 网络处理器的应用场景
网络处理器的应用场景
曾几何时,网络处理器是高性能的代名词。为数众多的核心,强大的转发能力,定制的总线拓扑,专用的的指令和微结构,许多优秀设计思想沿用至今。Tilera,Freescale,Netlogic,Cavium,Marvell各显神通。但是到了2018年,这些公司却大多被收购,新闻上也不见了他们的身影,倒是交换芯片时不时冒出一些新秀。
随着移动互联网的兴起,网络设备总量实际上是在增加的。那为什么网络芯片反而没声音了呢?究其原因有几点:
第一, 电信行业利润率持续减少。10年之前,Freescale的65纳米双核处理器,可以卖到40美金。如今同样性能的28纳米芯片,10美金都卖不到。而网络处理器的量并不大,低端有百万片已经挺不错了,高端更是可能只有几万片。这使得工程费用无法均摊到可以忽略的地步,和手机的动辄几亿片没法比。而单价上,和服务器上千美金的售价也没法比。这就使得网络处理器陷入一个尴尬境地。
第二, IP模式的兴起。利润的减少导致芯片公司难以维持专用处理器设计团队。电信行业的开发周期普遍很长,而网络处理器从立项到上量,至少需要5年时间,供货周期更是长达15年。一个成熟的CPU团队,需要80人左右,这还不算做指令集和基础软件的,全部加上超过100人。这样的团队开销每年应该在2000万刀。2000万刀虽然不算一个很大的数字,可如果芯片毛利是40%,净利可能只有10%,也就是要做到2亿美金的销售额才能维持。这还只是CPU团队,其余的支出都没包含。通常网络芯片公司销售额也就是5亿美金,在利润不够维持处理器研发团队后,只能使用通用的IP核,或者对原有CPU设计不做改动。另外,还要担心其他高利润公司来挖人。以Freescale为例,在使用PowerPC的最后几年,改了缓存设计后,甚至连验证的工程师都找不到了。
第三, 指令集的集中化。在五年前,网络处理器还是MIPS和PowerPC的世界,两个阵营后各有几家在支持。当时出现了一个很有趣的现象,做网络设备的OEM公司会主动告诉芯片公司,以后的世界,是x86和ARM指令集的世界,为了软件的统一,请改成ARM指令集。在当时,ARM指令集在网络界似乎只有Marvell一家在使用。而五年之后的现在,PowerPC和MIPS基本退出舞台,只有一些老产品和家用网关还有它们的身影。
在网络处理器领域,ARM并无技术和生态优势:技术上,MIPS大都是单核多线程的,支持自定义的指令集,对一些特定的网络包处理添加新指令。而PowerPC很早就使用了Cache
Stashing等专用优化技术,ARM直到近两年才支持。即使使用了ARM指令集,Cavium和Netlogic还是自己设计微结构。生态上,电信产品的应用层软件,都是OEM自定义的。底层操作系统,Linux和VxWorks,对MIPS和PowerPC的支持并不亚于ARM。而中间层的软件,虚拟机和数据转发,NFV等,网络芯片公司之前也并不是依靠ARM来维护的。赢得网络处理器市场还真是ARM的意外之喜。
第四, OEM公司自研芯片的崛起。思科,华为,中兴等公司,早就开始自己做技术含量高的高端芯片,或者量大的低端芯片。对于高端产品,只有使用自研芯片才能抢到第一个上市,对于低端产品,就主要是成本考虑了。
让我们看看网络处理器到底能应用在哪些场景:
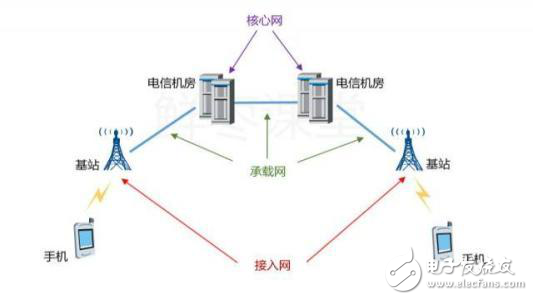
首先,是终端设备(手机/基站,wifi,光纤/Cable/ADSL等),连接到接入网,然后再汇聚到核心网。就节点吞吐量而言,大致可以分为几类:
第一, 在终端,吞吐量在1Gbps级别,可以是手机,可以是光纤,可以是有线电视,也可以是Wifi,此时需要小型家庭路由器,无需专用网络加速器,对接口有需求,比如ATM,光纤,以太网或者基带芯片。
第二, 在基站或者边缘数据中心,吞吐量在1Tbps级别,此时需要边缘路由器,基站还需要FPGA或者DSP做信号处理。
第三, 在电信端,吞吐量远大于1Tbps,此时需要核心路由器,由专用芯片做转发。
以上场景中,低端的只需要1-2核跑所有的数据面和控制面程序就行;对于中端应用,控制面需要单核能力强的处理器,数据面需要能效高,核数众多的处理器和网络加速器;高端路由器需要专用asic进行数据面处理,同时使用单核能力强的处理器做控制面。
这其中比较有争议的是中端的数据面处理。对中断路由器来说,业务层的协议处理,毫无疑问的该使用通用处理器;而一些计算密集的功能,比如模板检测,加解密,压缩,交换等,还是用asic做成模块比较合适;对于队列管理,保序,优先级管理,资源管理等操作,就见仁见智了。从能效和芯片面积上来说,通用处理器做这些事肯定不是最优的,但是它设计容错性高,扩展性好,产品设计周期短,有着专用加速器无法取代的强项。硬件加速器本身会有bug,需要多次流片才能成熟,这非常不利于新产品的推广,而通用处理器方案就能大大减少这个潜在风险。专用网络加速器还有个很大的缺点,就是很难理解和使用,OEM如果要充分发挥其性能,一定需要芯片公司配合,把现有代码移植,这其中的推广时间可能需要几年。不过有时候芯片公司也乐见其成,因为这样一来,至少能把这一产品在某种程度上和自己捆绑一段时间。
再进一步,有些任务,如路由表的查找,适合用单核性能高的处理器来实现;有些任务,如包的业务代码,天然适合多线程,用多个小核处理更好。这就把通用处理器部分也分化成两块,大核跑性能需求强的代码,小核跑能效比需求强的代码。大小核之间甚至可以运行同一个SMP操作系统,实现代码和数据硬件一致性。事实上,有些网络处理器的加速器,正是用几十上百个小CPU堆起来的。
在网络芯片上,有两个重要的基本指标,那就是接口线速和转发能力。前者代表了接口能做到的数据吞吐量上限,后者代表了处理网络包的能力。

如上图,以太网包最小的长度是64字节,这只是数字部分的长度。考虑到PHY层的话,还有8字节的Preamble和开始标志,外加帧间分隔,总共84字节。
对于1Gbps的以太网,能够发送的以太网包理论上限是1.45Mpps(Million Packet Per Second)。相应的,处理器所能处理的包数只需要1.45Mpps,超出这个数字的能力是无用的。线速一定时,以太网包越大,所需的处理能力越低,所以在衡量处理器能力的时候,需用最小包;而在衡量网络接口能力的时候,需要用最大包,来使得帧间浪费的字段达到最小比例。
下面是Freescale的LX2160网络处理器的指标:
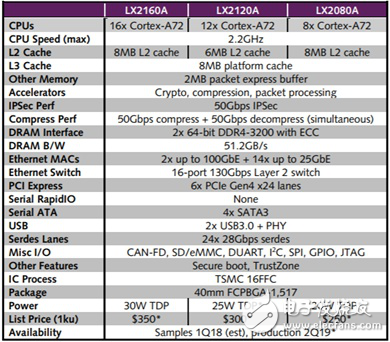
我们可以看到,共有24个28Gbps的Serdes口,对应的,2个100G以太网口需要8个Serdes口,而14个25G以太网口需要14个Serdes口,共22×25=550Gbps的吞吐率,最大需要800Mpps的处理能力。分散到16个核,每个核需要50Mpps的转发能力,对应到2.2Ghz的处理器,也就是44个时钟周期处理一个包。事实上,这是不现实的。通常,一个包经过Linux协议栈,即使什么都不做,也需要1500个时钟周期,就算使用专业转发软件,至少也需要80个左右。所以,最小64字节包只是一个衡量手段,跑业务的时候肯定需要尽量使用大包。
所以,在定义网络处理器的规格时,需要在线速和处理能力上做平衡。

上图是Freescale的LX2160网络处理器内部模块图。按照之前的线速和处理能力来看,可以分为三块:
第一, 处理器部分。这里是16个A72核,每两个放在一个组里,分配1MB二级缓存。在手机上,通常是四个核放在一组,这里为什么是两个?因为网络处理主要是针对包的各种处理,更偏重于IO和访存的能力,而不仅仅是计算。在处理包时,不光是网络包的数据需要读进处理器,还需要读入各种参数,来完成对包的处理。这些参数针对每个包会有所不同,缓存可能是放不下的,需要从内存读取。这就造成了需要相对较大的带宽。在架构篇,我们定量计算过,当只有一个处理器在做数据读取的时候(假设都不在缓存),瓶颈在核的对外接口BIU,而四个核同时读取,瓶颈在ACE接口。这就是每组内只放两个核而不是四个的原因。而处理器总的核数,很大程度上决定了网络处理器的包处理能力。
第二, 接口部分。网络处理器通常会把控制器(以太网,SATA,PCIe等)和高速串行总线口Serdes复用,做成可配置的形式,提高控制器利用率,节省面积。这里使用了24对差分线,每条通道支持25Gbps。高速串行总线设计也是一个难点,经常会有各种串扰,噪声,抖动等问题,搞不好就得重新流片。(推荐阅读:又见山人:为什么串口比并口快?)
第三, 网络加速器,上图中的WRIOP和QB-Man属于网络加速器。这是网络处理器精华的设计,其基本功能并不复杂,如下图:

一个包从以太网进来,如果没有以太网加速器,那会被以太网控制器用DMA的方式放到内存,然后就丢给CPU了。而硬件加速器的作用,主要是对包的指定字段进行分析,打时间戳,然后分类并分发到特定的队列。而这些队列,在经过重映射后,会提供给CPU来处理。这其中还牵涉到队列关系,优先级,限速,排序,内存管理等功能。加解密模块可以看作独立的模块。就我所见,网络加速器需要和所有处理器之和相近的面积。
我们来看看一个包到底在网络处理器会经历哪些步骤:
首先,CPU调用以太网驱动,设置好入口(Ingress)描述符。以太网控制器根据描Ingress述符将Serdes传来的包,DMA到指定内存地址,然后设置标志位,让CPU通过中断或者轮询的方式接收通知。然后CPU把包头或者负载读取到缓存,做一定操作,然后写回到出口(Egress)描述符所指定的内存,并再次设置标志位,通知以太网控制器发包。Ingress和Egress包所存放的地址是不同的。以太网控制器根据Egress描述符将包发送到Serdes,并更新描述符状态。
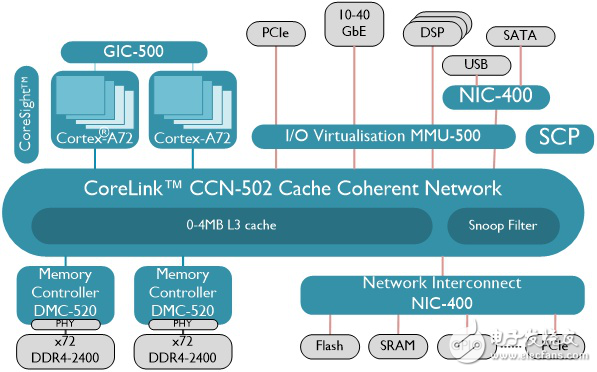
将上述步骤实现到上图的系统中,并拆解成总线传输,是这样的(假定代码及其数据在一二级缓存中):
1. CPU写若干次以太网控制器(10-40GbE)的寄存器(Non-cacheable)
2. CPU读若干次以太网控制器(10-40GbE)的状态寄存器(Non-cacheable)
3. 以太网控制器(10-40GbE)进行若干次DMA,将数据从PHY搬到内存
4. CPU从内存读入所需包头数据,做相应修改
5. CPU写入内存所需数据
6. CPU写若干次以太网控制器(10-40GbE)的寄存器(Non-cacheable)
7. 以太网控制器(10-40GbE)进行若干次DMA,将数据从内存搬到PHY,并更新内部寄存器
8. CPU读若干次以太网控制器(10-40GbE)的状态寄存器(Non-cacheable)
以上8步所需时间通常为:
1. 1x以太网寄存器访问延迟 。假定为20ns。
2. 1x以太网寄存器访问延迟。假定为20ns。
3. 以太网控制器写入DDR的延迟。假设是最小包,64字节的话,延迟x1。如果是大包,可能存在并发。但是和第一步中CPU对寄存器的写入存在依赖关系,所以不会小于延迟x1。假定为100ns。
4. CPU从DDR读入数据的延迟。如果只需包头,那就是64字节,通常和缓存行同样大小,延迟x1。假定为100ns。
5. CPU写入DDR延迟x1。假定为100ns。
6. 1x以太网寄存器访问延迟 。假定为20ns。
7. 以太网从DDR把数据搬到PHY,延迟至少x1。假定为100ns。
8. 1x以太网寄存器访问延迟。假定为20ns。
2和3,7和8是可以同时进行的,取最大值。其余的都有依赖关系,可以看做流水线上的一拍。其中4,5和6都在CPU上先后进行,针对同一包的处理,它们无法并行(同一CPU上的不同包之间这几步是可以并行的)。当执行到第6步时, CPU只需要将所有非cacheable的写操作,按照次序发出请求即可,无需等待写回应就可以去干别的指令。这样,可以把最后一步的 所流水线中最大的延迟缩小到100+20+100共220ns以下的某个值。当然,因为ARM处理器上non-cacheable的传输,在对内部很多都是强制排序的,无法并行,总线也不会提早发送提前回应(early response),所以总延迟也就没法减少太多。
上面的计算意味着,CPU交换一下源和目的地址,做一下简单的小包转发,流水后每个包所需平均延迟是220ns。同时,增大带宽和CPU数量并不会减少这个平均延迟,提高CPU频率也不会有太大帮助,因为延迟主要耗费在总线和DDDR的访问上。提高总线和DDR速度倒是有助于缩短这个延迟,不过通常能提高的频率有限,不会有成倍提升。
那还有什么办法吗?一个最直接的办法就是增加SRAM,把SRAM作为数据交换场所,而不需要到内存。为了更有效的利用SRAM,可以让以太网控制器只把包头放进去,负载还是放在放DDR,描述符里面指明地址即可。这个方法的缺点也很明显:SRAM需要单独的地址空间,需要特别的驱动来支持。不做网络转发的时候,如果是跑通用的应用程序,不容易被利用,造成面积浪费。
第二个方法是增加系统缓存,所有对DDR的访问都要经过它。它可以只对特殊的传输分配缓存行,而忽略其余访问。好处是不需要独立的地址空间,缺点是包头和负载必须要指定不同的缓存分配策略。不然负载太大,会占用不必要的缓存行。和SRAM一样,包头和负载必须放在不同的页表中,地址不连续。
在有些处理器中,会把前两个方法合成,对一块大面积的片上内存,同时放缓存控制器和SRAM控制器,两种模式可以互切。
第三个方法,就是在基础篇提到的Cache stashing,是对第二种方法的改进。在这里,包头和负载都可以是cacheable的,包头被以太网控制器直接塞到某个CPU的私有缓存,而负载则放到内存或者系统级缓存。在地址上,由于缓存策略一致,它们可以是连续的,也可以分开。当CPU需要读取包头时,可以直接从私有缓存读取,延迟肯定短于SRAM,系统缓存或者DDR。再灵活一点,如果CPU需要更高层协议的包头,可以在以太网控制器增加Cache sashing的缓存行数。由于以太网包的包头一定排列在前面,所以可以将高层协议所需的信息也直接送入某个CPU一二级私有缓存。对于当中不会用到的部分负载,可以设成non-cacheable的,减少系统缓存的分配。这样的设计,需要把整个以太网包分成两段,每一段使用不同的地址空间和缓存策略,并使用类似Scatter-Gather的技术,分别做DMA,增加效率。这些操作都可以在以太网控制器用硬件和驱动实现,无需改变处理器的通用性。
此外,有一个小的改进,就是增加缓存行对CPU,虚拟机,线程ID或者某个网络加速器的敏感性,使得某些系统缓存行只为某个特定ID分配缓存行,可以提高一些效率。
以上解决了CPU读包头的问题,还有写的问题。如果包头是Cacheable的,不必等待写入DDR之后才收到写回应,所以时间可以远小于100ns。至于写缓存本身所需的读取操作,可以通过无效化某缓存行来避免,这在基础篇有过介绍。这样,写延迟可以按照10-20ns计算。
以太网控制器看到Egress的寄存器状态改动之后,也不必等待数据写到DDR,就可以直接读。由于存在ACE/ACE-lite的硬件一致性,数据无论是在私有缓存,系统缓存还是DDR,都是有完整性保证的。这样一来,总共不到50ns的时间就可以了。同理,Ingress通路上以太网控制器的写操作,也可以由于缓存硬件一致性操作而大大减少。
相对于第二种方法,除了延迟更短,最大的好处就是,在私有缓存中,只要被cache stashing进来的数据在不久的将来被用到,不用担心被别的CPU线程替换出去。Intel做过一些研究,这时间是200ns。针对不同的系统和应用,肯定会不一样,仅作参考。
让我们重新计算下此时的包处理延迟:
原来的第四步,CPU读操作显然可以降到10ns之下。
访问寄存器的时间不变。
CPU写延迟可以按照10-20ns计算。
总时间从220降到了50ns以下,四倍。
不过,支持Cache Stashing需要AMBA5的CHI协议,仅仅有ACE接口是不够的。CPU,总线和以太网控制器需要同时支持才能生效。如果采用ARM的CPU设计,需要最新的A75/A55才有可能。总线方面,A75/A55自带的ACP端口可用于20GB以下吞吐量的Cache Stashing,适合简单场景,而大型的就需要专用的CMN600总线以支持企业级应用了。还有一种可能,就是自己做CPU微架构和总线,就可以避开CHI/ACE协议的限制了。
Intel把cache stashing称作Direct Cache Access,并且打通了PCIe和以太网卡,只要全套采用Intel方案,并使用DPDK软件做转发,就可以看到80时钟周期,30-40ns的转发延迟。其中,DPDK省却了Linux协议栈2000时钟周期左右的额外操作,再配合全套硬件机制,发挥出CPU的最大能力。
这个40ns,其实已经超越了很多网络硬件加速器的转发延迟。举个例子,Freescale前几年基于PowerPC的网络处理器,在内部其实也支持Cache Stashing。但是其硬件的转发延迟,却达到了100ns。究其原因,是因为在使用了硬件加速器后,其中的队列管理相当复杂,CPU为了拿到队列管理器分发给自己的包,需要设置4次以上的寄存器。并且,这些寄存器操作无法合并与并行,使得之前的8步中只需20ns的寄存器操作,变成了80ns,超越CPU的数据操作延迟,成为整个流水中的瓶颈。结果在标准的纯转发测试中,硬件转发还不如x86软件来的快。
除了减少延迟,系统DDR带宽和随之而来的功耗也可以减少。Intel曾经做过一个统计,如果对全部的包内容使用cache,对于256字节(控制包)和1518字节(大包),分别可以减少40-50%的带宽。如下图:

当然,由于芯片缓存大小和配置的不同,其他的芯片肯定会有不同结果。
包转发只是测试项中比较重要的一条。在加入加解密,压缩,关键字检测,各种查表等等操作后,整个转发延迟会增加至几千甚至上万时钟周期。这时候,硬件加速器的好处就显现出来了。也就是说,如果一个包进来按部就班的走完所有的加速器步骤,那能效比和性能面积比自然是加速器高。但是,通常情况下,很多功能都是用不到的,而这些不常用功能模块,自然也就是面积和成本。
整理完基本数据通路,我们来看看完整的网络加速器有哪些任务。以下是标准的Ingress通路上的处理流程:

主要是收包,分配和管理缓冲,数据搬移,字段检测和分类,队列管理和分发。
Egress通路上的处理流程如下:

主要是队列管理和分发,限速,分配和管理缓冲,数据搬移。
在Ingress和Egress共有的部分中,最复杂的模块是缓冲管理和队列管理,它们的任务分别如下:
缓冲管理:缓冲池的分配和释放;描述符的添加和删除;资源统计与报警;
队列管理:维护MAC到CPU的队列重映射表,入队和出队管理;包的保序和QoS;CPU缓存的预热,对齐;根据预设的分流策略,均衡每个CPU的负载
这些任务大部分都不是纯计算任务,而是一个硬件化的内存管理和队列管理。事实上,在新的网络加速器设计中,这些所谓的硬件化的部分,是由一系列专用小核加C代码完成的。因此,完全可以再进一步,去掉网络加速器,使用SMP的多组通用处理器来做纯软件的队列和缓冲管理,只保留存在大量计算或者简单操作的硬件模块挂在总线上。
再来看下之前的芯片模块,我们保留加解密和压缩引擎,去除队列和缓存管理QB-Man,把WRIOP换成A53甚至更低端的小核,关键字功能检测可以用小核来实现。
网络处理上还有一些小的技术,如下:
Scattter Gather:前文提过,这可以处理分散的包头和负载,直接把多块数据DMA到最终的目的地,CPU不用参与拷贝操作。这个在以太网控制器里可以轻易实现。
Checksum:用集成在以太网控制器里面的小模块对数据包进行校验和编码,每个包都需要做一次,可以用很小的代价来替代CPU的工作。
Interrupt aggregation:通过合并多个包的中断请求来降低中断响应的平均开销。在Linux和一些操作系统里面,响应中断和上下文切换需要毫秒级的时间,过多的中断导致真正处理包的时间变少。这个在以太网控制器里可以轻易实现。
Rate limiter:包发送限速,防止某个MAC口发送速度超过限速。这个用软件做比较难做的精确,而以太网控制器可以轻易计算单位时间内的发送字节数,容易实现。
Load balancing, Qos:之前主要是在阐述如何对单个包进行处理。对于多个包,由于网络包之间天然无依赖关系,所以很容易通过负载均衡把他们分发到各个处理器。那到底这个分发谁来做?专门分配一个核用软件做当然是可以的,还可以支持灵活的分发策略。但是这样一来,可能会需要额外的拷贝,Cache stashing所减少的延迟优势也会消失。另外一个方法是在每一个以太网控制器里设置简单的队列(带优先级的多个Ring buffer之类的设计),和CPU号,线程ID或者虚拟机ID绑定。以太网控制器在对包头里的目的地址或者源地址做简单判断后,可以直接塞到相应的缓存或者DDR地址,供各个CPU来读取。如果有多个以太网控制器也没关系,每一个控制器针对每个CPU都可以配置不同的地址,让CPU上的软件来决定自己所属队列的读取策略,避免固化。
把这个技术用到PCIe的接口和网卡上,加入虚拟机ID的支持,就成了srIOV。PCIe控制器直接把以太网数据DMA到虚拟机所能看到的地址(同时也可使用Cache stashing),不引起异常,提高效率。这需要虚拟机中所谓的穿透模式支持IO(或者说外设)的虚拟化,在安全篇中有过介绍,此处就不再展开。同样的,SoC内嵌的以太网处理器,在增加了系统MMU之后,同样也可以省略PCIe的接口,实现虚拟化,直接和虚拟机做数据高效传输。
解决了负载均衡的问题,接下去就要看怎么做包的处理了。有几种经典的方法:
第一是按照包来分,在一个核上做完某一特征数据包流所有的任务,然后发包。好处是包的数据就在本地缓存,坏处是如果所有代码都跑在一个核,所用到的参数可能过多,还是需要到DDR或者系统缓存去取;也有可能代码分支过多,CPU里面的分支预测缓冲不够大,包处理程序再次回到某处代码时,还是会产生预测失败。
第二是按照任务的不同阶段来分,每个核做一部分任务,所有的包都流过每一个核。优缺点和上一条相反。
第三种就是前两者的混合,每一组核处理一个特定的数据流,组里再按照流水分阶段处理。这样可以根据业务代码来决定灵活性。
在以上的包处理程序中,一定会有一些操作是需要跨核的,比如对路由表的操作,统计数据的更新等。其中的一个重要原则就是:能不用锁就不要用锁,用了锁也需要使用效率最高的。
举个例子,如果需要实现一个计数器,统计N个CPU上最终处理过的包。首先,我们可以设计一个缓存行对齐的数据结构,包含若N+1个计数器,其中每一个计数器占据一行。每个CPU周期性的写入自己对应的那个计数器。由于计数器占据不同缓存行,所以写入操作不会引起额外的Invalidation,也不会把更新过的数据踢到DDR。最后,有一个独立的线程,不断读取前面N个计数器的值,累加到第N+1个计数器。在读取的时候,不会引起Invalidation和eviction。此处不需要软件锁来防止多个线程对同一变量的操作,因为此处计数器的写和读并不需要严格的先后次序,只需要保证硬件一致性即可。
在不得不使用锁的时候,也要保证它的效率。软件上的各种实现这里就不讨论了,在硬件上,Cacheable的锁变量及其操作最终会体现为两种形式:
第一, exclusive Access。原理是,对于一个缓存行里的变量,如果需要更新,必须先读然后写。当进行了一次读之后,进入锁定状态。期间如果有别的CPU对这个变量进行访问,锁定状态就会被取消,软件必须重复第一步;如果没有,就成功写入。这个原理被用来实现spinlock函数。根据硬件一致性协议MESI,处在两个CPU中的线程,同时对某一个变量读写的话,数据会不断在各自的私有缓存或者共享缓存中来回传递,而不会保持在最快的一级缓存。这样显然降低效率。多个CPU组之间的exclusive Access效率更低。
第二, 原子操作。在ARMv8.2新的原子操作实现上,修改锁变量的操作可以在缓存控制器上实现,不需要送到CPU流水线。这个缓存可以使私有缓存,也可以是共享的系统缓存。和exclusive access相比较,省去了锁定状态失败后额外的轮询。不过这个需要系统总线和CPU的缓存支持本地更新操作,不然还是要反复读到每个CPU的流水线上才能更新数据。我在基础篇中举过例子,这种做法反而可能引起总线挂起,降低系统效率。
如果一定要跑Linux系统,那么一定要减少中断,内核切换,线程切换的时间。对应的,可以采用轮询,线程绑定CPU和用户态驱动来实现。此外,还可以采用大页表模式,减少页缺失的时间。这样,可以把标准Linux内核协议栈的2000左右时钟周期缩到几十纳秒,这也就是DPDK和商业网络转发软件效率高的原因。
最后稍稍谈下固态存储。企业级的固态硬盘存储芯片,芯片基本结构如下:
如上图,芯片分为前端和后端两块,前端处理来自PCIe的命令和数据,并把数据块映射到最终nand颗粒。同时,还要做负载均衡,磨损均衡,垃圾回收,阵列控制等工作,略过不表。这些都是可以用通用处理器来完成的,差不多每1M的随机IOPS需要8个跑在1GHz左右的A7处理器来支撑,每TB的NAND阵列,差不多需要1GB的DDR内存来存放映射表等信息。其余的一些压缩,加解密等,可以通过专用模块完成。后端要是作为ONFI的接口控制器,真正的从NAND里面读写数据,同时做LDPC生成和校验。
如果单看前端,会发现其实和网络处理非常像,查表,转发,负载均衡,都能找到对应的功能。不同的是,存储的应用非常固定,不需要错综复杂的业务流程,只需处理几种类型的命令和数据块就可以了。
一个存储系统的硬件成本,闪存才是大头,占据了85%以上,还经常缺货。而闪存系统的毛利并不高,这也导致了固态存储控制器价格有限,哪怕是企业级的芯片,性能超出消费类几十倍,也无法像服务器那样拥有高利润。
一个潜在的解决方法,是把网络也集成到存储芯片中,并且跑Linux。这样,固态硬盘由原来插在x86服务器上的一个PCIe设备,摇身一变成为一个网络节点,从而省掉了原来的服务器芯片及其内存(可别小看内存,它在一台服务器里面可以占到三分之一的成本)。
如上图,可以把SPDK,DPDK,用户态驱动和用户态文件系统运行在一个芯片中,让一个网络包进来,不走内核网络协议栈和文件系统,直接从网络数据变成闪存上的文件块。在上层,运行类似CEPH之类的软件,把芯片实例化成一个网络存储节点。大致估算一下,这样的单芯片方案需要16核A53级别的处理器,运行在1.5GHz以下,在28纳米上,可以做到5-10瓦,远低于原来的服务器。
不过这个模式目前也存在着很大的问题。真正做存储芯片的公司,并不敢花大力气去推这种方案,因为它牵涉到了存储系统的基础架构变化,超出芯片公司的能力范畴,也不敢冒险去做这些改动。只有OEM和拥有大量数据中心互联网公司才能去定义,不过却苦于没有合适的单芯片方案。而且数据中心未必看得上省这点成本,毕竟成本大头在服务器芯片,内存以及机架电源。
-
处理器
+关注
关注
68文章
19461浏览量
231426 -
网络处理器
+关注
关注
0文章
48浏览量
14043
发布评论请先 登录
相关推荐
NanoEdge AI的技术原理、应用场景及优势
浅谈国产异构双核RISC-V+FPGA处理器AG32VF407的优势和应用场景
频率计数器的技术原理和应用场景
倍频器的技术原理和应用场景
时域网络分析仪的原理和应用场景
微波网络分析仪的原理和应用场景
数据网络分析仪的原理和应用场景
消息队列的应用场景
网络处理器中处理单元的设计

基于RISC-V指令集Egret系列处理器的性能及应用场景
网络音频模块有哪些应用场景?

盛显科技:投影融合处理器主要的应用场景有哪些?






 工商网监
工商网监
评论