 一种基于模型的元强化学习算法用于提高快速适应性
一种基于模型的元强化学习算法用于提高快速适应性
人类具有适应环境变化的强大能力:我们可以迅速地学会住着拐杖走路、也可以在捡起位置物品时迅速地调整自己的力量输出,甚至小朋友在不同地面上行走都能轻松自如地切换自己的步态和行走模式。这样的适应能力对于在复杂多变的环境中生存活动十分重要。但这些看似是人类与生俱来的能力,机器人拼尽全力也未必能实现。
绝大部分的机器人都被部署在固定环境中重复执行固定的动作,但面对未知的全新情况机器人就会失效,甚至是运行环境的些许变化,比如一阵风来了、负载质量改变或意外的扰动都会给机器人带来难以处理的困难。为了缩小机器人与人类对于环境适应能力间的差距,研究人员认为机器人预测状态与实际观测状态间如果存在较大的误差,那么这个误差应该要引导机器人更新自身模型,以更好地描述当前状态,也就是快速的环境适应性。
有一个形象的例子来解释这种适应性,很多小伙伴在开车时,特别在北方的冬天都遇到过车辆侧滑的情况,驾驶员发现预测车的行驶状况与实际不符,本来该直走的车怎么横着开了!这时驾驶员就根据这个误差迅速调整自身操作来纠正车辆行驶状态。这个过程就是我们期望机器人能够学会的快速适应能力。
对于一个要面对错综复杂真实世界的机器人来说,从先前经验中迅速、灵活地调整自身状态和行为适应环境是十分重要的。为了实现这个目标,研究人员开发了一种基于模型的元强化学习算法用于提高快速适应性。先前的工作主要基于试错的方法和无模型的元强化学习方法来处理这一问题,而在本文的研究人员将这一问题拓展到了极端情况,机器人在面对新情况时需要实时在线、在几个时间周期内迅速完成适应,所以实现这一目标的难度可想而知。基于模型的元学习方法不像先前方法基于目标的奖励来优化,而是利用每一时刻预测与观测间的误差作为数据输入来处理模型。这种基于模型的方法使机器人在使用少量数据的情况下实现对环境的实时更新。

这一方法利用了最近的观测数据来对模型进行更新,但真正的挑战在于如何基于少量的数据对复杂、非线性、大容量的模型(例如神经网络)进行自适应控制。简单的随机梯度下降方法对于需要快速适应的方法效率很低,神经网络需要大量的数据来训练模型才能实现有效的更新。所以为了实现快速的自适应调整,研究人员提出了新的方法。首先利用自适应目标对进行(元)训练,而后在使用时利用少量的数据进行精细训练以实现快速适应性调整。在不同情况下训练出的元模型将学会如何去适应,机器人就可以利用元模型在每一个时间步长上进行适应性更新以处理当前所面对的环境,以实现快速在线适应的目标。
元训练
机器人的运动离不开对状态的估计。在任意时刻下我们都可以对当前状态St,施加一定的行为at,从而得到下一时刻的状态St+1,这一状态的变化主要由状态转移函数决定。在真实世界中,我们无法精确建立状态转移动力学过程,但可以利用学习到的动力学模型进行近似,这样就可以基于观测数据进行预测。上图中的规划器就可以利用这一估计的动力学模型来进行行为调整。在训练时模型会选取最近的(M+K)连续的数据点序列,首先利用M个数据来更新模型的权重,随后利用身下的K个点来优化跟新后的模型对于新状态的预测能力。模型的损失函数可以表达为在先前K个点上进行适应后,在未来K个点上的预测误差。这意味着训练模型可以利用邻近的数据点迅速调整权重使自身可以进行较好的动力学预测。

为了测试这种方法对于环境突变的适应能力,研究人员首先在仿真机器人系统中进行了实验。研究人员在相同扰动下的环境中多所有主体进行了元训练,而在主体从未见过的环境及变化中进行测试。下面的猎豹模型在随机浮动的扰动上进行训练,随后在水上浮动的情况下进行了测试,机器人展现了快速适应环境变化的能力。右图显示了在断腿的情况下机器人的适应性:


机器人面对环境变化后的适应能力,图中展示了基于模型的方法和基于在线自适应的方法
对于多足机器人来说,在不同腿配置的情况下进行了训练,而在不同腿部损伤情况下进行了测试。这种基于模型的元强化学习方法使得机器人具有快速适应能力,更多的比较测试详见文末论文。
硬件实验
为了更好地验证算法在真实世界中的有效性,研究人员使用了具有高度随机性和动力学特性微型6足机器人。
快速制造技术和多种定制化的设计,使得每一个机器人的动力学特性都独一无二。它的零部件性能会随着使用逐渐退化,同时也能在不同地面上快速移动。这使机器人控制算法面临着会随时变化的环境状况,十分适合用于验证算法。研究人员首先在不同的地面状况下对机器人进行元训练,随后测试了机器在新情况下的在线适应能力。在断腿、新地表、斜坡路况、负载变化、错误标定扰动等情况下都表现良好。可以看到不同情况下最右边的在线适应方法更为稳定,适应不同情况的能力更强。腿断了也能尽力走直线了:
加上负载也不会走的歪歪扭扭:
位姿错误标定也能及时更新纠正:
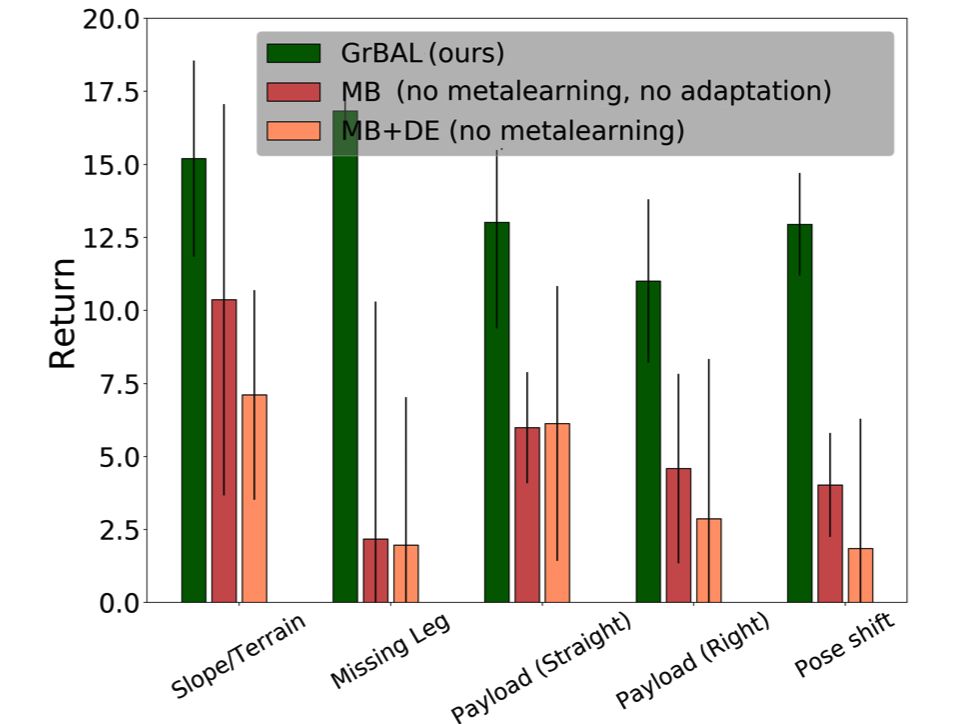
在和标准基于模型的方法(MB)、动力学评测的方法(MB+DE)比较中都显示了这种方法的优势。在各个指标上都取得了远超传统方法的结果。
在未来研究人员计划对模型进行改进,使它的能力随着时间逐渐增长而不是每次都需要从预训练模型进行精调。并能够记住在学习过程中学到的技能,将在线适应的学习到的新能力作为未来遇到新情况时的先验技能提高模型表现。
-
机器人
+关注
关注
211文章
28767浏览量
208994 -
算法
+关注
关注
23文章
4635浏览量
93502 -
强化学习
+关注
关注
4文章
268浏览量
11315
原文标题:伯克利提出高效在线适应算法,让机器人拥有快速适应环境变化的新能力
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于MPEG心理声学模型II的自适应音频水印算法
深度强化学习实战
一种适用于室内复杂环境的高精度、环境自适应性强的定位算法
一种新的具适应性的程序结构
深度强化学习到底是什么?它的工作原理是怎么样的
机器学习中的无模型强化学习算法及研究综述

模型化深度强化学习应用研究综述






 工商网监
工商网监
评论