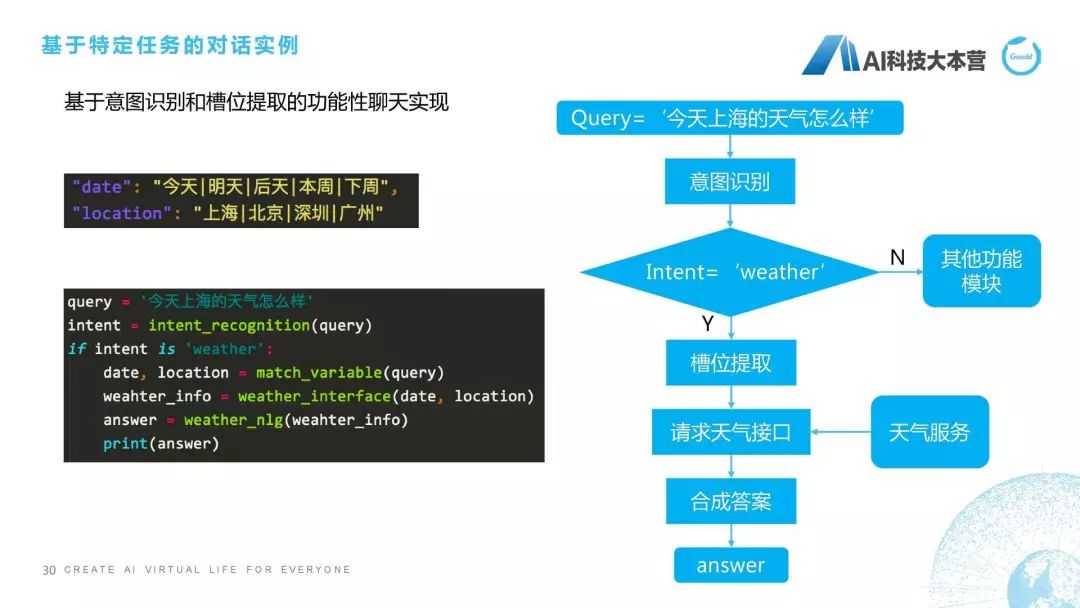
第四点,接下来是基于特定任务的对话实例,特定任务代码非常多,没办法贴全,那么就贴一下最基本的这样一些模块。比如说我们会对槽位首先进行一个限制,比如date是时间的槽位里包括“今天|明天|后天|本周|下周”等等,地点包括“北京|上海|深圳|广州”这样一些地点,当有这样的问句之后,我们首先会进行意图识别,intent-recogniton,我们会对这个query进行意图识别,如果这个intent是weather的时候,它就先进入到一个槽位提取,我们提取的槽位是根据weather下面的槽位信息去提的,它需要包括时间和地点,所以我们有这样一个函数去抽它的时间和地点信息。接下来,槽位提取之后我们就要请求天气接口了,这时比如我们用的是新浪天气,新浪天气有个服务,我们就需要用这个date和location去请求新浪天气的这个服务,返回当前的这样一个天气的情况,叫weather-info,有了这个weather-info之后我们再用NLG模块成一个回复,得到这个anwser,这就是基于我们特定任务对话实现的简单流程。
问答模块
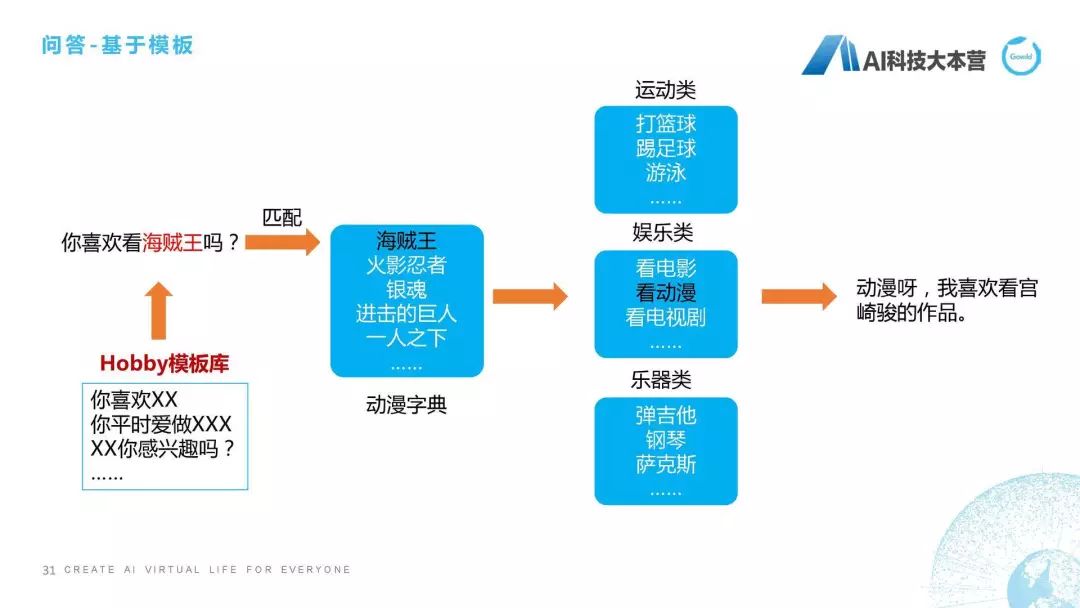
第五点,接下来介绍刚才模块里的问答模块。简单跟大家说一下基于模块的问答方式,还有更多的,比如基于语义解析超出了本次课程的范围。那基于模板怎么做?比如用户问了“你喜欢看海贼王吗?”这句话用模板的处理方式就是先去匹配这个模板库,它会在模板库里去匹配这句话跟谁是最相近的。匹配完之后我们会有一个动漫字典,它是属于海贼王,海贼王属于娱乐类的动漫的类型,所以最后给一个相应的回复语句。
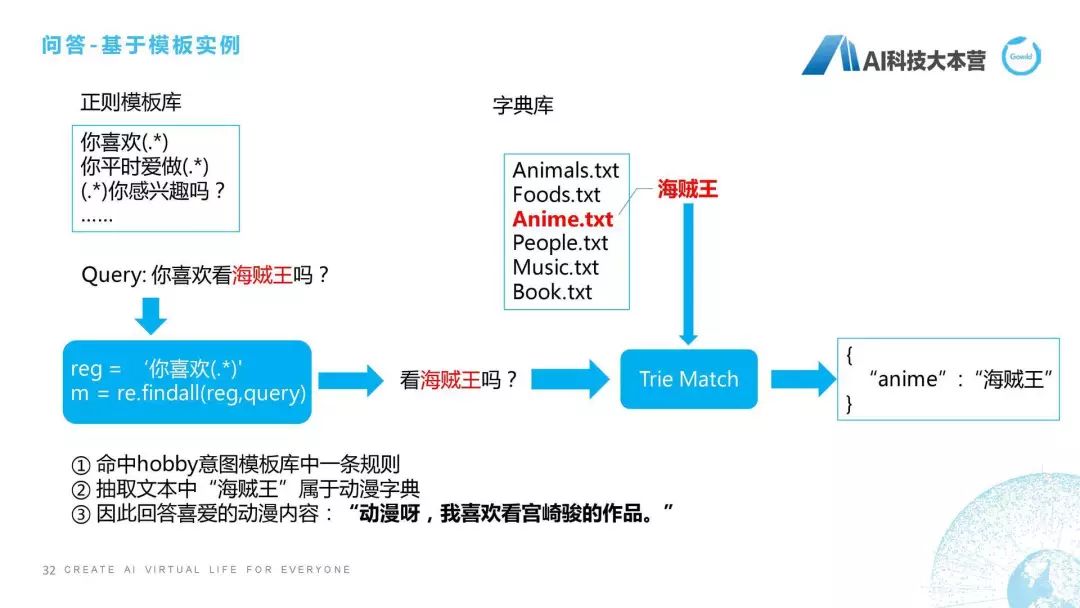
怎么去做?是这样的流程,它的做法是这样子的,我们首先维护了一套正则模板库,比如“你喜欢(.*)”,这个正则模板库大概几千条或者几百条,当有一个问句进来时,它会匹配正则模板库里的所有正则,比如它匹配的正则最后匹配到了“你喜欢”的这样一个句子,然后把“你喜欢”后面的这一部分都抽取出来,也就是说“看海贼王吗?”这几个字符全抽取出来作为候选。候选里面肯定包括一些形容词、标点符号、无意义的词,怎么去删掉它们呢?我们采用了一种方法叫TrieMatch的方法,其实可以用最常匹配的这种方法去进行匹配,我们最后匹配到字典里的叫“海贼王”的字典库,然后我们把“海贼王”关键词抽取到文本中,“海贼王”属于动漫字典,然后再给用户进行一个回复,这是这边的一个简单说明。
自然语言生成(NLG)实例
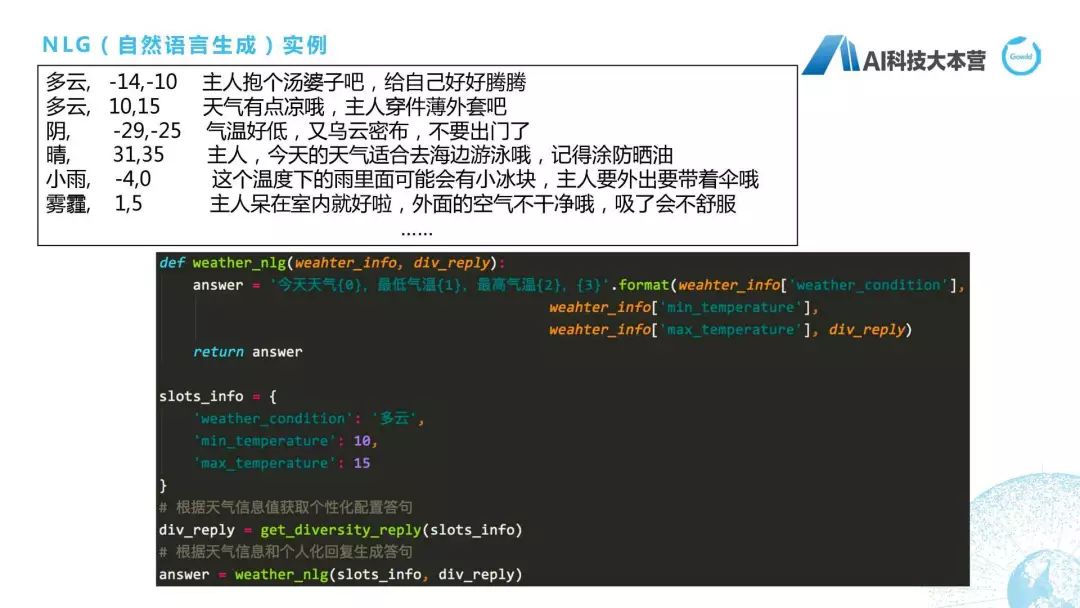
最后,讲一下自然语言生成。也就是说我们机器人在回复时,不可能让它只是回复我们查到的答案。以天气为例,天气最后的结果一般是气温,还有天气的状况。所以我不可能直接回复用户说“多云,10度、15度”,我肯定要回复非常自然的句子。它的做法是这样子的:比如我们对于整个NLG在天气回复里是这样设计的,它的Answer包括四个部分,第一个部分叫“今天的天气是什么”,第二个部分叫“最低气温是什么”,第三个部分叫“最高气温是什么”,第四个部分叫“个性化的回复语料”。我们可以看到,当我们有这样一个slots_info的时候,我们有“多云,10-15”度时,我们就直接可以把这4个信息拼成一句话,这句话可能是“今天的天气是多云,最低气温是10度,最高气温15度,天气有点凉哦,主人穿件薄外套吧”,这就是自然语言生成,我们利用槽位填充来做的模块的具体实现,其实也算一段伪代码。
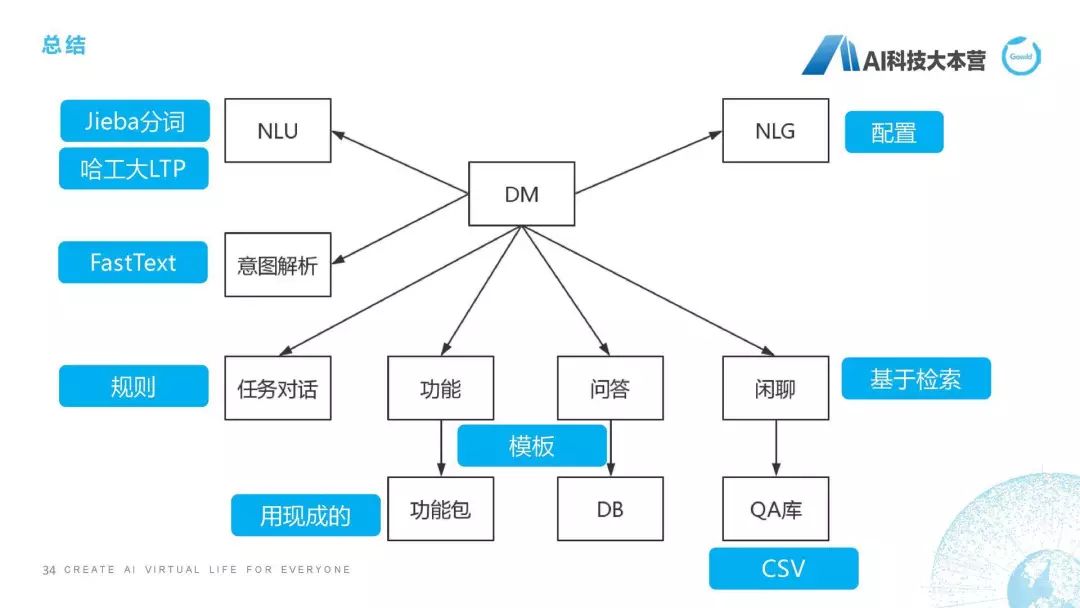
总结一下,我们整个框架怎么实现呢?首先,NLU,我们用Jieba分词、哈工大的LTP;意图解析我们可以用FastText或者Bert;NLG我们用配置的方法去做;DM我们用Python自己去写;任务对话我们用规则去实现;功能模块我们用现成的;问答模块我们用模板;闲聊模块我们是用基于检索的方法,这样就可以非常简单的去实现一个聊天机器人。今天的主要部分就讲到这些。
知识图谱在虚拟生命中的应用及技术路径
接下来跟大家聊一聊关于知识图谱方面的信息,聊天机器人这块基本的技术方面跟大家聊得差不多了。
讲讲图灵测试。聊天机器人现在表现是非常差的,但是在2014年仍然通过了图灵测试,图灵测试本身是图灵在1950年代发明的测试,它是测试机器人是不是能蒙骗人类,它的测试方法是在5分钟之内,我一个人,这有一堵墙,不知道对面是一个电脑还一个人,我跟它对话5分钟,如果参与测试的人30%都被骗了,那么就说这个计算机通过了图灵测试。其实这个测试标准是非常主观的,我们可以利用很多trick去绕过这样的一些设置。所以说其实图灵测试并不能真正反映机器人的智能程度,因为图灵测试的来源是什么?大家可能听过这个故事,图灵是个同性恋者,所以说图灵测试是每一个在英国的同性恋在1950年代必须通过的日常测试,也就是说作为一个同性恋,你能不能装成一个异性恋,其实这是图灵测试最先缘起的原由,其实是很悲惨的一个故事,最后图灵由于被接受化学阉割,然后抑郁而去自杀的,非常可惜的一个事情。所以我们讲这些的原因是在于,我们觉得哪怕是聊天机器人它通过了图灵测试,并不能代表它真正具有智能的一个效果。
所以我们接下来就会想:既然这个聊天机器人做得这么差,怎么去提升它的体验感和效果?我们想到的一种方法是给聊天机器人赋予人格和IP化,比如大白,比如R2D2,比如外星人,好像就是叫AI,这个电影,《西部世界》,我们是不是能把这些形象放到聊天机器人里去,这是我们想要做的事情。
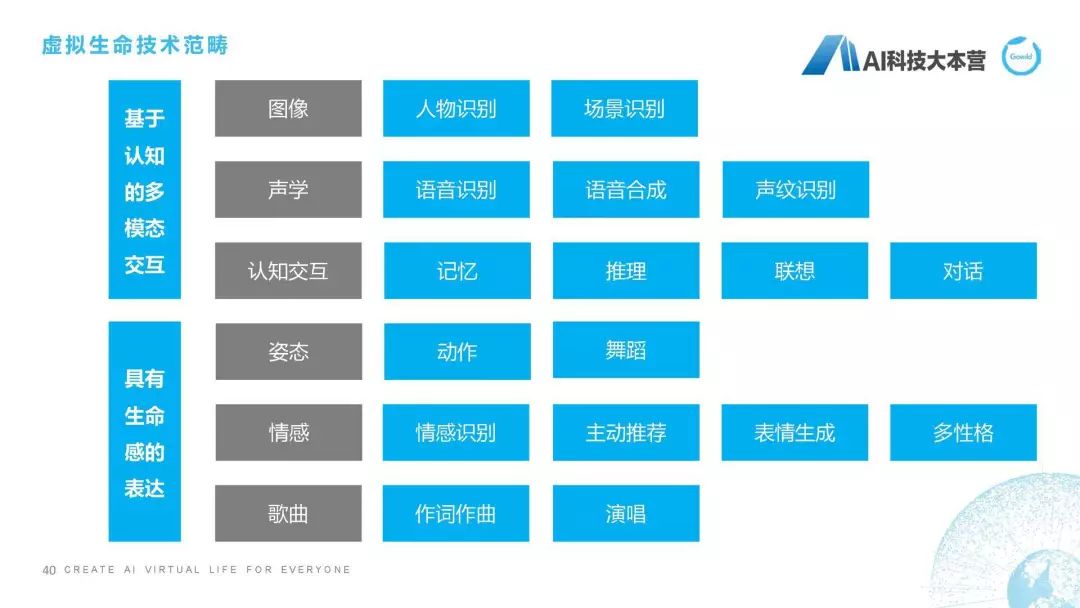
我们曾经做的一个第二代产品,就是怎样让一个聊天机器人更加具有生命感的表达,视频因为时间关系就不播放了。所以我们对虚拟生命有一个比较完整的定义,我们把它称之为“虚拟生命”,它除了具有聊天机器人最基本的能力之外,它还具有比如看、听、说、思考、动作等这样一些方面的能力,这是我们对虚拟生命期望的效果。定义是我们希望它以多形态和多模态进行交互,具备强大的感知和认知能力,并进一步实现自我认知和自我进化。这是我们对虚拟生命总体的技术进行的总结,可以看到除了图像、声学和认知交互之外,我们还具备像姿态、情感、作词作曲、演唱、多性格、情感识别、主动推荐等各方面的能力。
怎么样去实现这些能力?我们前面这些铺垫都是为了引出我们接下来要讲的这块内容,叫“知识图谱”,怎么样真正的让聊天机器人拥有自己思考、理解、推理能力,也就是我们正在研究的知识图谱技术所要带给我们可以期望的东西。我们知道,现在是深度学习和大数据的时代,深度学习和大数据利用它的算力、利用它的数据,可以在感知层面,比如图像识别、语音识别、语音合成做到非常好的效果,但是碰到有一些需要思考的问题深度学习肯定是要挂掉的。举个简单的例子,比如肖仰华老师曾经举个经典的例子叫“我把鸡蛋放到篮子里,是鸡蛋大还是篮子大?”这个问题对于深度学习来讲是非常难以解决的,因为它不具备常识和推理,所以鸡蛋大还是篮子大的这个问题它就回答不了。另外,我还可以问一个问题,叫“姚明的妻子的女儿的妈妈的老公的国籍是什么?”我想现在的聊天机器人无一例外都会被绕晕的,因为姚明的妻子的女儿的妈妈的老公其实就是姚明,但是机器人是没有办法去理解这么复杂的一段信息的。但这个时候如果我们拥有了这样一套丰富的知识图谱之后,我们其实就可以进行推理,包括常识推理这方面的内容。

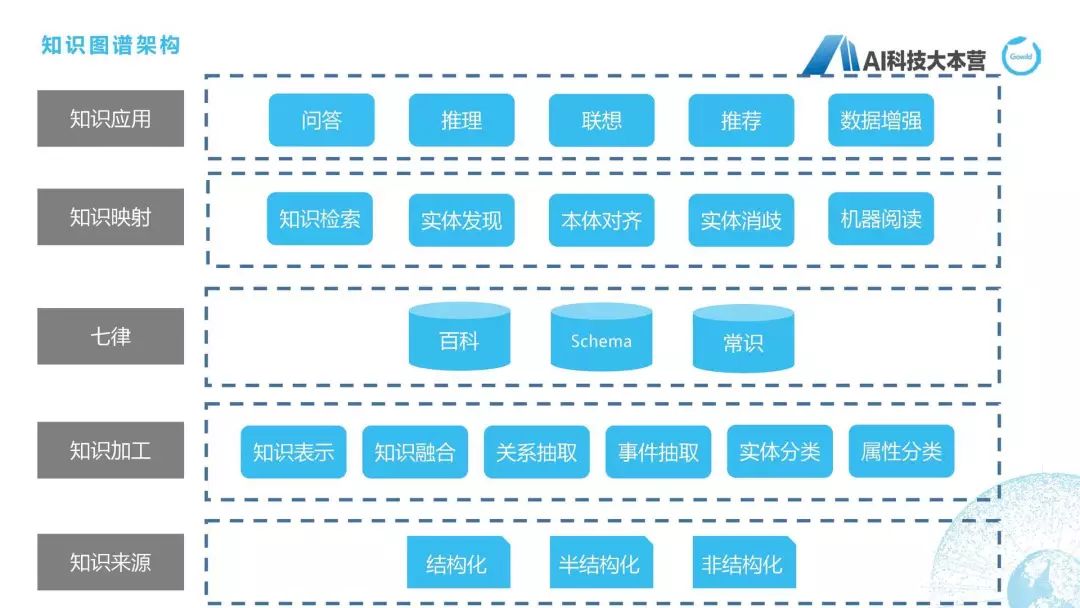
知识图谱全流程
接下来我们就开始介绍知识图谱整体的全流程,知识图谱的全流程在这张图上写得比较清楚。最下面是对于三种不同类型的数据(结构化、半结构化、非结构化)进行数据加工,这里用到知识表示、知识融合、关系抽取、事件抽取、实体分类、属性分类等各种方法去建立起自己的知识图谱,我们自己的知识图谱叫“七律”,所以我这里把“七律”这两个字写上来了。当我们建立了这些知识图谱之后,在上层就可以想象出它可以做很多应用,比如问答、推理、联想、推荐,等等,但做这些应用之前我们还需要有一步中间层,叫“知识映射层”,比如我们需要做知识检索、本体对齐、实体消歧、机器阅读这方面的事情,才能够使得这个知识图谱能够真正的变成知识应用。
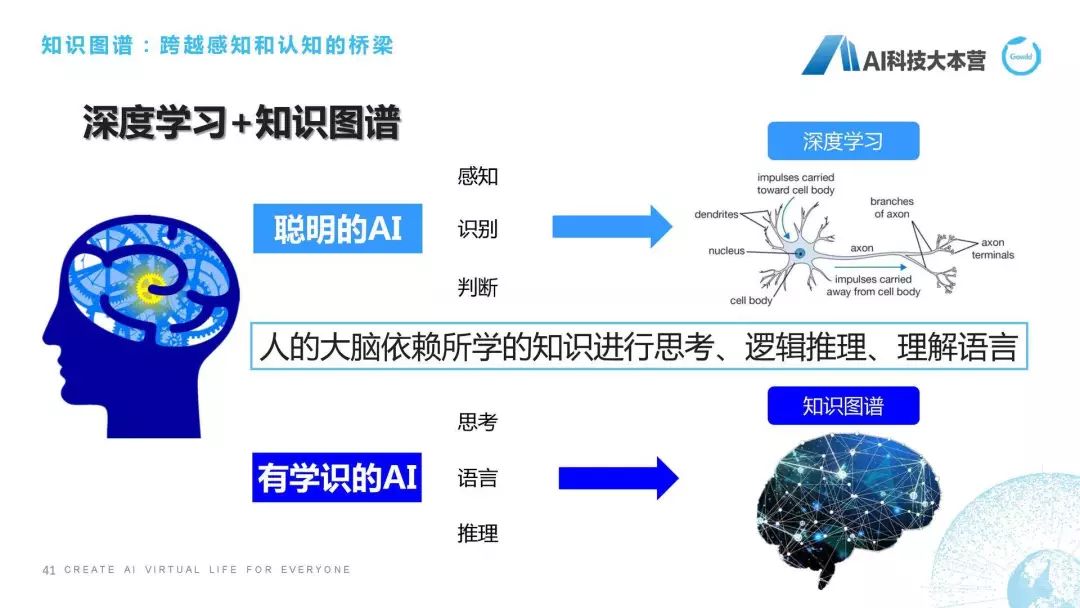
知识来源
首先说一下知识来源,我们的来源来自百度、互动百科、知乎、新浪、维基、萌娘百科。为什么要有萌娘百科呢?我们自己做的产品是一个偏向二次元和娱乐化的,所以在建立知识图谱的时候一定要根据自己的领域去建立知识图谱,萌娘百科给我们带来很多关于二次元的百科知识,这是我们非常有用的一些知识,所以我们去建立了一套偏向二次元的这样一套知识图谱。
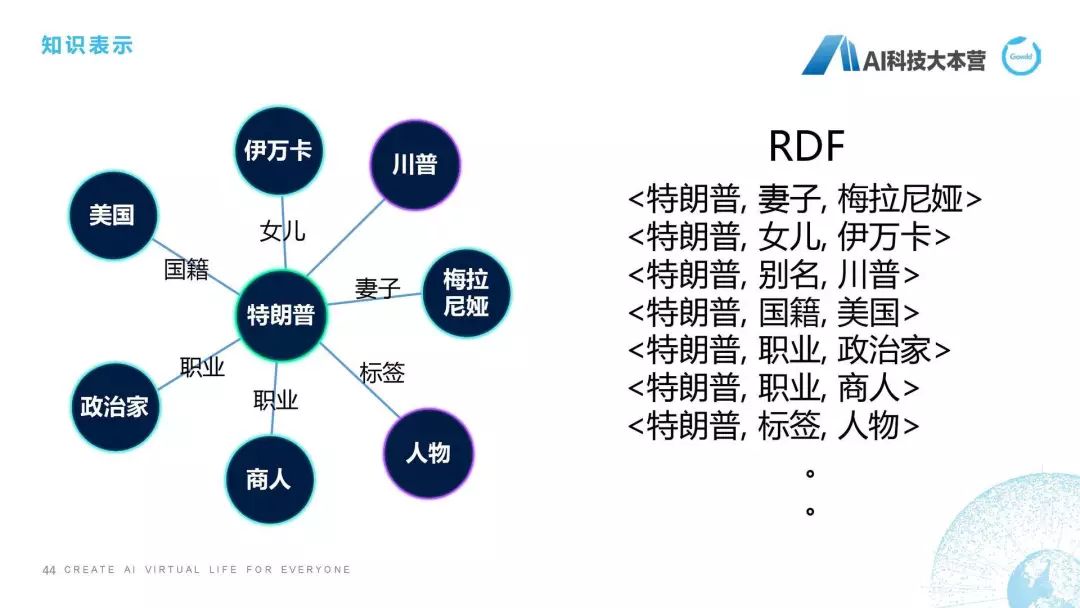
知识表示
然后是知识表示,我们都知道知识要去进行存储的话要有一定的表示方式,我们除了比较直观的图表示,还有这种RDF的表示方式,大家可以理解它是一个三元组,比如特朗普的妻子是梅拉尼娅,特朗普的女儿是伊万卡,其实是两个实体,特朗普和梅拉尼娅中间的关系是妻子关系,特朗普的妻子是梅拉尼娅,这就是我们对知识进行表示。所以在我们最底层对知识进行处理之后,我们接下来对知识需要进行一个表示。
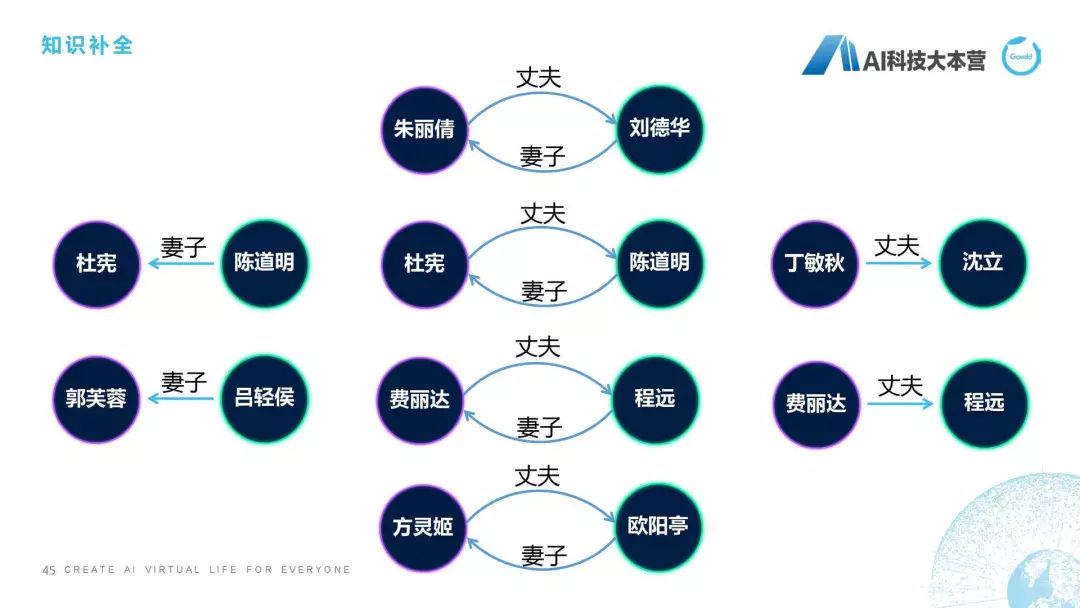
知识补全
然后这个PPT跟大家聊的是知识补全,知识补全是怎么做的呢?给大家举个例子,比如陈道明的妻子是杜宪,我们在百科里去查陈道明这个词条,我们会发现它有一个信息是妻子是杜宪,但是我们查杜宪的时候发现杜宪并没有一个边指向陈道明,那如果我们有了一套知识体系,它会限定如果一个人是另外一个人的丈夫,那么这个人肯定是这个人的妻子,这个逻辑应该不会错吧?这个也可能会错,为什么呢?两个人如果都是男性,或者两个人如果都是女性的话,这个就有问题了。但我们假定这个不存在,我们假定如果一个人是一个人的妻子,那么这个人肯定是另外一个人的丈夫。所以有了这套知识体系之后,我们就可以补上一条边,比如杜宪的丈夫是陈道明,这条边就可以自动补上了,费丽达的丈夫是程远,那么程远的妻子就是费丽达,用这样一些手段可以举行知识补全,这也是预处理时需要去做的一个事情。
知识扩展
什么叫知识扩展?就是我们把一些不存在的关系学习到并且加入到知识图谱里去。我举的这个例子可能不恰当,因为这个关系是已经存在的了,我只是说一下这个方法是怎么做的。
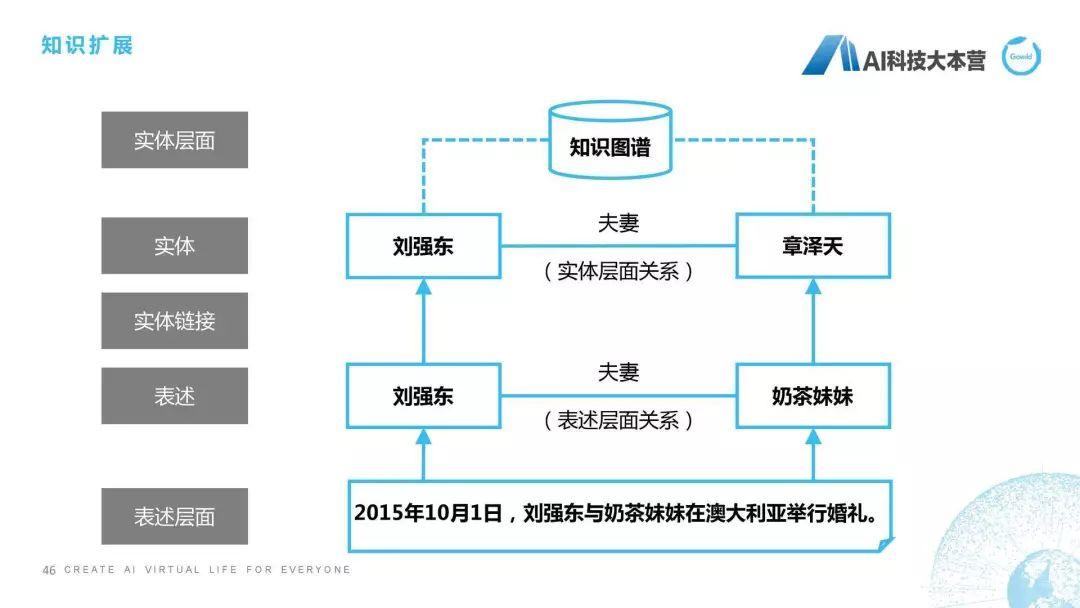
“2015年10月1号,刘强东与奶茶妹妹在澳大利亚举行婚礼”,这个句子它里面是有一个关系存在的,是什么关系?刘强东和奶茶妹妹是夫妻关系,然后我们接下来通过实体链接,在数据库里找到奶茶妹妹其实真名是章泽天,那这样我们就可以直接在刘强东和章泽天之间建立起一个夫妻关系,并且把这个知识扩展到我们已有的知识图谱中,这个就是我们所说的知识扩展方面的内容。
新知识发现

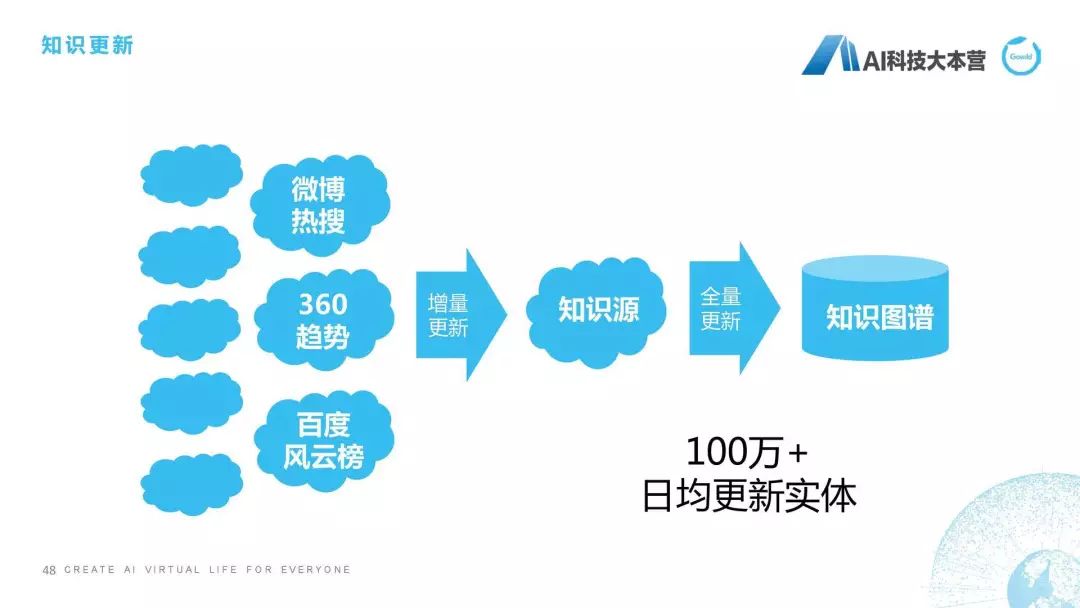
新知识发现也是我们要做的一个事情,因为我们知道知识的变化实在是太快了,我们最近有很多热点知识不断刷新我们的认知。比如“御三家”什么意思?原本是指德川本家之外的三大家族,现在可能会指这个,比如亚洲表情包御三家:姚明、金馆长、兵库北,这种御三家。还有“隔壁老王”,隔壁老王以前就是指隔壁老王,现在它有一个含义还叫“亲生爸爸”,这个也是新知识发现,我们要去找的一些东西。“祭天”也是前年挺火的,暴风影音那个事,但是我觉得挺有趣的,祭天是通过杀死程序员、产品经理等,来留住用户的一种仪式。它其实也是老词的一个新的解释,其实我们在新知识发现时,就需要去发现这样一些新的知识,有了这些新知识之后怎么办?后面就是更新。我们有两种更新方式,第一种更新方式是增量,当我们发现这样的热词之后,我们会对它以及它周边的实体进行增量更新;另外一种是全量更新,比如我们定期一个月对知识图谱进行全范围的更新,因为它的代价是相当大的,所以知识更新也是我们知识图谱整个构建链条中不可或缺的一部分来保证知识图谱的新鲜度。
基于知识图谱的问答
基于知识图谱的问答是知识图谱的一种应用,这里面跟大家举的例子是这个基于语义解析的知识图谱的问答。我们可以看到,整个问答里综合了自然语言处理的各种模块,也综合了我们在知识图谱里所涉及到的知识领域。
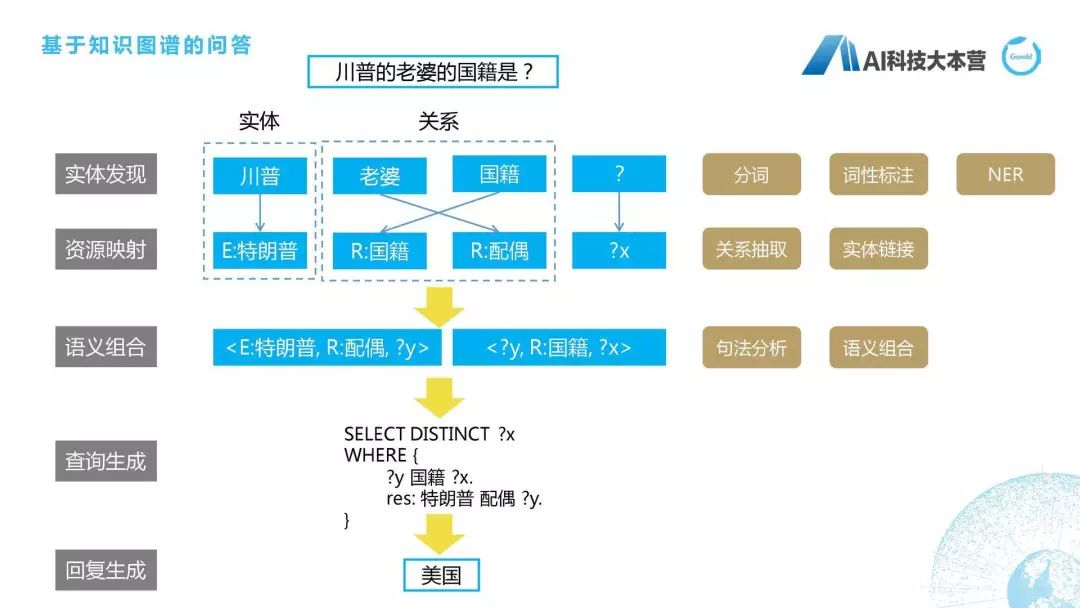
川普的老婆的国籍是什么?首先我们实体会抽取到“川普”,“川普”是指四川普通话?还是指特朗普?这里我们就需要有一个映射,有一个实体的消歧,最后我们得到它是指特朗普。“老婆”对应的标准叫法是“配偶”,“国籍”是“国籍”,“?”是“?X”,我们就会把这个语义进行组合,比如特朗普的配偶是“?y”“?y”的国籍是“?x”,而我们最后一个查的是“?x”,所以它就会这样写,“SELECT DISTINCT?X”WHERE,限定条件是什么?“?y”的国籍是“?x”,并且限制特朗普的配偶是“?y”,最后我们得到特朗普的配偶是梅拉尼娅,梅拉尼娅的国籍是美国,所以最后得到的答案是“美国”,具体的细节可以去研究一下基于语义解析的知识图谱。用到很多技术,包括分词、词性标注、NER、关系抽取,等等,也不是我们这节课所讨论的范围。
工程落地的其他问题
我们感觉掌握了很多NLP知识,掌握了很多KG技术,又有了一些工程的手段,就觉得我可以做成非常棒的产品。但正如这幅图给大家看到的一样,这是一个什么鸟,我也忘了是野鸭还是什么,它在落地冰面时滑到了,真正落地跟我们想象的有时是完全不一样的。所以在工程落地时有很多因素是需要考虑的,这里面不仅仅是技术的问题,技术可能只是占我们整个产品化的一个非常小的部分。我们需要考虑这个产品卖给谁、怎么卖,然后我们还需要考虑整个系统的性能架构。
我们是采用检索式的闲聊问答,还是做多模态的交互问答,同时我们还要考虑它软硬件投入、人力投入和市场行情是什么样的。尤其是现在聊天机器人本身就是一个已经不是红海市场,已经是血海市场了,大家在这个市场上真的是打得头破血流,如果大家还是想以简单的聊天机器人的形式来进入市场的话,就会面临什么样的竞争?就会面临49元的小米小爱音箱,就会面临79元的天猫精灵,就会面临199元的小米的小爱同学,还有299元百度的小度在家。所以怎么样做工程化和产品化,也是需要我们在商业的逻辑上思考的问题。
结语
最后耽误大家2分钟,简单讲一下我们做的是什么,我们做的是事情是聊天机器人,具体的历程就不跟大家说了,首先是公子小白。我们在2018年8月份推出了这样一款新的产品叫琥珀,它是全息投影的智能聊天音箱,2019年5月份会和全职高手合作,给大家推出一版叶修版本的琥珀机器人,我们期待用户可以通过机器人跟叶修直接进行交互,然后看它的一些动作。2019年12月份,也就是今年年底,我们会推出一个男性明星,这个男性明星应该是我们现在国内流量前10的一个男明星,小鲜肉级别的男明星,也希望大家来关注我们的产品。
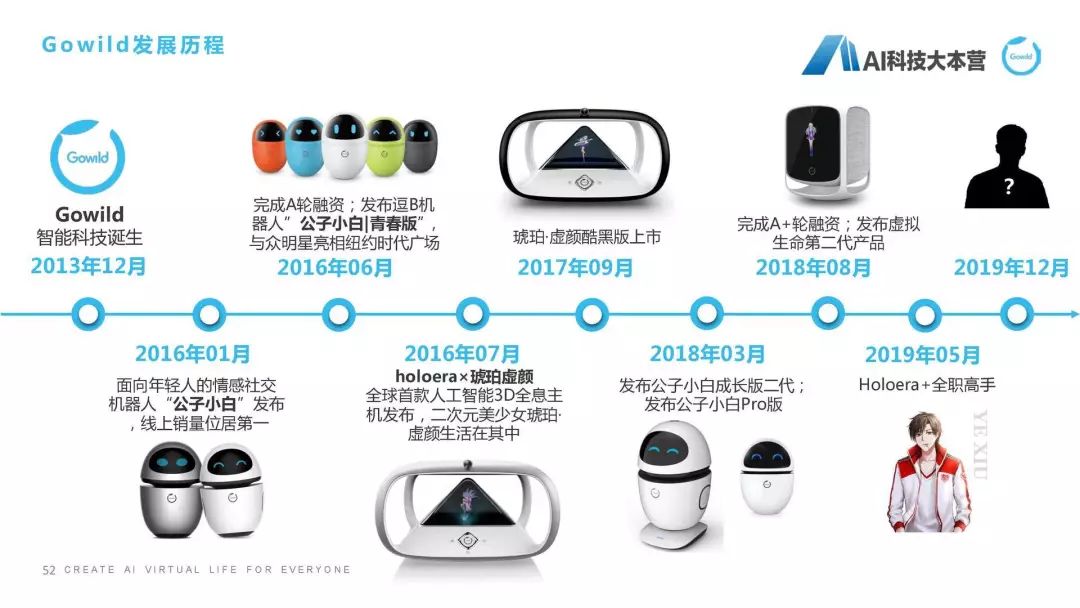
我们的人工智能研究院是在上海成立的,专家还包括张民老师、王昊奋博士,我们的成员来自于各个知名大学,跟苏大、华东师范大学等也建立了联合实验室,也推出了一款叫“虚拟生命引擎”(GAVE)的引擎。
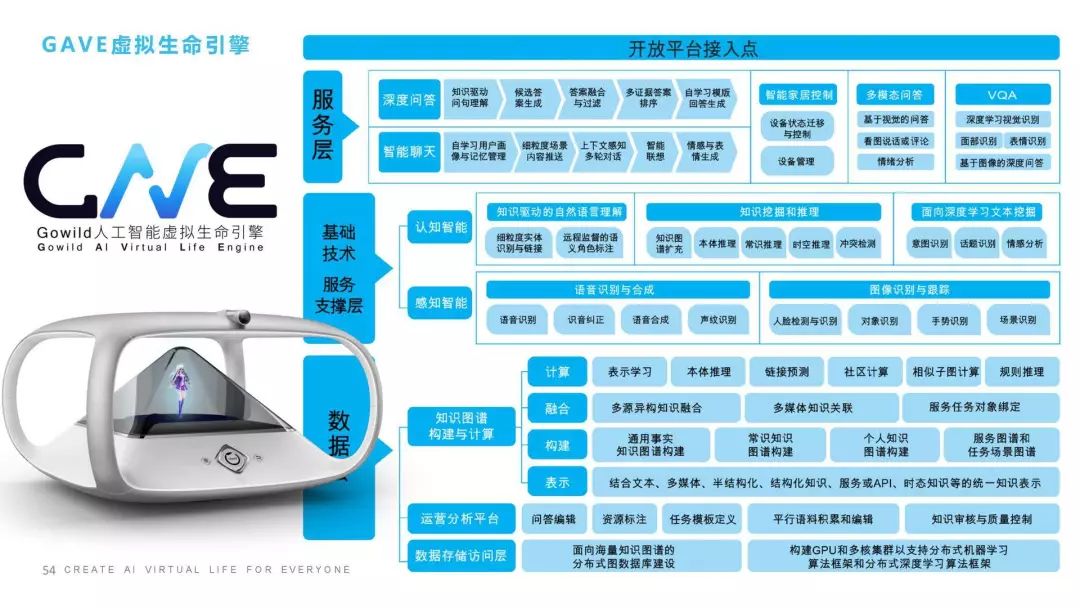
这是我的最后一页,再跟大家聊两句,我们整个虚拟生命的引擎包括几个层面:我们在数据层其实做了很多事情,包括知识图谱,包括基础的数据分析和运营平台;中间层里我们会做一些基于认知智能的、感知智能的,比如声音、图像、人脸识别、情绪识别,还包括像推理、联想、记忆、情感这样一些认知智能;服务层我们会有聊天、智能家居、多模态问答等等;最后我们还可以提供开放平台的接入点,让大家方便的接入到我们的一些功能。
感谢大家的支持,我的课程就讲到这。
Q&A
提问1:一个对话系统包括这么多内容,用端到端的系统好,还是分成一步一步来做比较好?感觉工程量好大。
邵浩:看你什么目的吧,如果你是为了做研究目的的话,那肯定是端到端了,如果写论文的话肯定是要端到端,这个是毋庸置疑的。工程方面还是要好用,所以工程方面的原则是尽可能用最简单的方法来得到效果;如果不行,我们再想其他的办法。
刚才我说到分两个层面,如果你想学工程的话,就还用这些规则自己动手实践去做;如果你想做论文研究,你就还是去专注于论文和端到端的系统。
提问2:老师,知识图谱在对话系统中重要吗?现在用得多吗?
邵浩:重要,但现在用得不多,为什么?你说的这个是知识图谱在对话系统中。知识图谱在问答系统中还是蛮重要的,我们在基于知识图谱的问答里还是大量使用知识图谱,但是在其他的功能模块,刚才我讲到了,比如闲聊,比如任务对话,那知识图谱用得并不多。而且工程界对知识图谱的使用也不是特别多。
提问3:DM中slot中如果命中Keyword,但没有返回日期和时间,会返回相应的问题给用户,请用户补充日期和时间,请问这个问题也是人工设定的吗?
邵浩:这个问题是在我们去做这个任务之前就已经设定好的,比如天气我会给它几个槽位,一个叫“时间”,一个叫“日期”。订票我会给它几个槽位:出发地、目的地、出发时间、航班、机场。所以其实你可以任务它是人工设定的,这个问题简单回答,就是人工设定的。
提问4:如果目标是从非关系数据库中对知识进行存储、抽取、推理,请问这个存储是存储在SQL还是noSQL比较好?
邵浩:像JENA、MongoDB、Dom4J,我们在工程中要根据具体场景选择不同的数据库的实现方式,。说实话,现在MySQL在某些场景下真的非常好用,还有MongoDB和ES,这种数据库有时真的比图数据库的效率要高非常多。所以要根据具体的工程场景要实现什么样的功能去决定。
提问5:对目前的算法应用效果还不如正则或者模板效果好,那怎样去选择呢?
邵浩:它是一种融合性方法,我们在自己的聊天机器人系统中也有大量的,但是我们会设计一些多层的策略。比如说我们在意图识别时会做一些策略,意图前面我们会有一些规则,规则如果能覆盖的精确性问题那最好,如果覆盖不了的,我们用深度学习方法去进行意图分类时还会采用融合方法(Stacking),我们会在融合之后综合评判是不是要选取得分最高的那个模型最后明确意图。
而且我们在做这个事情的时候一般都是返回top3或者top5,同时我们在后面模块如果发现这个意图进行不下去了,我们还有一个“拒识”模块,我们即便是走通了也会把它“拒识”掉,这个要根据产品的效果去选择的。
提问6:意图识别全靠人工编辑所有意图规则在进行判断吗?还有其他方法吗?
邵浩:我刚才举的例子是用规则来进行意图识别的,但我后面有一个PPT还讲到,意图识别其实是一种融合性方法,所以可以你先有规则,然后后面再用一些深度学习方法,刚才我说的fastText也可以做这种意图分类,但需要有大量的数据做监督学习。
提问7:怎样自动化测试聊天机器人的效果?
邵浩:这个要看一下评测标准。我们自己内部会有自己的评测标准,这个评测标准包含几百项测试,比如它的识音,它的识音还要分几米,比如近场识音、远场识音,然后它对话过程中的轮数、学习时间、对话的自然度、语音的自然度,等等,都会作为聊天机器人的测试效果。所以现在工程界并没有一个非常准确的、严格的测试聊天机器人的效果的方法。如果你们想去参考的话,学术界有很多这种聊天机器人的评测,非常多的评测,大家可以去看一下,我们那本书也有一章写了测评的方法。
提问8:意图识别后的分类用哪种方式好?自上而下直接分发到domain或者bot,还是中控先分发、后收集反馈?
邵浩:每一家bot的做法都不太一样,你说的domain其实是一种两层次分类,我们是一种五层次分类。我们的做法会采用一个两层策略,我们先做一个粗分类,然后有一个topK的结果,然后把这个topK的结果分发给K个子模块进行执行,每个子模块相当于是一种竞争关系,它们在执行完这些问题之后,给我了DM一个反馈。比如我是音乐模块,我给我的DM反馈就是我觉得我做得最好,我给自己打10分,你愿意不愿意接受我这种分值。然后DM就会中控再决定我收集到的这些,比如我在500毫秒收集到所有模块的反馈之后,再决定选择哪个模块进行最后的返回。所以这块最后还是根据每家bot的系统不太一样。
提问9:图灵测试如果不能体现聊天机器人的先进性,那么通过哪种测试来测试性能呢?
邵浩:这个跟刚才我说的那个问题一样,学术界是有比较多评测数据的比赛,大家可以关注一下这些比赛,看一下理论界是怎么做的。
提问10:在意图识别中如果遇到一个query有多个意图,该怎么处理比较好?
邵浩:我们其实是有topK,会以它最后的分值来判断。
提问11:NLU会做预处理吗?
邵浩:会的,肯定会做的,而且都是单独模块,比如语气词、标准化,都是单独模块去做的。
提问12:词义消歧怎么做?
邵浩:词义消歧有各种不同的方法,有基于规则的,还有基于热度的。比如基于热度,比如我们在讲“737”时,它可能指737-800,也可能指737max,这时我们可能根据社交媒体的热度,来判断最近最火的新闻是737max飞机失事,这时我们就可以利用热度进行消歧。消歧的方法还有很多种,我们可以利用上下文、热度、贡献词,这个都可以去用的。
提问13:在垂直领域进行对话,利用知识图谱,性能是否会有提升?
邵浩:肯定会有的,因为我们也做过很多类似于政府的垂直项目、医疗的垂直项目,利用知识图谱会大大提升它的问答效果,这个肯定会的。
提问14:机器人处理的链路很长,如何平衡响应速度和链路模块的质量?
邵浩:这个问题提得很好,因为我们现在聊天机器人里有一个非常严重的问题叫“错误传递”,如果你串行模块多的话,它的错误传递下来就会非常差。我们平衡时要根据具体情况,比如我们会设置一个“超时”,有些模块并行处理时,我们会选择没有超时并且效果最好的那个处理。
提问15:如何衡量情感方面的好坏?
邵浩:我们自己有一个三层体系,大概27种判断标准,这个可能也会根据具体的情况来具体判断吧,没有办法给出一个标准的指标。
提问16:有什么指标来判定闲聊回答的优点?
邵浩:最直接的一个指标就是看看用户愿意不愿意跟你聊,小冰其实提出了很多指标,比如用户跟你进行对话的轮数作为一个指标。
提问17:多轮意图分类是怎么实现的?
邵浩:我刚才在PPT里应该说得比较清楚,“那明天呢”它没有走到正常意图里,它正常意图得分会非常低,它低于我们的域值,所以我们要么丢弃它,要么拒识,要么判断它是不是多轮的,如果它走到多轮里,我们会利用多轮的状态机进行它后面的问答。
提问18:检索问答琥珀是否有用问题答案的匹配方法,还是只用问题和问题的匹配方法?
邵浩:这个问题问得比较好,我们两种都用。因为什么?因为我们的log数据是非常多的,这个可能又涉及到我们比较底层的东西,我就不多说了。我们两种方法都会用,而且问题到答案的这种方法,有时是把问题通过其他的方式生成答案之后再进行匹配的,这个方法是很有效的,建议大家去尝试一下。
-
人工智能
+关注
关注
1791文章
47274浏览量
238480 -
大数据
+关注
关注
64文章
8889浏览量
137439 -
聊天机器人
+关注
关注
0文章
339浏览量
12312
原文标题:聊天机器人落地及进阶实战 | 公开课速记
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
自然语言处理在聊天机器人中的应用
马斯克旗下xAI计划推出Grok聊天机器人独立应用
NLP技术在聊天机器人中的作用
ChatGPT 与传统聊天机器人的比较
Meta人工智能聊天机器人进军新市场,挑战ChatGPT
Snapchat聊天机器人集成谷歌Gemini技术
Meta将推出音频版聊天机器人
地瓜机器人与广和通深度合作,共驱智能机器人商用落地

地瓜机器人与广和通深度合作,共驱智能机器人商用落地






 工商网监
工商网监
评论