 新的预训练方法——MASS!MASS预训练几大优势!
新的预训练方法——MASS!MASS预训练几大优势!

编者按:从2018年开始,预训练(pre-train) 毫无疑问成为NLP领域最热的研究方向。借助于BERT和GPT等预训练模型,人类在多个自然语言理解任务中取得了重大突破。然而,在序列到序列的自然语言生成任务中,目前主流预训练模型并没有取得显著效果。为此,微软亚洲研究院的研究员在ICML 2019上提出了一个全新的通用预训练方法MASS,在序列到序列的自然语言生成任务中全面超越BERT和GPT。在微软参加的WMT19机器翻译比赛中,MASS帮助中-英、英-立陶宛两个语言对取得了第一名的成绩。
BERT在自然语言理解(比如情感分类、自然语言推理、命名实体识别、SQuAD阅读理解等)任务中取得了很好的结果,受到了越来越多的关注。然而,在自然语言处理领域,除了自然语言理解任务,还有很多序列到序列的自然语言生成任务,比如机器翻译、文本摘要生成、对话生成、问答、文本风格转换等。在这类任务中,目前主流的方法是编码器-注意力-解码器框架,如下图所示。

编码器-注意力-解码器框架
编码器(Encoder)将源序列文本X编码成隐藏向量序列,然后解码器(Decoder)通过注意力机制(Attention)抽取编码的隐藏向量序列信息,自回归地生成目标序列文本Y。
BERT通常只训练一个编码器用于自然语言理解,而GPT的语言模型通常是训练一个解码器。如果要将BERT或者GPT用于序列到序列的自然语言生成任务,通常只有分开预训练编码器和解码器,因此编码器-注意力-解码器结构没有被联合训练,记忆力机制也不会被预训练,而解码器对编码器的注意力机制在这类任务中非常重要,因此BERT和GPT在这类任务中只能达到次优效果。
新的预训练方法——MASS
专门针对序列到序列的自然语言生成任务,微软亚洲研究院提出了新的预训练方法:屏蔽序列到序列预训练(MASS: Masked Sequence to Sequence Pre-training)。MASS对句子随机屏蔽一个长度为k的连续片段,然后通过编码器-注意力-解码器模型预测生成该片段。

屏蔽序列到序列预训练MASS模型框架
如上图所示,编码器端的第3-6个词被屏蔽掉,然后解码器端只预测这几个连续的词,而屏蔽掉其它词,图中“_”代表被屏蔽的词。
MASS预训练有以下几大优势:
(1)解码器端其它词(在编码器端未被屏蔽掉的词)都被屏蔽掉,以鼓励解码器从编码器端提取信息来帮助连续片段的预测,这样能促进编码器-注意力-解码器结构的联合训练;
(2)为了给解码器提供更有用的信息,编码器被强制去抽取未被屏蔽掉词的语义,以提升编码器理解源序列文本的能力;
(3)让解码器预测连续的序列片段,以提升解码器的语言建模能力。
统一的预训练框架
MASS有一个重要的超参数k(屏蔽的连续片段长度),通过调整k的大小,MASS能包含BERT中的屏蔽语言模型训练方法以及GPT中标准的语言模型预训练方法,使MASS成为一个通用的预训练框架。
当k=1时,根据MASS的设定,编码器端屏蔽一个单词,解码器端预测一个单词,如下图所示。解码器端没有任何输入信息,这时MASS和BERT中的屏蔽语言模型的预训练方法等价。

当k=m(m为序列长度)时,根据MASS的设定,编码器屏蔽所有的单词,解码器预测所有单词,如下图所示,由于编码器端所有词都被屏蔽掉,解码器的注意力机制相当于没有获取到信息,在这种情况下MASS等价于GPT中的标准语言模型。

MASS在不同K下的概率形式如下表所示,其中m为序列长度,u和v为屏蔽序列的开始和结束位置,x^u:v表示从位置u到v的序列片段,x^\u:v表示该序列从位置u到v被屏蔽掉。可以看到,当K=1或者m时,MASS的概率形式分别和BERT中的屏蔽语言模型以及GPT中的标准语言模型一致。

我们通过实验分析了屏蔽MASS模型中不同的片段长度(k)进行预训练的效果,如下图所示。
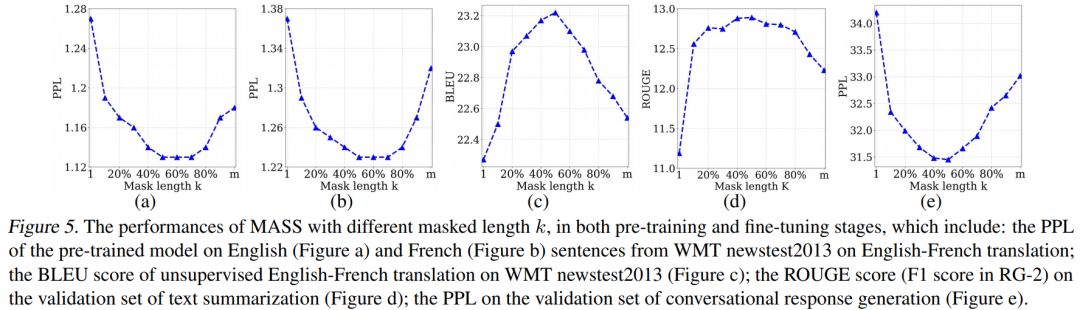
当k取大约句子长度一半时(50% m),下游任务能达到最优性能。屏蔽句子中一半的词可以很好地平衡编码器和解码器的预训练,过度偏向编码器(k=1,即BERT)或者过度偏向解码器(k=m,即LM/GPT)都不能在该任务中取得最优的效果,由此可以看出MASS在序列到序列的自然语言生成任务中的优势。
序列到序列自然语言生成任务实验
预训练流程
MASS只需要无监督的单语数据(比如WMT News Crawl Data、Wikipedia Data等)进行预训练。MASS支持跨语言的序列到序列生成(比如机器翻译),也支持单语言的序列到序列生成(比如文本摘要生成、对话生成)。当预训练MASS支持跨语言任务时(比如英语-法语机器翻译),我们在一个模型里同时进行英语到英语以及法语到法语的预训练。需要单独给每个语言加上相应的语言嵌入向量,用来区分不同的语言。我们选取了无监督机器翻译、低资源机器翻译、文本摘要生成以及对话生成四个任务,将MASS预训练模型针对各个任务进行精调,以验证MASS的效果。
无监督机器翻译
在无监督翻译任务上,我们和当前最强的Facebook XLM作比较(XLM用BERT中的屏蔽预训练模型,以及标准语言模型来分别预训练编码器和解码器),对比结果如下表所示。
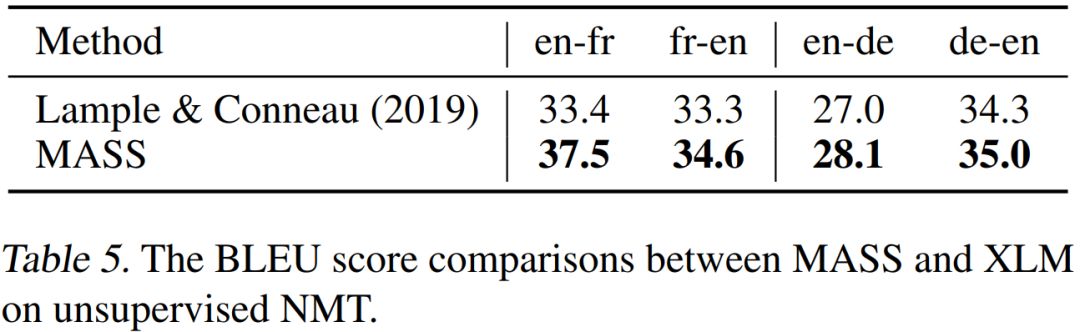
可以看到,MASS的预训练方法在WMT14英语-法语、WMT16英语-德语一共4个翻译方向上的表现都优于XLM。MASS在英语-法语无监督翻译上的效果已经远超早期有监督的编码器-注意力-解码器模型,同时极大缩小了和当前最好的有监督模型之间的差距。
低资源机器翻译
低资源机器翻译指的是监督数据有限情况下的机器翻译。我们在WMT14英语-法语、WMT16英语-德语上的不同低资源场景上(分别只有10K、100K、1M的监督数据)验证我们方法的有效性,结果如下所示。
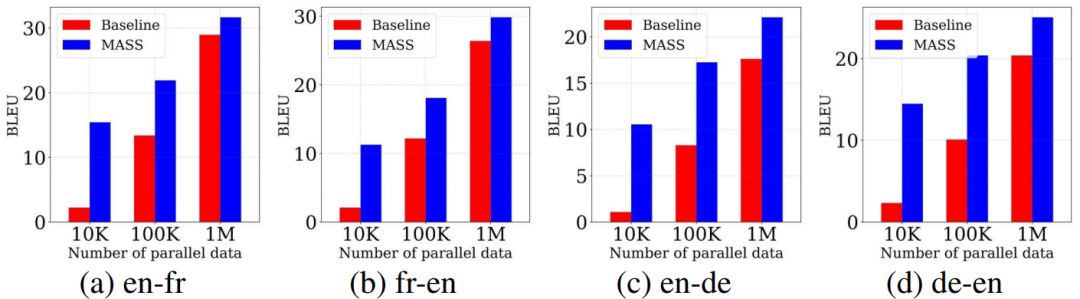
在不同的数据规模下,我们的预训练方法的表现均比不用预训练的基线模型有不同程度的提升,监督数据越少,提升效果越显著。
文本摘要生成
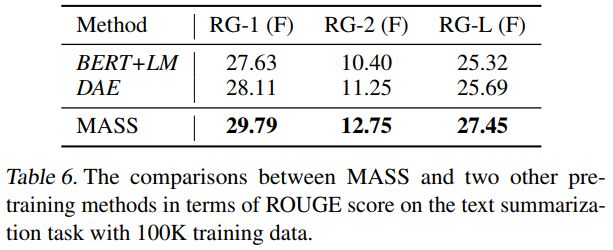
在文本摘要生成(Gigaword Corpus)任务上,我们将MASS同BERT+LM(编码器用BERT预训练,解码器用标准语言模型LM预训练)以及DAE(去噪自编码器)进行了比较。从下表可以看到,MASS的效果明显优于BERT+LM以及DAE。
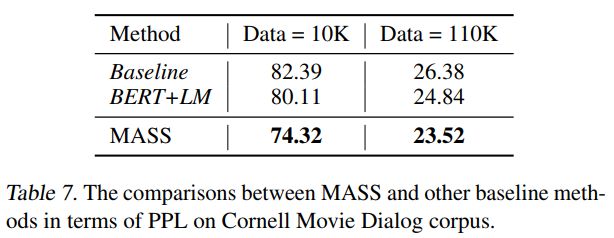
对话生成
在对话生成(Cornell Movie Dialog Corpus)任务上,我们将MASS同BERT+LM进行了比较,结果如下表所示。MASS的PPL低于BERT+LM。
在不同的序列到序列自然语言生成任务中,MASS均取得了非常不错的效果。接下来,我们还将测试MASS在自然语言理解任务上的性能,并为该模型增加支持监督数据预训练的功能,以期望在更多自然语言任务中取得提升。未来,我们还希望将MASS的应用领域扩展到包含语音、视频等其它序列到序列的生成任务中。
-
解码器
+关注
关注
9文章
1225浏览量
43790 -
编码器
+关注
关注
45文章
4013浏览量
143478 -
自然语言
+关注
关注
1文章
292浏览量
14027
原文标题:ICML 2019:序列到序列自然语言生成任务超越BERT、GPT!微软提出通用预训练模型MASS | 技术头条
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【大语言模型:原理与工程实践】大语言模型的预训练
微软在ICML 2019上提出了一个全新的通用预训练方法MASS

预训练语言模型设计的理论化认识

一种侧重于学习情感特征的预训练方法

Multilingual多语言预训练语言模型的套路
利用视觉语言模型对检测器进行预训练
什么是预训练 AI 模型?
什么是预训练AI模型?
基础模型自监督预训练的数据之谜:大量数据究竟是福还是祸?

基于生成模型的预训练方法




评论