 一种基于少样本目标类别图像的图像翻译模型
一种基于少样本目标类别图像的图像翻译模型

【导读】在已有的图像翻译研究中,模型需要使用大量的多类别图像数据,在一定程度上限制了模型的具体应用。本文提出了一种基于少样本目标类别图像的图像翻译模型,该模型在翻译准确度、内容保留程度、图像真实度和分布匹配度四个指标上都超越了现有模型的效果。
摘要
无监督的图像翻译方法通过在不同的非结构化图像数据集上进行学习,将指定类别的图像转换为另一类别的图像。现有方法虽然取得了一定进展,但在模型训练期间需要大量的源类别和目标类别的图像,限制了这类方法的实际应用。
本文通过将一个新的神经网络架构和对抗学习相结合,提出了一种少样本的无监督图像翻译算法。该模型能够使用少量样本图像,针对新出现的图像类别进行图片生成。作者将该模型与几种现有方法进行了比较,结果表明,这种基于少样本的无监督图像翻译算法非常有效。该论文的代码已开源,相关项目地址如下:
https://nvlabs.github.io/FUNIT
简介
人类非常擅长通过学习、类比推理等方法,将现有的知识泛化推广到一些未见过的问题上。例如,即使对于没见过老虎的人来说,当看到一只站立的老虎,他也能根据对其他动物的观察经验,联想到老虎躺着的样子。近来无监督的图像翻译研究在不同图像类别间的翻译中取得了长足的进步,但现有方法依然很难依据先验知识和少量新类别的样本图像,对图像进行泛化。
当前的图像翻译方法需要大量各类别的图像用于翻译模型的训练。针对这些问题,本研究提出一种少样本无监督图像翻译框架(Few-shot UNsupervised Image-to-image Translation, FUNIT),旨在只利用少量的目标类图像,通过学习到的图像翻译模型,将源图像类别图像范围为到目标类别的图像。
该模型的假设如下:人类基于少样本的生成能力来源于过去的视觉知识,且在之前看过的不同种类的物体越多,该泛化生成能力越强。基于此,本研究使用了一个包含多种类别图像的数据集训练FUNIT模型,用来模拟过去所学习的多类别视觉知识。模型的目标为,只利用目标类别的少量样本图像,实现从源类别到目标类别的图像翻译任务。
研究假设,通过在训练中学习从少量新类别图像中提取该图像类别的外观模式,模型能够学习一个通用的外观模式提取器,并将该模式应用于未见过的类别图像实现图像翻译。本文的实验数据证明,训练集类别数的增加对于少样本图像翻译模型的性能提升是有帮助的。
本文模型结构基于对抗生成网络(Generative Adversarial Networks, GAN)。作者将 GAN 和新的网络架构耦合,获得了较好的实验效果。通过在不同数据集上的实验将模型与几种基线方法进行对比分析,作者对模型的效果进行了验证,发现在各种性能指标上FUNIT框架的表现都更好。
方法
本文所提出的FUNIT框架旨在基于少量的目标类别图像,将源类别图像映射为一些模型未学习过的目标类别的图像。具体来说,在模型训练阶段,本文所使用的图像来自一组图像类别的数据集合(如各种动物类别的图像集),称之为源类别,用于训练多层级无监督的图像翻译模型FUNIT。
这里,本文假设在不同类别间不存在处于同一姿态的动物的图像。在测试时,本文使用少量取自类别的图像样本,称之为目标类别,这一类别在模型训练时未使用。模型利用这些少量的目标类别图像样本,能够实现从源类别到目标类别的图像翻译本文提出的模型主要包括两部分:一个少样本图像翻译器 G 和一个多任务对抗判别器 D 。
少样本图像翻译器 G
少样本图像翻译器 G 由一个内容编码器Ex,一个类编码器Ey和一个解码器Fx构成。其中内容编码器由多个 2D 卷积层和多个残差块(residual blocks)组成,用于将输入的内容图像x映射为内容潜在编码 zx ,其中 zx 是一个空间特征映射。类编码器包含多个2D卷积层并对卷积结果取均值。
而解码器是由多个采用自适应实例正则化方法(AdaIN)的残差块和多个卷积层结构组成。对于每个样本,AdaIN方法对每个通道的样本激活值进行正则化,以获得其零均值和单元方差,之后通过一个仿射变换来缩放激活值。
如下图1所示,该仿射变换具有空间不变性,因此仅可以用于得到全局的外观特征信息。内容编码器能够提取到不随类别改变的隐层表征信息,而类别编码器学习特定类别的隐层表征。文本通过AdaIN层将类编码馈送到解码器,并使用类别图像来控制所生成的图像全局外观,使用内容图像决定图像的局部结构。
图1 训练:训练集数据由各种不同类别图像构成(源类别),用于训练一个图像翻译模型。部署:展示了所提出的模型基于少量目标类别图像进行图像翻译的表现。FUNIT 中生成器的输入由两部分构成:1)内容图像;2)目标类别图像集。旨在通过输入与目标类相似的图像来实现少样本图像翻译。
不同于现有的图像翻译研究中使用的条件图像生成器,这里G同时采用一张内容图像x和K个目标类别图像作为输入,并生成输出图像。假定内容图像属于类别cx,而每个K类图像属于类别cy。另外,K是个很小的数字,且cx与cy属于不同类别。如下图2所示。
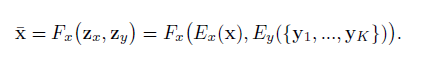
图2 仿射变换表达式
G将一张输入的内容图像映射到属于类别cy的输出图像,二者在图像结构上有一定的相似度。以S和T分别代表源图像和目标图像集,在训练期间从两个集合中随机抽取图像供G学习,在测试期间G从目标集中抽取一些未见过的类别图像,并将源图像集数据类别映射到目标类图像上。
多任务对抗判别器 D
判别器D的训练是同时在几种对抗二分类任务上进行的,其用于判别输入图像是源类别的真实图像还是生成的目标类别图像。由于这里存在S个源图像类别,因此D将对应生成S个输出。当更新D时,根据输出的结果,相应地惩罚D。当更新G时,只有当输出结果为假时才选择惩罚D。经验上来说,通过这种方法处理后的判别器D能够在S多分类任务上表现得更好。
此外,FUNIT框架所采用的损失函数如图3所示:由GAN模型损失、内容图像重构损失和特征匹配损失构成。

图3 FUNIT 框架的损失函数表达式
GAN模型损失的计算如图4:

图4 GAN 模型的损失表达式
重构损失的数学表达式如图5:

图5 重构损失表达式
而图像特征匹配损失旨在最小化目标类图像特征与翻译输出结果图像之间特征匹配度,如图6:

图6 特征匹配损失表达式
实验
实验部分使用如下四种数据集:
动物面孔数据集:从ImageNet数据集中抽取149种卡通动物类别,共含117574张图像。
鸟类数据集数据集:包含48527张攻击555种北美鸟类图像数据。
花卉数据集:102类共8189张包含花的图像。
事务数据集:来自256种共31395张食物图像数据。
基准方法分别使用的是StarGAN-Fair-K、 StarGAN-Fair-K 、CycleGAN-Unfair-K、UNIT-Unfair-K和MUNIT-Unfair-K 五种,分别通过翻译准确率(translation accuracy)、内容保留程度(content preservation)、图像真实度(photorealism)和 分布匹配度(Distribution matching)四种指标来评估各种方法的性能。
总体结果FUNIT与基准方法在不同数据集的实验结果如下图7所示。

图7各方法的性能对比
可以看到,FUNIT框架在少样本无监督图像翻译任务上所有的性能指标都超过了所有基准方法的表现:在Animal Faces数据集的1-shot和5-shot设置上分别达到82.36和96.05的Top-5测试精度,在North American Birds数据集上分别达到60.19和75.75的Top-5测试精度。图8对FUNIT-5模型在少样本图像翻译任务上的结果进行了可视化。
图8 FUNIT-5模型的少样本无监督图像翻译结果的可视化展示。从上到下,分别采用是动物面孔、鸟类、花卉和食物数据集样本。
可以看到FUNIT模型能够成功地实现从源图像到新类别图像的翻译。此外,在图9还提供了一些可视化的对比结果。
图9少样本图像翻译性能的结果对比
用户研究本文在Amazon Mechanical Turk (AMT)平台上通过人类评估法来进一步验证了图像翻译结果的可信度和真实度,结果如图10所示。

图10用户偏好得分结果
用户偏好得分评估结果表明,相比于其他方法,FUNIT-5模型的翻译结果与目标类图像的相似度更高,可靠性更强。
训练集源类别数量下图11展示了在动物数据集上,当类别数量发生变化时,FUNIT-5模型的性能表现变化。这里只展示了类别数从69到119以间隔10变化时模型的表现。
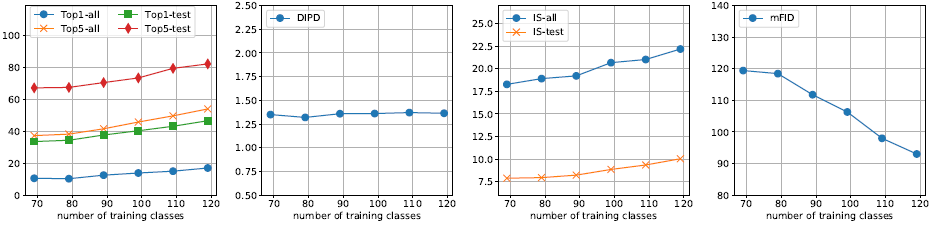
图11少样本图像翻译性能vs 动物面孔数据集目标类别数
可以看到,FUNIT模型的翻译性能与目标类别数呈正相关关系,即类别数越多,翻译性能越好。此外,研究中还进行了参数分析(parameter analysis)、消融实验(ablation study)、隐层插值(latent interpolation)、失败样本分析(failure cases)等评估,具体信息可以查阅原论文的说明。
总结
本文介绍了首个少样本无监督图像翻译框架FUNIT,该模型利用少量的目标类别图像,实现了从源类别图像到目标图像的翻译,并展示了该框架的性能与目标类别数的关系。FUNIT由三部分构成:1)内容编码器:用于学习类别不变编码;2)类编码器:用于学习特定类别编码;以及3)解码器。
总的来说,FUNIT框架能够实现非常出色的图像翻译,但当目标类别与源图像有显著差异时,也会存在一些失败的情况。在失败样本中,FUNIT方法仅对源图像的颜色进行了变更,而改变图像的其他外观特征,这也是未来研究的方向。
-
编码器
+关注
关注
45文章
4021浏览量
143671 -
图像数据
+关注
关注
0文章
54浏览量
11711 -
数据集
+关注
关注
4文章
1242浏览量
26282
原文标题:四大指标超现有模型!少样本的无监督图像翻译效果逆天| 技术头条
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
一种改进的矩不变自动阈值算法
一种基于图像平移的目标检测框架
序列图像运动目标检测的一种快速算法
一种新的DSA图像增强算法

一种图像拼接的运动目标检测方法
一种融合图像纹理结构信息的LDA扣件检测模型
一种图像去雾新算法
一种改进的基于LRC-SNN的图像重建与识别算法

一种基于改进的DCGAN生成SAR图像的方法





评论