 Jetson Nano让AI计算无处不在
Jetson Nano让AI计算无处不在
NVIDIA在GTC 2019上发布了Jetson Nano开发套件,这是一款售价99美元的计算机,可供嵌入式设计人员、研究人员和DIY创客们使用,在紧凑、易用的平台上即可实现现代AI的强大功能,并具有完整的软件可编程性。本文将为您详细剖析Jetson Nano的强大性能和应用。
Jetson Nano采用四核64位ARM CPU和128核集成NVIDIA GPU,可提供472 GFLOPS的计算性能。它还包括4GB LPDDR4存储器,采用高效、低功耗封装,具有5W/10W功率模式和5V DC输入,如图1所示。
图1. Jetson Nano开发套件 (80x100mm), 99美元即可获得
Jetson Nano基于配备了图形加速的Ubuntu18.04操作系统,全新发布的JetPack 4.2 SDK为其提供了完整的桌面Linux环境支持,NVIDIA CUDA 工具包10.0,以及cuDNN 7.3和TensorRT等库。该SDK还包括本机安装的常用开源机器学习(ML)框架,如TensorFlow、PyTorch、Caffe、Keras和MXNet,以及计算机视觉和机器人开发的框架,如OpenCV和ROS。
它与这些框架和NVIDIA领先的AI平台完全兼容,可以轻松地将基于AI的推理工作负载部署到Jetson。Jetson Nano能为各种复杂的深度神经网络(DNN)模型提供实时计算机视觉和推理。这些功能支持多传感器自主机器人,以及具有智能边缘分析的物联网设备和先进的AI系统。开发人员甚至可以通过迁移学习,使用机器学习框架在Jetson Nano本地重新训练网络。
Jetson Nano开发套件的体积仅为80x100mm,具有四个高速USB 3.0端口、MIPI CSI-2摄像头连接器、HDMI 2.0和DisplayPort 1.3、千兆以太网、M.2 Key-E模块、MicroSD卡插槽和40引脚GPIO接头。端口和GPIO接头开箱即用,配备各种常用的外围设备、传感器和即用型项目,例如NVIDIA在GitHub上开源的3D可打印深度学习JetBot。
该开发套件可由移动的MicroSD卡启动,能够在任何具有SD卡适配器的PC上进行格式化和成像。它可以通过Micro USB端口或5V DC桶形插孔适配器充电,方便快捷。摄像头连接器兼容经济实惠的MIPI CSI传感器,包括基于Jetson生态系统合作伙伴提供的8MP IMX219的模块。它还支持Raspberry Pi Camera Module v2,其中包括JetPack中的驱动程序支持。表1展现了其关键规格。
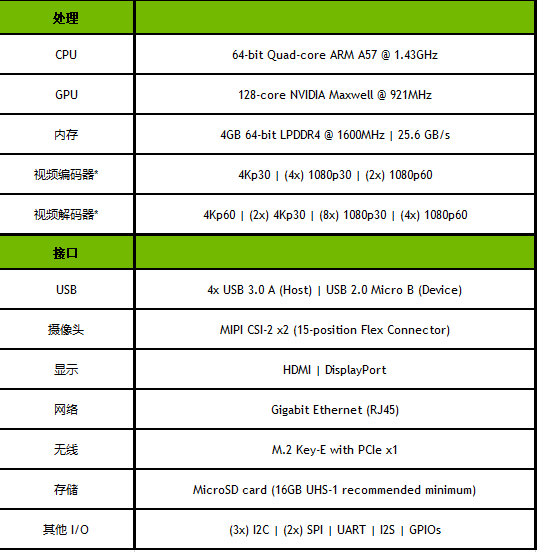
表1. Jetson Nano开发套件技术规格
*表示了达到聚合吞吐量的最大并发流数。支持的视频编解码器:H.265,H.264,VP8,VP9(仅限VP9解码)
该套件围绕一个260引脚的SODIMM型系统级模块(SoM)构建,如图2所示。SoM包含处理器、内存和电源管理电路。 Jetson Nano计算模块尺寸为45x70mm,将于2019年6月开始发售,售价129美元(千片批量),供嵌入式设计人员集成到生产系统中。生产计算模块将包括16GB eMMC板载存储和增强I/O,以及PCIe Gen2 x4/x2/x1、MIPI DSI,附加GPIO和12个MIPI CSI-2通道,可连接多达三个x4摄像头或最多四个摄像头x4/x2配置中。Jetson的统一内存子系统在CPU、GPU和多媒体引擎之间共享,提供简化的ZeroCopy传感器摄取和高效处理流水线。
图2. 45x70mm Jetson Nano 计算模块配备260引脚边缘连接器
深度学习推理基准
Jetson Nano可以运行各种各样的高级网络,包括流行的机器学习框架的完整原生版本,如TensorFlow、PyTorch、Caffe / Caffe2、Keras和MXNet等。通过实现图像识别、对象检测和定位、姿势估计、语义分割、视频增强和智能分析等强大功能,这些网络可用于构建自主机器和复杂AI系统。
图3显示了在线提供的常用模型的推理基准测试结果。推理使用批量1和FP16精度,采用JetPack 4.2配备的NVIDIA TensorRT加速器库。Jetson Nano在许多场景中都具有实时性能,能够处理多个高清视频流。
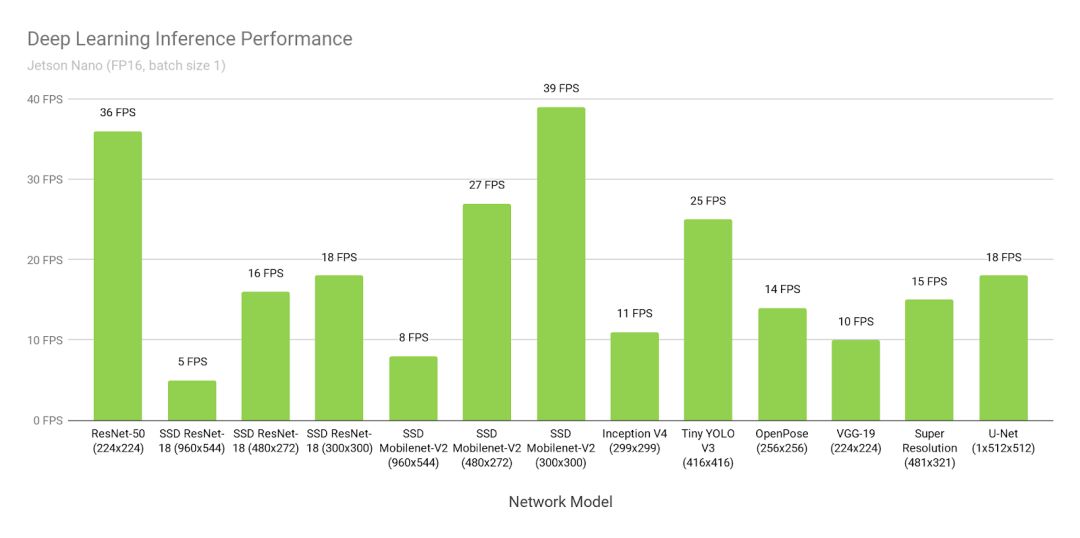
图3. 采用Jetson Nano和TensorRT的各种深度学习推理网络的性能,使用FP16精度和批量1
表2提供了完整的结果,包括其他平台的性能,如Raspberry Pi 3、Intel Neural Compute Stick 2和Google Edge TPU Coral Dev Board:
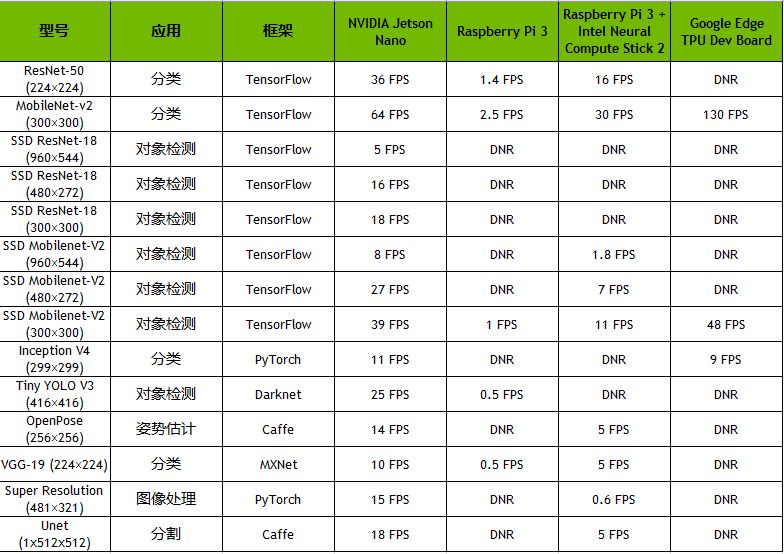
表2. Jetson Nano、Raspberry Pi 3、Intel Neural Compute Stick 2和Google Edge TPU Coral Dev Board的推理性能结果。
由于内存容量有限,网络层不受支持或硬件/软件限制,DNR(未运行)结果频繁发生。固定功能神经网络加速器通常支持相对较窄的一组用例,硬件支持专用层操作,需要网络权重和激活以适应有限的片上高速缓存,以避免重大的数据传输损失。它们可能会回退到主机CPU上以运行硬件中不支持的层,并且可能依赖于支持减少的框架子集的模型编译器(例如,TFLite)。
Jetson Nano灵活的软件和完整的框架支持,以及内存容量和统一内存子系统使其能够运行多种不同的网络,达到全高清分辨率,包括同时在多个传感器流上的可变批量大小。这些基准测试代表了常用网络的一些示例,但用户可以通过加速性能为Jetson Nano部署各种模型和定制架构。而Jetson Nano不仅限于DNN推理。其CUDA架构可用于计算机视觉和数字信号处理(DSP),使用包括FFT、BLAS和LAPACK操作在内的算法,以及用户定义的CUDA内核。
多流视频分析
Jetson Nano可实时处理多达8个高清全动态视频流,并可部署在网络视频录像机(NVR)、智能摄像头和物联网网关的低功耗边缘智能视频分析平台中。NVIDIA的DeepStream SDK使用ZeroCopy和TensorRT来优化端到端的推理管道,以在边缘和本地服务器上实现最佳性能。
如下视频显示了Jetson Nano在8个1080p30流上同时执行物体检测,该过程基于ResNet的模型以全分辨率运行,吞吐量为每秒500万像素(MP/s)。
图4显示了使用Jetson Nano通过深度学习分析在千兆以太网上摄取和处理多达8个数字流的示例NVR架构。该系统可解码500 MP/s的H.264/H.265,并编码250 MP/s的H.264/H.265视频。

图4. 使用Jetson Nano和8x高清摄像头输入的参考NVR系统架构
JetBot
图5所示的NVIDIA JetBot是一个新的开源自主机器人套件,它提供了所有软件和硬件,计划以低于250美元的价格构建一个人工智能的深度学习机器人。硬件材料包括Jetson Nano、IMX219 800万像素摄像头、3D打印机箱、电池组、电机、I2C电机驱动器和配件。
图5. NVIDIAJetBot是基于Jetson Nano的开源深度学习自主机器人套件,能够以低于$250的价格构建而成
该项目通过Jupyter笔记本提供简单易学的示例,介绍通过编写Python代码来控制电机,训练JetBot检测障碍物,跟踪人和家居用品等物体,并训练JetBot跟踪地板周围的路径。可以通过扩展代码和使用AI框架为JetBot创建新功能。还有可用于JetBot的ROS节点,为希望集成基于ROS的应用程序,以及SLAM和高级路径规划等功能的用户提供ROS Melodic支持。包含JetBot ROS节点的GitHub存储库还包括Gazebo 3D机器人模拟器的模型,在部署到机器人之前可在虚拟环境中开发和测试新的AI行为。 Gazebo模拟器生成合成摄像头数据,并在Jetson Nano上运行。
Hello AI World
Hello AI World提供了一个很好的方式来开始使用Jetson并体验AI的强大功能。在短短几个小时内,您就可以使用JetPack SDK和NVIDIA TensorRT在Jetson Nano开发套件上进行一系列深度学习推理演示,并进行实时图像分类和对象检测(使用预训练模型)。本教程重点介绍与计算机视觉相关的网络,并包括使用实时摄像头。您还可以使用C++编写自己易于理解的识别程序。可用的深度学习ROS节点将这些识别、检测和分段推理功能与ROS结合在一起,可以集成到先进的机器人系统和平台中。这些实时推理节点可以轻松地放入现有的ROS应用程序中。图6展示了其中一些示例。
想要尝试训练自己模型的开发人员可以参照完整的“Two Days to a Demo”教程,该教程涵盖了图像分类、对象检测和带有迁移学习的语义分割模型的重新训练和定制。迁移学习可以精确调整特定数据集的模型权重,并避免必须从头开始训练模型。迁移学习能够在连接NVIDIA离散GPU的PC或云实例上高效执行,因为训练需要比推理更多的计算资源和时间。
图6. Hello AI World和Two Days to a Demo教程帮助用户快速部署用于计算机视觉的深度学习
然而,由于Jetson Nano可以运行TensorFlow、PyTorch和Caffe等完整的训练框架,因此它还能够为那些无法访问另一台专用训练机器,并且愿意为获得结果而等待的人提供迁移学习。表3显示了Two Days to a Demo教程的迁移学习的初步结果,该过程在Jetson Nano上使用PyTorch,在20万图像、22.5GB的 ImageNet子集上训练Alexnet和ResNet-18:
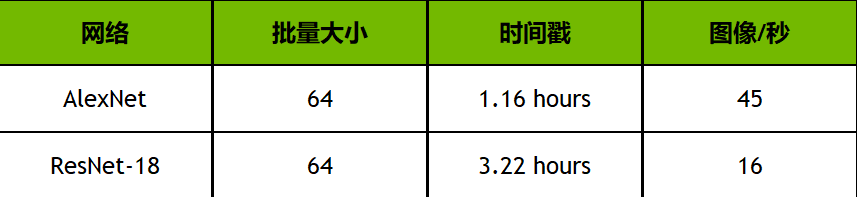
表3. 使用Jetson Nano和迁移学习在ImageNet数据集的样本——20万图像/22.5GB子集上重新训练图像分类网络的结果
时间戳指的是完成20万图像训练数据集所需的时间。对于可用结果和生产模型,分类网络可能需要2-5个时间戳,并且应该在离散GPU系统上训练以获得更多时间戳,直到它们达到最大准确度。但是,Jetson Nano可以让网络在一夜之间重新训练,在低成本平台上体验深度学习和人工智能。并非所有自定义数据集都与此处使用的22.5GB示例一样大。因此,图像/秒表示Jetson Nano的训练性能,此处还包括时间戳缩放与数据集的大小,训练批量大小和网络复杂性。其他型号也可以在Jetson Nano上重新训练,同时增加训练时间。
所有人可用的AI
Jetson Nano的计算性能、紧凑的体积和灵活性为开发人员带来了创建AI驱动设备和嵌入式系统的无限可能性。
-
英伟达
+关注
关注
22文章
3744浏览量
90831
原文标题:深度剖析 | Jetson Nano让AI计算无处不在
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
万物智联时代,OpenHarmony何以「无处不在」?

Arm如何赋能无处不在的AI
人工智能技术跃进:英特尔引领AI无处不在新纪元
使用myAGV、Jetson Nano主板和3D摄像头,实现了RTAB-Map的三维建图功能!

让智能计算无处不在,高通ChinaJoy AIGC大会展望终端侧AI行业赋能

“从无处不在到无人不用”,大模型推动边缘计算变革的机遇与挑战

英特尔帕特·基辛格:让AI无处不在
高通亮相MWC 2024:AI+连接助力创新与协作,让智能计算无处不在
高通持续推动终端侧生成式AI变革,推出高通AI Hub赋能开发者
2024年CES科技展:AI无处不在?

第五代英特尔至强可扩展处理器 AI 性能大幅提升,英特尔加注推动人工智能无处不在
AI 无处不在,英特尔酷睿Ultra 和第五代英特尔至强可扩展处理器正式发布






 工商网监
工商网监
评论