 用于语音情绪识别的基于对抗学习的说话人无关的表示
用于语音情绪识别的基于对抗学习的说话人无关的表示

1. 用于语音情绪识别的基于对抗学习的说话人无关的表示
尝试解决的问题:
在语音情绪识别任务中,会面临到要测试的说话人未出现在训练集中的这个问题,本文尝试运用TDNN+LSTM作为特征提取部分,再通过对抗学习的方法来做到让模型可以对说话人身份不敏感,从模型上来说,该对抗训练的思想就是将特征提取器提取到的特征同时输入到说话人身份分类器和情绪识别分类器,对抗训练的损失函数是让说话人身份分类器的损失达到最大,让情绪识别分类器的损失达到最小,这样以后,无论是哪个说话人的语音,经过特征提取那部分以后,就没有身份这一区别了。
如果有读者阅读过论文《Domain adversarial training of neural networks》,那么对DAT这个名词就不陌生了,即迁移学习中的跨域学习,比如我现在有A领域的数据,并且该数据已经被标记好类别,同时也有B领域数据,但是未进行标记,如果我希望充分利用B数据,目标是进行分类,该怎么利用呢?我们只需要三个模块结合对抗学习即可完成,分别是特征提取器+域识别器+分类器,当域识别器已经无法正确判断的时候,说明特征提取器已经完成了身份融合的效果,这个时候训练分类器即可。
在本篇语音情绪识别中,作者所提出的模型如下图所示,输入音频的MFCC特征经过TDNN网络(由卷积神经网络实现)和BiLSTM网络得到新的特征分布,再将此特征分布同时输送到情绪识别器得到情绪种类y和说话人身份识别器得到身份s。
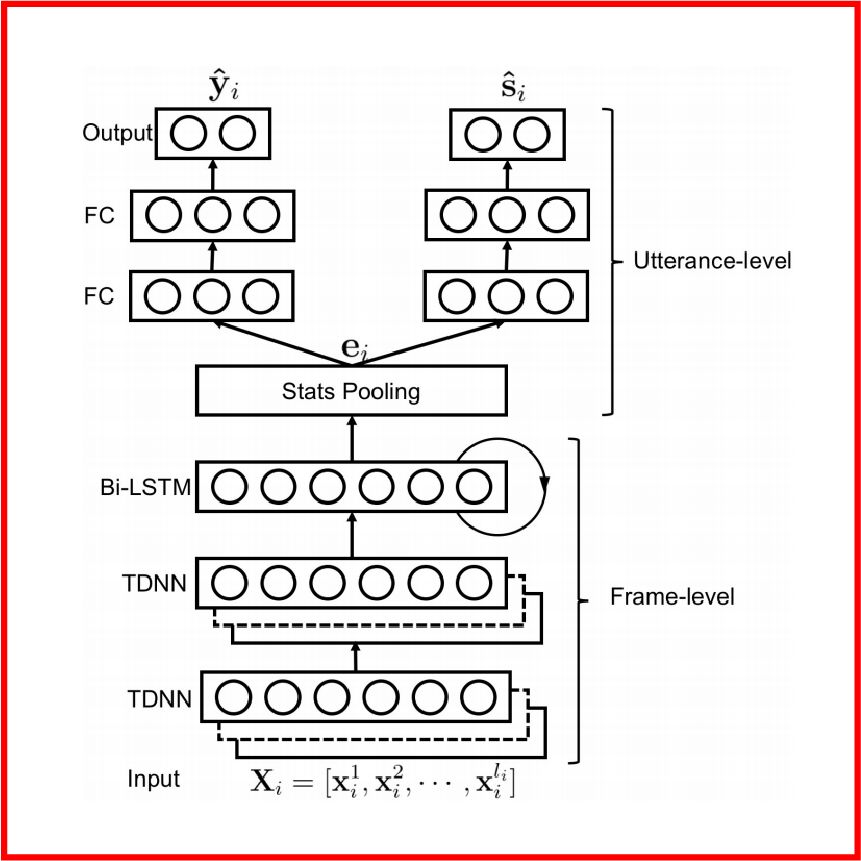
作者尝试运用了两种训练方法,一种是domain adversial training,即DAT;另一种是cross gradient training,即CGT。下面我将分别解释这两种训练算法。
DAT
如前所述,DAT是通过对抗学习来使得网络具备跨域的能力,其损失函数如下,可以看到,对于身份识别器而言,它的损失函数前面乘了一个因子并且取了负号,这使得网络可以具备身份融合的作用,从而专注于情绪分类。
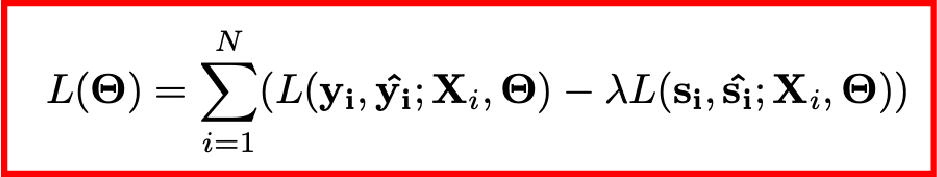
CGT
CGT是另外一种解决跨域学习的数据增强技巧,它通过将梯度传到输入数据上,于是情绪识别网络可以训练原数据和增强后的数据,这样就可以使得模型具备学习跨域的变化特征进而可以适应未知的测试数据集。CGT的数据增强技巧和损失函数如下,其中前两项是增强后的新数据,最后是参数更新公式。
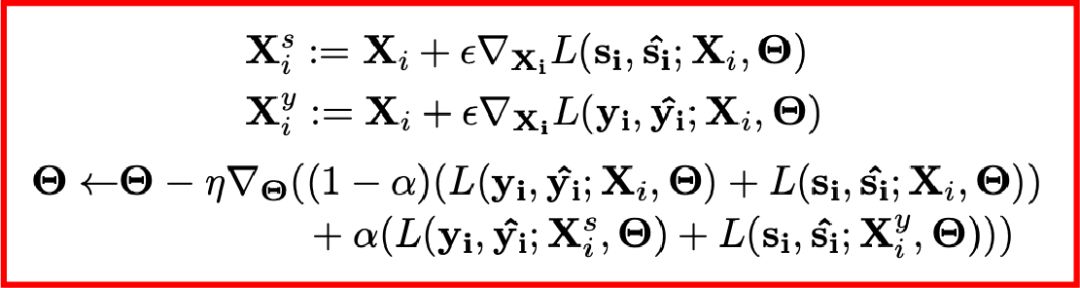
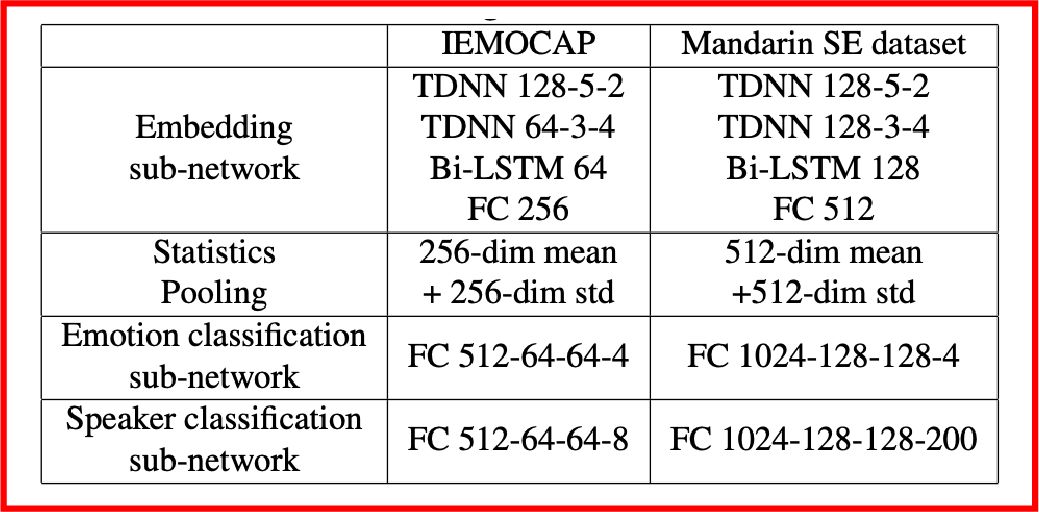
作者基于本模型和两种训练技巧分别在IEMOCAP数据集和SpeechOcean中文大数据集上做了测试,所用的具体模型结构如下所示,实验结果表明,在IEMOCAP小数据集上,相比于基线模型,DAT提高了5.6%,CGT提高了7.4%;但是在SpeechOcean 250说话人的中文大数据集上,DAT提高了9.8%,CGT的性能不及基线模型。
同时,作者画出了通过DAT训练的经过特征提取器得到的特征分布的t-SNE降维表示,如下图所示,左边是情绪类别,右边是身份类别,可以看到身份标签已经很好地被融合在一起。
2. 基于滤波和深度神经网络的声源增强
参考文献:
data-driven design of perfect reconstruction filterbank for dnn-based sound source enhancement
链接:
https://arxiv.org/abs/1903.08876
单位:
早稻田大学 & 日本电话电报公司
尝试解决的问题:
传统的声源增强(Sound-source enhancement,SSE)的做法是首先将含噪音的信号进行STFT变换得到时频图,再借助深度神经网络进行特征变换,将得到的新的时频图与目标时频图进行求均方差,基于此均方差来训练神经网络的参数。训练好网络以后,将推理得到的时频图通过ISTFT变换到音频,即可得到增强的音频信号。这种做法的缺点按照文中的描述就是:
For example, MSE assumes that the error of all frequency bins has zero means and uniform variance, which cannot be met in usual situations, unfortunately.
按照笔者的理解就是训练均方差目标函数得确保数据中每个频率仓的均值和方差一样,因为只有这样训练才比较有效参数才可以稳定地更新,但是实际上,我们在计算STFT的时候,并没有考虑到所有音频的个体差异,本文尝试解决的就是这里的维度上的统计均匀的问题,DNN的框架是没有变的,整体框架可以参见下图的对比:

首先,传统的STFT算法作用到一个信号x上可以用如下公式描述:
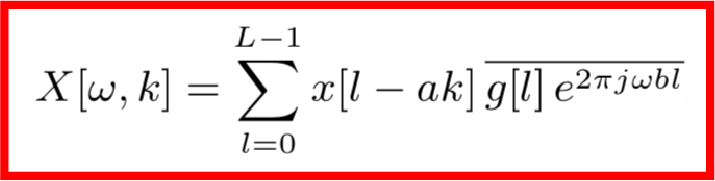
这里得到的X就是该信号的时频信息,其中ω是频率索引,k是帧索引。我们知道,X是由目标信号和噪音信号共同组成的,根据傅里叶变换的可加性,可知:
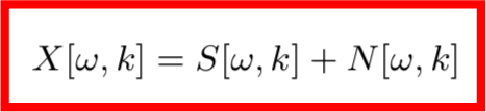
为了得到目标时频,我们在X[ω,k]的基础上作用一个T-F遮罩G[ω,k],该T-F遮罩一般使用深度神经网络M来实现,于是整个模型的损失函数可以写成如下形式:
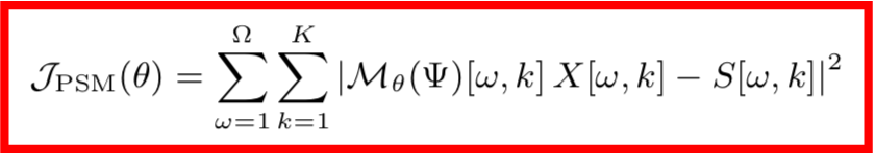
但是基于MSE的训练算法有一个数据上的缺陷,因为MSE的前提假设是各个维度的数据分布要保持一致,但这在实际中是很难保证的,因无论是声源还是噪声都有着不均匀的频谱分布,举个例子,由于高频区域音频较少,功率谱较小,误差变化比较小,因而高频区域要比低频区域更难训练。这个时候,对损失函数做一个加权是合理的想法,该权重应该是自适应频率的,并且与频率误差的标准差成反比,也就是说误差标准差越小的频率,我们需要多重视一下它的损失函数。
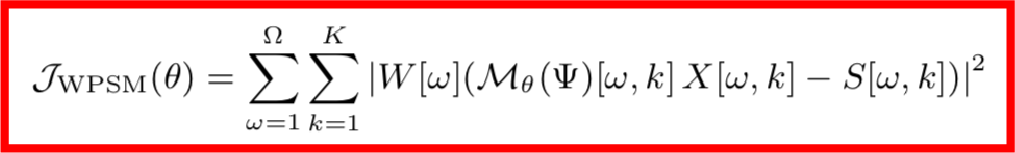
其中,权重的计算公式如下:
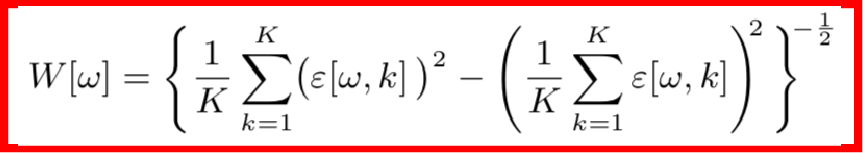
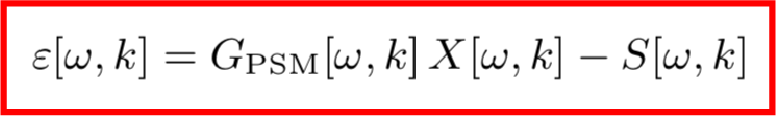

但是这样又带来一个问题,因为功率谱较小的频率区域权重比较大,故模型对那些区域的噪声特别敏感,那么,算法的有效性就降低了。
本文作者提出的改进的思路是保持损失函数不变,而对STFT部分进行改进,公式如下,作者将原公式中的ω定义成了φ(ω)的倒数的形式,这样就可以自定义频率的量级,这里的φ函数称之为频率扭曲函数。
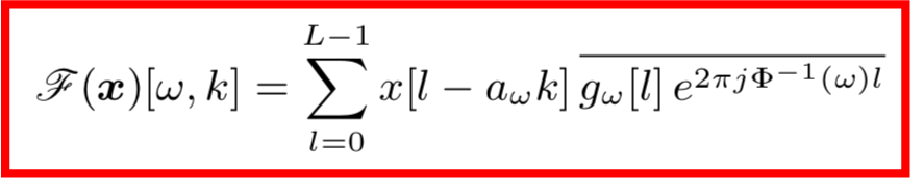
那么如何设计这里的频率扭曲函数φ呢?通过对误差的功率谱密度进行累计求和,依次从低频到高频,并加上一个规则化因子:

本文中所用的特征变换网络的结构如下表所示,分别是全连接神经网络+两层双向LSTM循环神经网络+全连接分类网络,以输出目标频谱。

最后作者将此模型运用到以WSJ-0作为目标数据集,以CHiME-3作为噪声来源所构成的四套数据上,即通过构建含噪音频-清晰音频配对来作为训练样本,得到的实验结果如下,图中的数值代表信噪比,数值越大,表明信噪比越高,即增强效果越好。
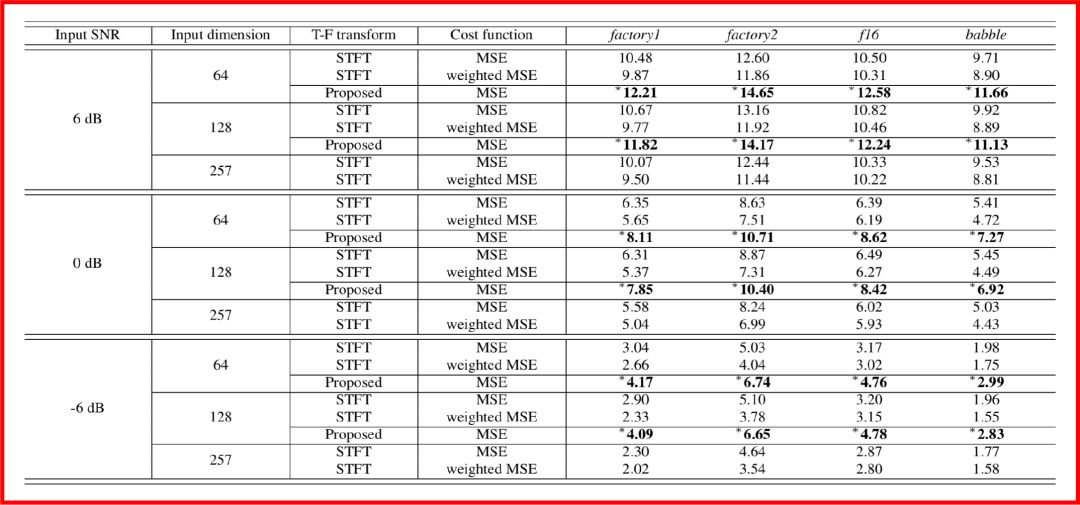
总体而言,这篇文章是基于平行语料和深度神经网络,对语音增强中的输入频谱的预处理算法进行改进,以解决基于均方差训练中可能会出现的训练不稳定的问题。以后的推送中将会看到,对于语音增强或语音分离,我们甚至可以采用非平行语料来做。
3. 用于语音韵律、频谱可视化的在线网页平台
参考文献:
CRAFT: A Multifunction Online Platform for Speech Prosody Visualisation
链接:
https://arxiv.org/abs/1903.08718
单位:
比勒费尔德大学
demo体验网址:
http://wwwhomes.uni-bielefeld.de/gibbon/CRAFT/
尝试解决的问题:
提供一个更加友好的基频(各种不同的实现算法)、频谱包络可视化对比的在线平台。
这里我们先回顾几个声学频谱分析中的概念:
基频:一般我们对一个音频作短时傅里叶变化并画出时频图的时候,时频图上会出现很多条横条纹,而频率范围最小的那个横条纹一般可以认为就是基频的值;
谐波:除了基频那个横条纹以外,其他横条纹就是各次谐波;
共振峰:频谱上包络的峰值;
本文中介绍的demo如下图所示,其中包含基频估计的参数设计、振幅和频率调制、频率解调制、滤波等可视化窗口。

-
分类器
+关注
关注
0文章
153浏览量
13858 -
数据集
+关注
关注
4文章
1242浏览量
26286 -
迁移学习
+关注
关注
0文章
74浏览量
5857
原文标题:语音情绪识别|声源增强|基频可视化
文章出处:【微信号:DeepLearningDigest,微信公众号:深度学习每日摘要】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
说话人识别和验证系统解决方案

会物体识别和语音识别的nao机器人
请问电销机器人智能语音识别的原理是什么?
基于TMS320C6701EVM板的快速说话人识别系统
基于TMS320C6701EVM板的快速说话人识别系统
基于CS的说话人识别算法
如何使用多特征i-vector进行短语音说话人识别算法说明



评论