 PyTorch核心华人开发者透彻解读PyTorch内部机制
PyTorch核心华人开发者透彻解读PyTorch内部机制
本文以内部PyTorch核心开发者视角,非常详细透彻的分析了PyTorch的内部结构,为开发者提供一张地图,告诉您“支持自动区分的张量库”的基本概念结构,并提供一些工具和技巧,以便找到适合代码库。对学习PyTorch、尤其是致力于参与PyTorch贡献有非常大的意义。
PyTorch是一个开源的Python机器学习库,基于Torch,已成为最受欢迎的机器学习框架之一。
相比Tensorflow,PyTorch的社区由更多专业机器学习开发人员、软件架构师和公司内部程序员组成。
PyTorch也更多地用于数据分析和业务环境中的特殊模型中。
在PyTorch社区中,有更多的Python开发人员从事Web应用程序。此外,这种Python向框架的多功能性,使得研究人员能够以几乎无痛的方式测试想法,使得它成为最先进的尖端解决方案的首选框架。
对于准备、正在学习PyTorch的读者来说,了解其内部机制能够极大的提升学习效率、增进对PyTorch设计原理和目的的了解,从而能够更好的在工作学习中使用该工具。如果你立志参与到PyTorch后续的改进中,那么更应该深入的了解其内部机制。
好消息是,Facebook Research Engineer、斯坦福博士生、PyTorch核心开发人员Edward Z. Yang为大家带来一份PyTorch内部机制的详解slides,新智元在此强力推荐给广大读者。正文约3500字,阅读可能需要10分钟。
由于微信的限制无法展示高清图像,我们特意为大家在文末找来了可下载的高清完整版,预祝大家学习愉快!
这份内部机制详解是为谁准备的?
主要针对使用过PyTorch的人,尤其是希望成为PyTorch贡献者、但却被PyTorch的庞大复杂的C++代码库吓到的人。
最终目的是能够为大家提供一个通关宝典,让大家了解“支持自动区分的Tensor库”的基本概念结构,并提供一些工具和技巧,用来更容易的找到适合代码库。
读者只需要对PyTorch有一个初步的了解,并且有过一定的动手经验即可。门槛还是非常低的。
全部内容分为两部分。首先介绍Tensor库的概念。作者将从Tensor数据类型开始,更详细地讨论这种数据类型提供的内容,以便让读者更好地了解它是如何实际实现的。布局、设备和dtype的三位一体,探讨如何考虑对Tensor类的扩展。
第二部分将讨论PyTorch实战。例如使用autograd来降低工作量,哪些代码关键、为什么?以及各种用来编写内核的超酷的工具。
理解Tensor库的概念
Tensor
Tensor是PyTorch中的中心数据结构。我们可以将Tensor视为由一些数据组成,然后是一些描述Tensor大小的元数据,包含元素的类型(dtype),Tensor所依赖的设备(CPU内存?CUDA内存?)。以及Strides(步幅)。Strides实际上是PyTorch的一个显著特征。
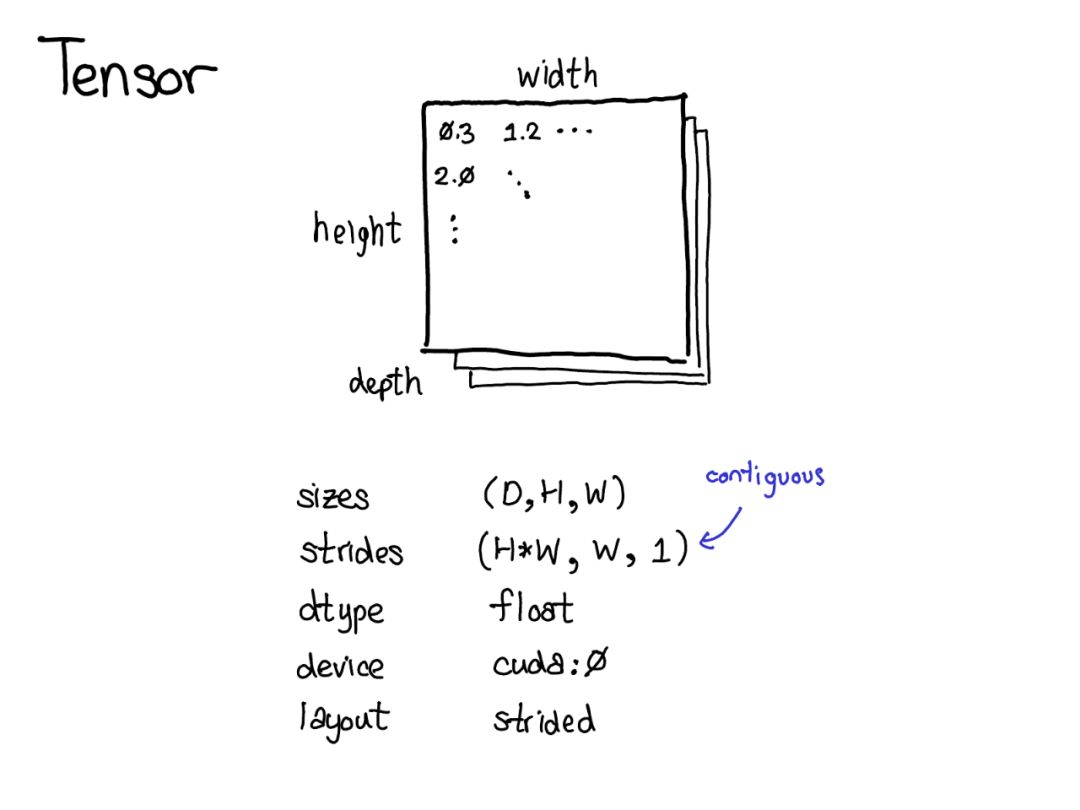
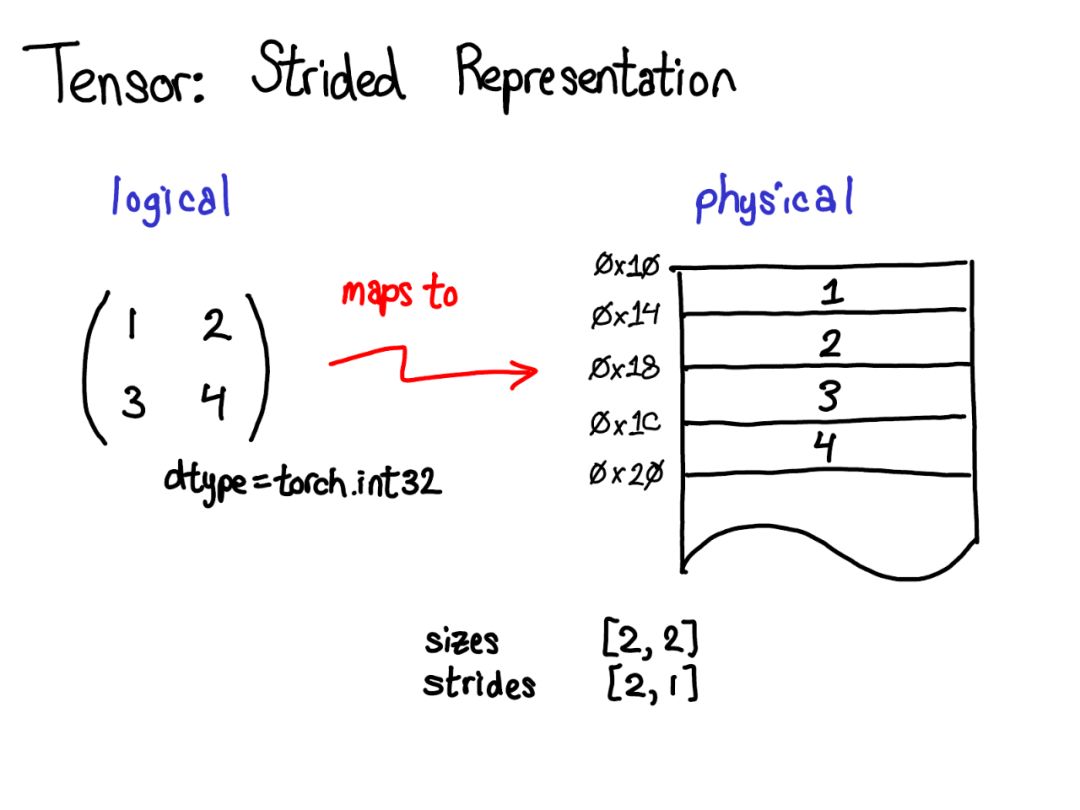
Tensor是一个数学概念。在计算机上最常见的表示是将Tensor中的每个元素连续地存储在内存中,将每一行写入内存,如上所示。
在上面的例子中,指定Tensor包含32位整数,每个整数位于物理地址中,相互偏移四个字节。要记住Tensor的实际尺寸,还必须记录哪些尺寸是多余的元数据。
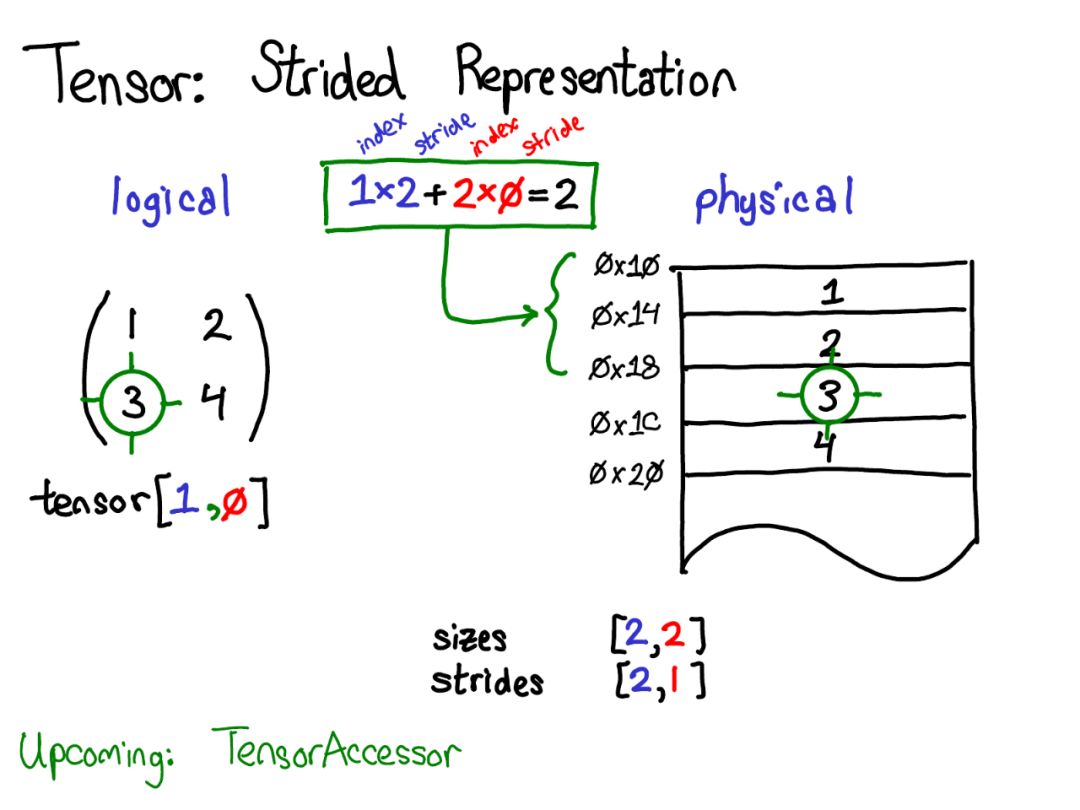
假设我想在逻辑表示中访问位置Tensor[0,1]处的元素。通过Stride我们应该这样做:
找出Tensor的任何元素存在的位置,将每个索引乘以该维度的相应Stride,并将它们加在一起。
上图中将第一维蓝色和第二维红色进行了颜色编码,以便在Stride计算中跟踪索引和步幅。
以上是Stride的一个例子。Stride表示实际上可以让你代表Tensor的各种有趣的方法; 如果你想玩弄各种可能性,请查看Stride Visualizer。
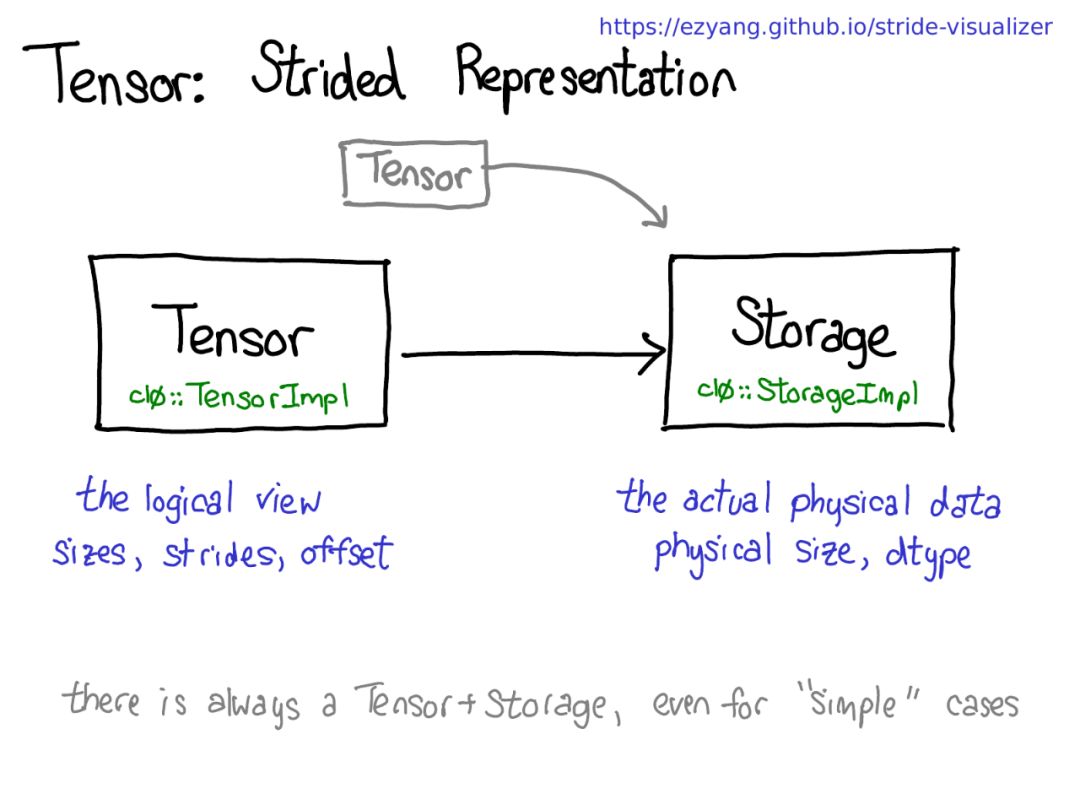
可能存在共享相同存储的多个Tensor,但请记住一点:有Tensor的地方,就有存储。
存储定义Tensor的dtype和物理大小,而每个Tensor记录大小,步幅和偏移,定义物理内存的逻辑解释。
Tensor扩展
有很多有趣的扩展,如XLA张量,量化张量,或MKL-DNN张量,作为张量库,我们必须考虑是如何适应这些扩展。
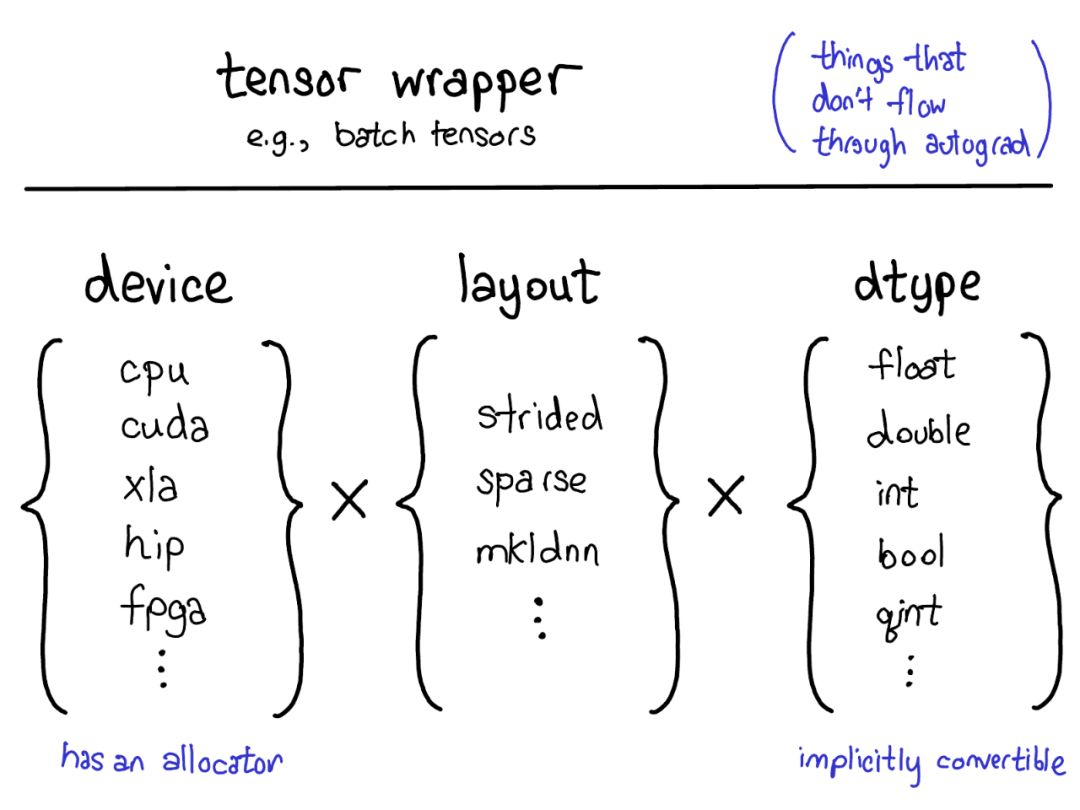
当前的扩展模型在张量上提供了四个扩展点。首先,用三个参数用来确定张量是什么:
设备
张量的物理存储器实际存储在何处,例如在CPU上,NVIDIA GPU(cuda)上,或者可能在AMD GPU(hip)或TPU(xla)上的描述。设备的显着特征是它有自己的分配器,不能与任何其他设备一起使用。
布局
布局用来描述我们如何逻辑地解释这个物理内存。最常见的布局是跨步张量,但稀疏张量具有不同的布局,涉及2个张量:一个用于索引、一个用于数据。
MKL-DNN张量可能具有更奇特的布局,例如阻挡布局,这不能仅使用步幅来表示。
dtype
描述了它实际存储在张量的每个元素中的含义。这可以是浮点数或整数,或者它可以是例如量化的整数。
顺便说一下,如果你想为PyTorch张量添加一个扩展名,请联系PyTorch官方。
实战技巧
了解你手里的武器
PyTorch有很多文件夹,CONTRIBUTING文档有非常详细的描述。但实际上,你真正需要了解的只有四个:
torch/:包含导入和使用的实际Python模块。Python代码,很容易上手调试。
torch/csrc/:它实现了在Python和C++之间进行转换的绑定代码,以及一些非常重要的PyTorch功能,如autograd引擎和JIT编译器。它还包含C++前台代码。
aten/:“A Tensor Library”的缩写(由Zachary DeVito创造),是一个实现Tensors操作的C++库。存放一些内核代码存在的地方,尽量不要在那里花太多时间。
c10/:这是一个双关语。C代表Caffe,10既是二级制的2,也是十进制的10(英文Ten,同时也是Tensor的前半部分)。包含PyTorch的核心抽象,包括Tensor和Storage数据结构的实际实现。
让我们看看这种代码分离在实践中是如何分解的:

调用一个函数的时候,会经历以下步骤:
将Python翻译成C
处理变量调度
处理设备类型/布局调度
我们有实际的内核,它既可以是现代本机函数,也可以是传统的TH函数

值得一提的是,所有代码都是自动生成的,所以不会出现在GitHub的repo里,必须自己构建PyTorch后才能看到。不过你也不必非常深刻地理解这段代码在做什么,自动生成的嘛。
从武器库中挑选写内核的趁手兵刃
PyTorch为内核编写者提供了许多有用的工具。在本节中,我们将介绍其中比较趁手的工具。
要利用PyTorch带来的所有代码生成,需要为运算符编写schema。详细介绍参见GitHub的README。

错误检查可以通过低阶API(TORCH_CHECK)和高阶API实现。高阶API可以基于TensorArg元数据提供用户友好的错误消息。
要执行dtype调度,应该使用AT_DISPATCH_ALL_TYPES宏,用来获取张量的dtype,并用于可从宏调度的每个dtype的lambda。通常,这个lambda只调用一个模板化的辅助函数。

如何提高工作效率

别编辑header!
编辑header会导致很长的重构时间,尽量去编辑.cpp文件。
别直接用CI去测试
CI是一个直接可用的测试代码的变动是否有效的非常棒的工具,但如果你真的一点不都改设置恐怕要浪费很长时间在测试过程中。
强烈建议设置ccache
它有可能让你避免在编辑header时进行大量重新编译。而当我们在不需要重新编译文件时进行了重新编译,它还有助于掩盖构建系统中的错误。
用一台高性能的工作站
-
存储器
+关注
关注
38文章
7621浏览量
166122 -
机器学习
+关注
关注
66文章
8482浏览量
133939 -
pytorch
+关注
关注
2文章
809浏览量
13720
原文标题:揭秘PyTorch内核!核心开发者亲自全景解读(47页PPT)
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Pytorch模型训练实用PDF教程【中文】
Facebook致力AI开源PyTorch 1.0 AI框架
Facebook致力AI 开源PyTorch1.0 AI框架
Facebook宣布发布深度学习框架 PyTorch 1.0开发者预览版
一文解构PyTorch:深入了解PyTorch内部机制

一篇非常新的介绍PyTorch内部机制的文章

PyTorch 的 Autograd 机制和使用
TensorFlow的衰落与PyTorch的崛起

没有“中间商赚差价”, OpenVINO™ 直接支持 PyTorch 模型对象

15-PyTorch-Edge-在边缘设备上部署AI模型的开发者之旅
解读PyTorch模型训练过程
PyTorch的介绍与使用案例
PyTorch深度学习开发环境搭建指南
有几种电平转换电路,适用于不同的场景
一.起因一般在消费电路的元器件之间,不同的器件IO的电压是不同的,常规的有5V,3.3V,1.8V等。当器件的IO电压一样的时候,比如都是5V,都是3.3V,那么其之间可以直接通讯,比如拉中断,I2Cdata/clk脚双方直接通讯等。当器件的IO电压不一样的时候,就需要进行电平转换,不然无法实现高低电平的变化。二.电平转换电路常见的有几种电平转换电路,适用于

瑞萨RA8系列教程 | 基于 RASC 生成 Keil 工程
对于不习惯用 e2 studio 进行开发的同学,可以借助 RASC 生成 Keil 工程,然后在 Keil 环境下愉快的完成开发任务。

共赴之约 | 第二十七届中国北京国际科技产业博览会圆满落幕
作为第二十七届北京科博会的参展方,芯佰微有幸与800余家全球科技同仁共赴「科技引领创享未来」之约!文章来源:北京贸促5月11日下午,第二十七届中国北京国际科技产业博览会圆满落幕。本届北京科博会主题为“科技引领创享未来”,由北京市人民政府主办,北京市贸促会,北京市科委、中关村管委会,北京市经济和信息化局,北京市知识产权局和北辰集团共同承办。5万平方米的展览云集

道生物联与巍泰技术联合发布 RTK 无线定位系统:TurMass™ 技术与厘米级高精度定位的深度融合
道生物联与巍泰技术联合推出全新一代 RTK 无线定位系统——WTS-100(V3.0 RTK)。该系统以巍泰技术自主研发的 RTK(实时动态载波相位差分)高精度定位技术为核心,深度融合道生物联国产新兴窄带高并发 TurMass™ 无线通信技术,为室外大规模定位场景提供厘米级高精度、广覆盖、高并发、低功耗、低成本的一站式解决方案,助力行业智能化升级。

智能家居中的清凉“智”选,310V无刷吊扇驱动方案--其利天下
炎炎夏日,如何营造出清凉、舒适且节能的室内环境成为了大众关注的焦点。吊扇作为一种经典的家用电器,以其大风量、长寿命、低能耗等优势,依然是众多家庭的首选。而随着智能控制技术与无刷电机技术的不断进步,吊扇正朝着智能化、高效化、低噪化的方向发展。那么接下来小编将结合目前市面上的指标,详细为大家讲解其利天下有限公司推出的无刷吊扇驱动方案。▲其利天下无刷吊扇驱动方案一
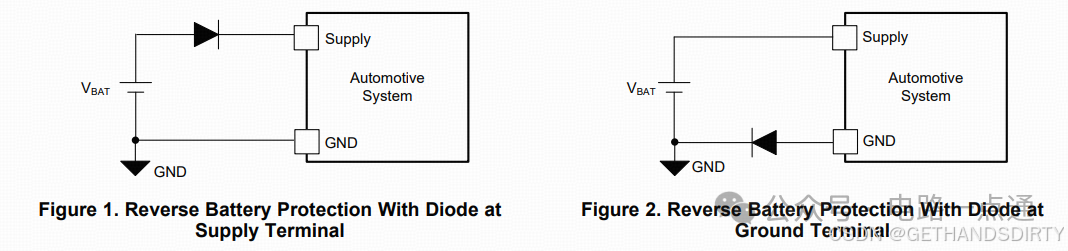
电源入口处防反接电路-汽车电子硬件电路设计
一、为什么要设计防反接电路电源入口处接线及线束制作一般人为操作,有正极和负极接反的可能性,可能会损坏电源和负载电路;汽车电子产品电性能测试标准ISO16750-2的4.7节包含了电压极性反接测试,汽车电子产品须通过该项测试。二、防反接电路设计1.基础版:二极管串联二极管是最简单的防反接电路,因为电源有电源路径(即正极)和返回路径(即负极,GND),那么用二极
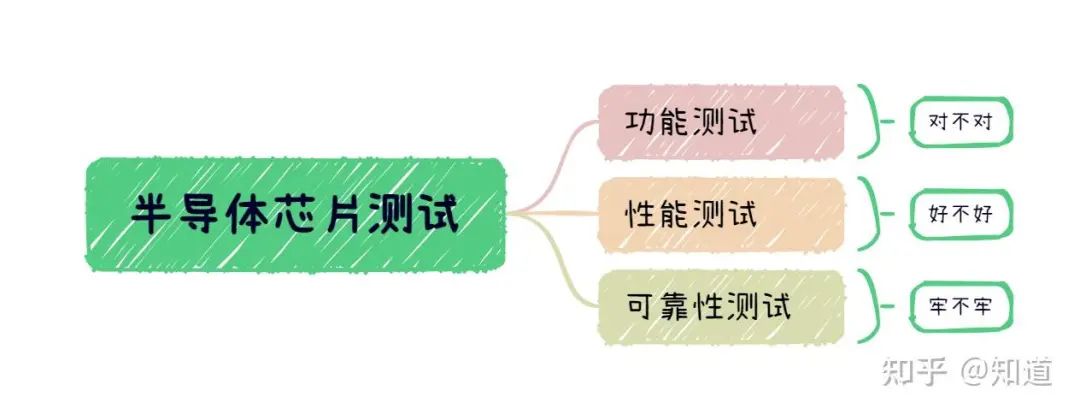
半导体芯片需要做哪些测试
首先我们需要了解芯片制造环节做⼀款芯片最基本的环节是设计->流片->封装->测试,芯片成本构成⼀般为人力成本20%,流片40%,封装35%,测试5%(对于先进工艺,流片成本可能超过60%)。测试其实是芯片各个环节中最“便宜”的一步,在这个每家公司都喊着“CostDown”的激烈市场中,人力成本逐年攀升,晶圆厂和封装厂都在乙方市场中“叱咤风云”,唯独只有测试显

解决方案 | 芯佰微赋能示波器:高速ADC、USB控制器和RS232芯片——高性能示波器的秘密武器!
示波器解决方案总述:示波器是电子技术领域中不可或缺的精密测量仪器,通过直观的波形显示,将电信号随时间的变化转化为可视化图形,使复杂的电子现象变得清晰易懂。无论是在科研探索、工业检测还是通信领域,示波器都发挥着不可替代的作用,帮助工程师和技术人员深入剖析电信号的细节,精准定位问题所在,为创新与发展提供坚实的技术支撑。一、技术瓶颈亟待突破性能指标受限:受模拟前端
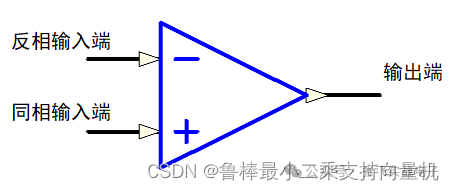
硬件设计基础----运算放大器
1什么是运算放大器运算放大器(运放)用于调节和放大模拟信号,运放是一个内含多级放大电路的集成器件,如图所示:左图为同相位,Vn端接地或稳定的电平,Vp端电平上升,则输出端Vo电平上升,Vp端电平下降,则输出端Vo电平下降;右图为反相位,Vp端接地或稳定的电平,Vn端电平上升,则输出端Vo电平下降,Vn端电平下降,则输出端Vo电平上升2运算放大器的性质理想运算

ElfBoard技术贴|如何调整eMMC存储分区
ELF 2开发板基于瑞芯微RK3588高性能处理器设计,拥有四核ARM Cortex-A76与四核ARM Cortex-A55的CPU架构,主频高达2.4GHz,内置6TOPS算力的NPU,这一设计让它能够轻松驾驭多种深度学习框架,高效处理各类复杂的AI任务。

米尔基于MYD-YG2LX系统启动时间优化应用笔记
1.概述MYD-YG2LX采用瑞萨RZ/G2L作为核心处理器,该处理器搭载双核Cortex-A55@1.2GHz+Cortex-M33@200MHz处理器,其内部集成高性能3D加速引擎Mail-G31GPU(500MHz)和视频处理单元(支持H.264硬件编解码),16位的DDR4-1600/DDR3L-1333内存控制器、千兆以太网控制器、USB、CAN、
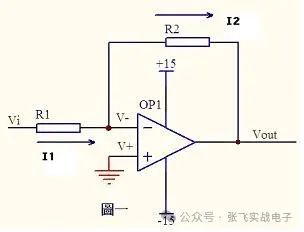
运放技术——基本电路分析
虚短和虚断的概念由于运放的电压放大倍数很大,一般通用型运算放大器的开环电压放大倍数都在80dB以上。而运放的输出电压是有限的,一般在10V~14V。因此运放的差模输入电压不足1mV,两输入端近似等电位,相当于“短路”。开环电压放大倍数越大,两输入端的电位越接近相等。“虚短”是指在分析运算放大器处于线性状态时,可把两输入端视为等电位,这一特性称为虚假短路,简称

飞凌嵌入式携手中移物联,谱写全国产化方案新生态
4月22日,飞凌嵌入式“2025嵌入式及边缘AI技术论坛”在深圳成功举办。中移物联网有限公司(以下简称“中移物联”)携OneOS操作系统与飞凌嵌入式共同推出的工业级核心板亮相会议展区,操作系统产品部高级专家严镭受邀作《OneOS工业操作系统——助力国产化智能制造》主题演讲。
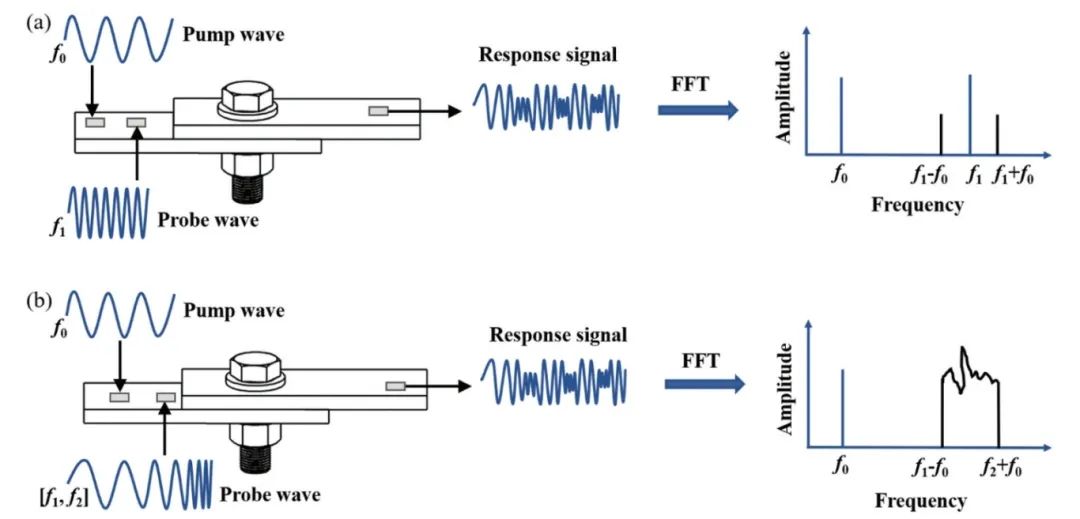
ATA-2022B高压放大器在螺栓松动检测中的应用
实验名称:ATA-2022B高压放大器在螺栓松动检测中的应用实验方向:超声检测实验设备:ATA-2022B高压放大器、函数信号发生器,压电陶瓷片,数据采集卡,示波器,PC等实验内容:本研究基于振动声调制的螺栓松动检测方法,其中低频泵浦波采用单频信号,而高频探测波采用扫频信号,利用泵浦波和探测波在接触面的振动声调制响应对螺栓的松动程度进行检测。通过螺栓松动检测
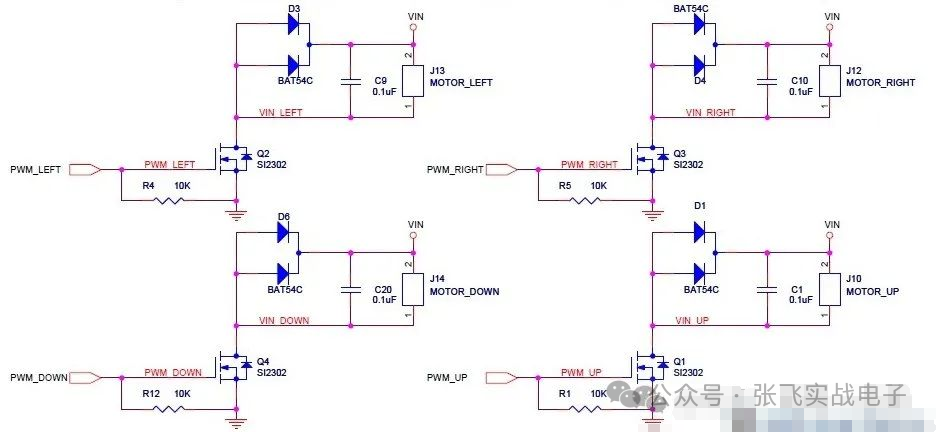
MOS管驱动电路——电机干扰与防护处理
此电路分主电路(完成功能)和保护功能电路。MOS管驱动相关知识:1、跟双极性晶体管相比,一般认为使MOS管导通不需要电流,只要GS电压(Vbe类似)高于一定的值,就可以了。MOS管和晶体管向比较c,b,e—–>d(漏),g(栅),s(源)。2、NMOS的特性,Vgs大于一定的值就会导通,适合用于源极接地时的情况(低端驱动),只要栅极电压达到4V或10V就可以





 工商网监
工商网监
评论