 带你入门常见的机器学习分类算法——逻辑回归、朴素贝叶斯、KNN、SVM、决策树
带你入门常见的机器学习分类算法——逻辑回归、朴素贝叶斯、KNN、SVM、决策树
【导读】众所周知,Scikit-learn(以前称为scikits.learn)是一个用于Python编程语言的免费软件机器学习库。它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度增强,k-means和DBSCAN,旨在与Python数值和科学库NumPy和SciPy互操作。本文将带你入门常见的机器学习分类算法——逻辑回归、朴素贝叶斯、KNN、SVM、决策树。
逻辑回归 (Logistic regression)
逻辑回归,尽管他的名字包含"回归",却是一个分类而不是回归的线性模型。逻辑回归在文献中也称为logit回归,最大熵分类或者对数线性分类器。下面将先介绍一下sklearn中逻辑回归的接口:
class sklearn.linear_model.LogisticRegression(penalty='l2', dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='warn', max_iter=100, multi_class='warn', verbose=0, warm_start=False, n_jobs=None)
常用参数讲解:
penalty:惩罚项。一般都是"l1"或者"l2"。
dual:这个参数仅适用于使用liblinear求解器的"l2"惩罚项。 一般当样本数大于特征数时,这个参数置为False。
C:正则化强度(较小的值表示更强的正则化),必须是正的浮点数。
solver:参数求解器。一般的有{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}。
multi_class:多分类问题转化,如果使用"ovr",则是将多分类问题转换成多个二分类为题看待;如果使用"multinomial",损失函数则会是整个概率分布的多项式拟合损失。
不常用的参数这里就不再介绍,想要了解细节介绍,可以sklearn的官网查看。
案例:
这里我使用sklearn内置的数据集——iris数据集,这是一个三分类的问题,下面我就使用逻辑回归来对其分类:
from sklearn.datasets import load_irisfrom sklearn.linear_model import LogisticRegressionX, y = load_iris(return_X_y=True)clf = LogisticRegression(random_state=0, solver='lbfgs', multi_class='multinomial').fit(X, y)
上面我就训练好了一个完整的逻辑回归模型,我们可以用predict这个函数对测试集进行预测。
clf.predict(X[:2, :])
如果想知道预测的概率,可以通过predict_proba这个函数来进行预测。
clf.predict_proba(X[:2, :])
如果想知道我们预测的准确性,可以通过score这个函数来判断我们的模型好坏。
clf.score(X, y)
朴素贝叶斯
朴素贝叶斯方法是一组基于贝叶斯定理的监督学习算法,在给定类变量值的情况下,朴素假设每对特征之间存在条件独立性。下面我将介绍几种朴素贝叶斯的方法。
1、高斯朴素贝叶斯 (GaussianNB)
高斯朴素贝叶斯的原理可以看这篇文章:
http://i.stanford.edu/pub/cstr/reports/cs/tr/79/773/CS-TR-79-773.pdf
这里,我将介绍如何使用sklearn来实现GaussianNB。
from sklearn import datasetsiris = datasets.load_iris()from sklearn.naive_bayes import GaussianNBgnb = GaussianNB()y_pred = gnb.fit(iris.data, iris.target).predict(iris.data)print("Number of mislabeled points out of a total %d points : %d" % (iris.data.shape[0],(iris.target != y_pred).sum()))
2、多项式朴素贝叶斯 (MultinomialNB/MNB)
这里我随机生成一组数据,然后使用MultinomialNB算法来学习。
import numpy as npX = np.random.randint(50, size=(1000, 100))y = np.random.randint(6, size=(1000))from sklearn.naive_bayes import MultinomialNBclf = MultinomialNB()clf.fit(X, y)print(clf.predict(X[2:3]))
3、 互补朴素贝叶斯 (ComplementNB/CMB)
ComplementNB是标准多项式朴素贝叶斯(MNB)算法的一种改进,特别适用于不平衡数据集。具体来说,ComplementNB使用来自每个类的补充的统计信息来计算模型的权重。CNB的发明者通过实验结果表明,CNB的参数估计比MNB的参数估计更稳定。此外,在文本分类任务上,CNB通常比MNB表现得更好(通常是相当大的优势)。
CNB的sklearn接口:
class sklearn.naive_bayes.ComplementNB(alpha=1.0, fit_prior=True, class_prior=None, norm=False)
常用参数讲解:
alpha:加性(拉普拉斯/Lidstone)平滑参数(无平滑为0)。
fit_prior:是否学习类先验概率。若为假,则使用统一先验。
class_prior:类的先验概率。如果指定,则不根据数据调整先验。
norm:是否执行权重的第二次标准化。
案例:
import numpy as npX = np.random.randint(50, size=(1000, 100))y = np.random.randint(6, size=(1000))from sklearn.naive_bayes import ComplementNBclf = ComplementNB()clf.fit(X, y)print(clf.predict(X[2:3]))
4、伯努利朴素贝叶斯 (BernoulliNB)
BernoulliNB实现了基于多元伯努利分布的数据的朴素贝叶斯训练和分类算法。BernoulliNB可能在某些数据集上表现得更好,特别是那些文档较短的数据集。BernoulliNB的sklearn与上面介绍的算法接口相似。
案例:
import numpy as npX = np.random.randint(50, size=(1000, 100))y = np.random.randint(6, size=(1000))from sklearn.naive_bayes import BernoulliNBclf = BernoulliNB()clf.fit(X, Y)print(clf.predict(X[2:3]))
K-Nearest Neighbors(KNN)
KNN基于每个查询点的最近邻居来实现学习,其中k是用户指定的一个整数值。是最经典的机器学习算法之一。
KNN的skearn的接口如下:
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None, **kwargs)
常用参数讲解:
n_neighbors:邻居数,是KNN中最重要的参数。
algorithm:计算最近邻的算法,常用算法有{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}。
案例:
from sklearn import datasetsiris = datasets.load_iris()from sklearn.neighbors import KNeighborsClassifierneigh = KNeighborsClassifier(n_neighbors=3)neigh.fit(iris.data, iris.target) print(neigh.predict((iris.data))print(neigh.predict_proba((iris.data))
支持向量机 (SVM)
支持向量机(SVMs)是一套用于分类、回归和异常值检测的监督学习方法。这里我将只介绍分类方法。支持向量机的优点是:在高维空间中有效;在维数大于样本数的情况下仍然有效,因此对于小数据集,SVM可以表现出良好的性能。
SVM在sklearn上有三个接口,分别是 LinearSVC, SVC, 和 NuSVC。最常用的一般是SVC接口。
SVC的sklearn接口:
class sklearn.svm.SVC(C=1.0, kernel=’rbf’, degree=3, gamma=’auto_deprecated’, coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=’ovr’, random_state=None)
常用参数讲解:
C:错误项的惩罚参数C
kernel:核函数的选择。常用的核函数有:‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’。
probability:预测时是否使用概率估计。
案例:
import numpy as npX = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])y = np.array([1, 1, 2, 2])from sklearn.svm import SVCclf = SVC(C=1,kernel='rbf',gamma='auto')clf.fit(X, y) print(clf.predict([[-0.8, -1]]))
拓展:SVM解决二分类问题具有得天独厚的优势,然而对于解决多分类问题却很困难。常见的解决方案是“一对一”的方法解决多分类问题。具体地,假设 这个是一个 n_class的分类问题,则会构建 n_class*(n_class-1)/2个二分类,来解决这个多分类问题。
X = [[0], [1], [2], [3]]Y = [0, 1, 2, 3]clf = svm.SVC(gamma='scale', decision_function_shape='ovo')clf.fit(X, Y) dec = clf.decision_function([[1]])dec.shape[1] # 4 classes: 4*3/2 = 6clf.decision_function_shape = "ovr"dec = clf.decision_function([[1]])dec.shape[1] # 4 classes
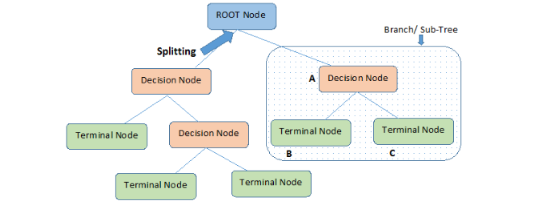
决策树
决策树作为十大经典算法之一,能够很好的处理多分类问题。
决策树的sklearn接口:
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)
常用参数讲解:
criterion:该函数用于衡量分割的依据。常见的有"gini"用来计算基尼系数和"entropy"用来计算信息增益。
max_depth:树的最大深度。
min_samples_split:分割内部节点所需的最小样本数。
min_samples_leaf:叶节点上所需的最小样本数。
案例:
from sklearn.datasets import load_irisfrom sklearn.model_selection import cross_val_scorefrom sklearn.tree import DecisionTreeClassifierclf = DecisionTreeClassifier(random_state=0)iris = load_iris()clf.fit(iris.data, iris.target)clf.predict(iris.data)clf.predict_proba(iris.data)
总结
本文介绍了几种常见的机器学习分类算法,如逻辑回归,朴素贝叶斯,KNN,SVM,以及决策树算法。同时,也用sklearn的python接口展示了各个算法使用案例。
-
机器学习
+关注
关注
66文章
8457浏览量
133203 -
决策树
+关注
关注
3文章
96浏览量
13603 -
朴素贝叶斯
+关注
关注
0文章
12浏览量
3398
原文标题:15分钟带你入门sklearn与机器学习——分类算法篇
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
朴素贝叶斯等常见机器学习算法的介绍及其优缺点比较









 工商网监
工商网监
评论