 看图“猜车祸”,用谷歌街景数据建立车祸预测新模型
看图“猜车祸”,用谷歌街景数据建立车祸预测新模型
预测是机器学习算法最重要的一个研究方向。众多保险公司利用机器学习算法为他们的客户建立预测模型。其中,车祸预测模型是众多模型里面最难建立的。
车祸发生的影响因素多种多样,变化多端,着实让人摸不着头脑。
与其他商品不同的是,车祸保单的最终成本在初始销售时是未知的。因此,建立一个合理的定价机制是非常具有挑战的。有些保险公司尝试使用统计方法来解决这一问题:预测每个客户的未来风险。
例如,非常经典的汽车保险。大部分的保险公司确定的保险风险因素有司机的年龄、他的汽车配置相关以及汽车发生事故的历史情况。这也是为什么保险公司会在成交汽车保险之前需要客户提供的详细信息的原因。
下载地址:
https://arxiv.org/abs/1904.05270
波兰华沙大学经济科学系的Kinga Kita-Wojciechowska和斯坦福大学生物工程系的Łukasz Kidziński利用谷歌Google街景收集相对应的房屋图像,通过标释房屋的特征:例如年龄、类型以及其它条件。然后与目前最先进的保险风险模型相比,最后发现用谷歌街景数据建立的模型,能够有效地改进了汽车事故风险预测。
作者通过对谷歌街景数据的研究,发现下列结论☟
房子的特征与居民的发生车祸风险相关,
与谷歌街景的其他研究用途相比,此模型数据特征来自于地址,并不是按照邮政编码或地区进行汇总,可能存在更为精细的划分;
从地址中提取的数据(房屋的图像)可用于保险和其他行业;
现代数据收集和科技技术允许对个人数据进行前所未有的利用,可能会超过立法的发展速度,并增加个人隐私威胁。
建模数据收集方法与特点
保险公司之前进行的风险建模和定价,通常只使用邮政编码这一特征。然而汇总到邮政编码的索赔数据仍然太不稳定,所以还需要进一步地调整。
另一方面,对于一些“外人”来说,保险公司客户的信息数据很难获得。本文使用的谷歌街景数据可以从来自Google街景的公开图像信息中提取出来。
图1.位于同一邮政编码中不同房屋的示例,根据当前保险公司的模型,这些房屋的居民具有相同的预期索赔频率。
此数据集包含20,000条记录的汽车保险数据集,数据来源于2012年1月至2015年12月期间收集到在波兰的保险投资组合的随机样本。
其中每项记录均涵盖汽车发动机第三方责任(MTPL)保险单的特点,包括投保人的地址、风险敞口(定义为一小部分有效年份在2013-2015年期间的保单)以及2013-2015年间发生的财产损坏索赔的统计数量。保险公司还提供了这些保单的财产损失索赔的预期频率,是根据他们目前最好的风险模型进行估计的,是根据客户的邮政编码进行分区的。
图2.使用注释功能将为数据库中提供的地址,匹配收集谷歌卫星视图和谷歌街景图像。
对图像中可见的房屋中以下特征作了说明:居民的年龄、状况、财富以及邻近地区其他建筑物的类型。根据Fleiss’kappa(属性型测量分析)统计数据结果表明,它们之间大多数是一致稳健的。
继续注释剩余的19,371个地址(还从本研究的范围中删除了129个地址,因为它们要么是另外区域的,要么是Google地图找不到的),剩余的都将得到了一组单独的、随机选择的地址。
研究者比较了收集到的注释的分布情况,并在最后对四个注释器进行了小的修正,以匹配平均值和标准差。
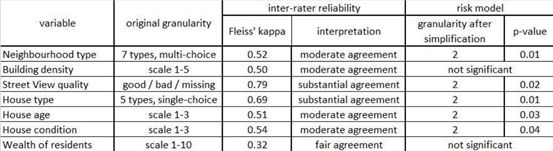
表1。在进行了必要的简化后,风险模型中对7个新创建的变量进行了统计
建模过程
接下来,估计一个广义线性模型(GLM)来研究新创建的变量对于风险预测的重要性。
假设索赔的概率模型如下:
频率为f,定义为索赔次数除以风险敞口:
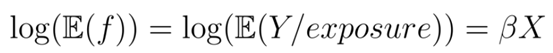
其中,MTPL保险中的一些财产损失索赔是服从泊松分布的,X是自变量的向量,也是系数的向量。
为了对方法所带来的增加值进行评价,引入了三个模型:
模型A(空模型),其中向量为
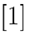
模型B(一流保险商模型):其中向量为
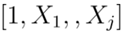
模型C(研究者使用的模型):其中向量为
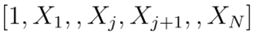
保险人为数据集中的每条记录提供了模型B的实现。
该模型是在一个更大的未对外披露数据集上进行估计的,包含j个预测变量(驾驶员特征、车辆特征、索赔历史、地理区域等)。
利用GLMs的特性,可以将模型C分解为两个部分:一个对应于模型B,另一个则包含新变量。
因此,模型C为:
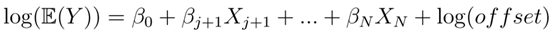
这些系数的值是否为非零,将表明研究者构造的变量为模型提供了额外的预测能力。在本研究中新创建的七个变量中,有五个对于预测财产损坏MTPL索赔频率模型具有重要意义,而在最好的保险公司模型中使用的许多其它评级变量都是重要的(表1)。
通过观察a、B、C模型的基尼系数的显著变异性,特别是对于模型A(只包含截距且没有选择其他变量的空模型)在20次重采样试验中,其变化范围为20 ~ 38%。将其解释为证据,即所提供的数据集非常小(20,000条记录),用于构建MTPL保险中的罕见事件,如财产损失索赔(平均频率为5%)。
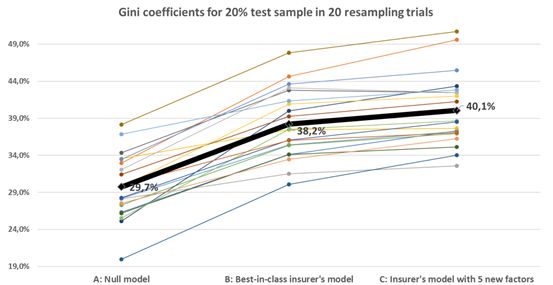
图3.在20个自举试验中获得的20%的检验样本上的基尼系数(A),从零模型(A)到最好的保险公司的模型(B)和研究者新建立的变量模型(C)。
尽管数据的波动性很大,但将五个简单变量加入到保险公司的模型中,在20次重新采样试验中的18次中尝试,提高了它的性能,并提高了基尼系数的平均水平。提高系数接近2个百分点(从38.2%到40.1%)。
通常保险公司的模型会运用更大的数据集,并包含了广泛的变量选择(例如驾驶员特征、汽车特征、索赔历史和基于客户邮政编码的地理区域),将基尼系数与空模型从0~30%提高到0~38%,提高了8个百分点(见图3)。
创新之处
通常保险公司的预测模型都是以常规的特征进行预测的,比如驾驶车辆习惯,索赔历史和客户财富级别等特征。
但是文中的模型使用了全新的谷歌街景地图的特征,比如街景地图中房屋所在周围环境,所在区域的密度,街景的质量和房屋类型年限等特征,评测结果也是比较令人欣慰,三个模型的基尼系数变动范围在20%—38%之间,我们能从图3中看见,经过20次的重采样实验得到的结果:具有街景新特征的模型比使用原有的优秀传统模型还要高出接近2个百分点。
当然由于数据样本量比较少,大概只有2万条左右,所以这也在一定程度上影响了基尼系数的提升。但是这在预测模型的研究方向中,给了我们一个新的思路,原来街景地图的特征会比传统的特征更加有效。当然未来肯定还会有更加有效的特征出现,来帮助我们提升预测准确度。
译者注:
基尼系数通常判定超过60%就是一个好模型,但是文章中的数据量有点少,所以这个系数可能没有60%,但是肯定不能说这个思路错的,希望大家可以尝试自己更换数据集来做复现。
总结
从一张房子的图像中可见的特征预测发生车祸的风险,而且独立于经常使用的变量,如年龄或邮政编码。
这一发现迈出了一大步。它不仅提供了更为精确的风险预测模型,而且还说明了社会科学的一种新方法。
在这种方法中,真实世界中的细粒度数据可以经过大规模收集后进行分析。从保险公司的实际情况来看,给出的实验结果是显著的。研究者使用的模型中的5个变量包含了来自不完全注释的一些偏差,与保险公司在其最佳风险模型中已经使用的众多变量带来的8个百分点的改进相比,基尼系数提高了近2个百分点。
保险行业可能很快就会被银行效仿,因为保险风险模型与信用风险之间存在着已被证明的相关性。从谷歌街景(GoogleStreetView)中提取有价值信息的方法本身,不仅为金融业提供了各种机会。
此方法和深层次的学习技术可以使它在一个大规模自动化的模型中进行。同时,这种做法引起了人们对存储在公开可用的Google街景、Microsoft Bing Streetside、Mapillary或类似的私有数据集中的数据隐私的担忧。
客户同意公司存放其地址信息并不一定意味着同意储存有关其房屋外观的信息。特别是房屋的特征可以是种族、宗教或与一个人的社会地位有关的其他特征的代名词,法律上也禁止将这些特征用于任何歧视,例如某些区域的价格歧视。
-
谷歌
+关注
关注
27文章
6171浏览量
105497 -
机器学习
+关注
关注
66文章
8422浏览量
132743
原文标题:[机器人频道|物联网]斯坦福最新研究:看图“猜车祸”,用谷歌街景数据建立车祸预测新模型
文章出处:【微信号:robovideo,微信公众号:机器人频道】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
看齐iPhone!三星Galaxy S25 Ultra将搭载车祸检测传感器
谷歌发布革命性AI天气预测模型NeuralGCM
matlab预测模型怎么用
arimagarch模型怎么预测
神经网络预测模型的构建方法
谷歌模型框架是什么软件?谷歌模型框架怎么用?
谷歌模型怎么用手机打开
谷歌模型软件有哪些功能
谷歌模型怎么用PS打开文件和图片
谷歌模型合成工具怎么用






 工商网监
工商网监
评论