 Chip Huyen总结ICLR 2019年的8大趋势 RNN正在失去研究的光芒
Chip Huyen总结ICLR 2019年的8大趋势 RNN正在失去研究的光芒

ICLR 2019过去有几天了,作为今年上半年表现最为亮眼的人工智能顶会共收到1591篇论文,录取率为31.7%。
为期4天的会议,共有8个邀请演讲主题,内容包括:算法公平性的进展、对抗机器学习、发展自主学习:人工智能,认知科学和教育技术、用神经模型学习自然语言界面等等。
当然,除此之外,还有一大堆的poster。这些都彰显了ICLR的规格之高,研究者实力之强大。
透过现象看本质,一位来自越南的作家和计算机科学家Chip Huyen总结了ICLR 2019年的8大趋势。他表示。会议组织者越来越强调包容性,在学术研究方面RNN正在失去研究的光芒......
1.包容性。
组织者强调了包容性在人工智能中的重要性,确保前两次主要会谈的开幕词邀请讲话是关于公平和平等的。
但是还是有一些令人担忧的统计数据:
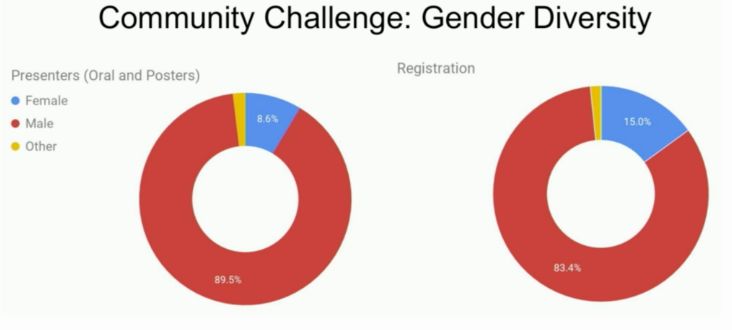
只有8.6%的演讲者和15%的参与者是女性。
在所有的LGBTQ+(Lesbian Gay Bisexual Transgender Queer:性别独角兽群体)研究人员中,有2/3的研究人员并不是专业的。
所有8位特邀演讲者都是白人。
不幸的是,这位AI研究人员仍然感到毫无歉意。虽然其他所有的研讨会的订阅量爆满,但在Yoshua Bengio出现之前,AI赋能社会(AI for Social Good)研讨会一直空无一人。在我在ICLR的众多谈话中,没有人提到过差异性,除了有一次我大力声讨地问为什么我被邀请参加这场似乎不适合我的技术活动?一位好朋友说:“有点冒犯的回答是,因为你是一个女人。”
原因之一是这个话题不是“技术性的”,因此在上面花时间将无助于你在研究领域的职业发展。另一个原因是仍然存在一些反对的偏见。有一次,一位朋友告诉我,不要理睬一位在群聊中嘲笑我的人,因为“那人喜欢取笑那些谈论平等和差异性的人。”我有一些朋友,他们不会在网上讨论任何关于差异性的话题,因为他们不想“与这种话题联系在一起”。
2.无监督表征学习与迁移学习
无监督表示学习的一个主要目标是从未标记的数据中发现有用的数据,以便用于后续任务。在自然语言处理中,无监督的表示学习通常是通过语言建模来完成的。然后将学习到的表示用于诸如情感分析、名字分类识别和机器翻译等任务。
去年发表的一些最令人兴奋的论文是关于自然语言处理中的无监督学习的,首先是ApacheElmo(Peters等人)、DB2ULMFiT(Howard等人)、ApacheOpenAI的GPT(Radford等人)、IBMBert(Devlin等人),当然还有,比较激进的202GPT-2(Radford等人)。
完整的GPT-2模型是在 ICLR演示的,它的表现非常好。您可以输入几乎任何提示,它将撰写文章的其余部分。它可以撰写BuzzFeed文章(美国新闻RSS订阅,类似于今日头条)、小说、科学研究论文,甚至是虚构单词的定义。但这听起来还不完全是人类的感觉。该团队正在研究GPT-3,会比现在更好。我迫不及待地想看看它能产生什么。
虽然计算机视觉社区是第一个将迁移学习用于工作的社区,但基础任务-在ImageNet上训练分类模型-仍然受到监督。我不断从两个社区的研究人员那里听到的一个问题是:“我们如何才能获得为图像工作的无监督学习?”
尽管大多数大牌研究实验室已经在进行这方面的研究,但在ICLR上只有一篇论文:“元学习无监督学习的更新规则”(Metz et al.)。他们的算法不升级权值,而是升级学习规则。
然后,在少量的标记样本上对从学习规则中学习到的表示进行调整,以完成图像分类任务。他们找到了学习规则,在MNIST和FashionMNIST数据集上达到了70%的准确率。作者不打算发布代码,因为“它与计算有关”。在256个GPU上,外层循环需要大约100k的训练步骤和200个小时。
我有一种感觉,在不久的将来,我们将看到更多这样的研究。可用于无监督学习的一些任务包括:自动编码、预测图像旋转(Gidaris等人的这篇论文是2018年ICLR的热门文章),预测视频中的下一帧。
3.机器学习的“复古”
机器学习中的思想就像时尚:它们绕着一个圈走。在海报展示会上走来走去,就像沿着记忆小路在漫步。即使是备受期待的ICLR辩论最终也是由先验与结构结束,这是对Yann LeCun和 Christopher Manning去年讨论的回溯,而且与贝叶斯主义者和频率论者之间的由来的辩论相似。
麻省理工学院媒体实验室的语言学习和理解项目于2001年终止,但基础语言学习今年卷土重来,两篇论文都是基于强化学习:
DOM-Q-Net:基于结构化语言(Jia等人)的RL-一种学习通过填充字段和单击链接导航Web的RL算法,给定一个用自然语言表示的目标。
BabyAI:一个研究扎根语言学习样本效率的平台(Chevalier-Boisveret等人)-这是一个与OpenAI训练兼容的平台,具有一个手动操作的BOT代理,它模拟人类教师来指导代理学习一种合成语言。
AnonReviewer4很好地总结了我对这两篇论文的看法:
“…这里提出的方法看起来非常类似于语义解析文献中,已经研究过一段时间的方法。然而,这篇论文只引用了最近深入的RL论文。我认为,让作者熟悉这些文学作品将会使他们受益匪浅。我认为语义解析社区也会从这个…中受益。但这两个社区似乎并不经常交谈,尽管在某些情况下,我们正在解决非常相似的问题。”
确定性有限自动机(DFA)也在今年的深度学习领域中占据了一席之地,它有两篇论文:
表示形式语言的:有限自动机(FA)与递归神经网络(RNN)的比较(Michalenko等人)。
学习递归策略网络的有限状态表示(Koulet等人)
这两篇论文背后的主要动机是,由于RNN中隐藏状态的空间是巨大的,是否有可能将状态数量减少到有限的状态?我猜测DFA是否能有效地代表语言的RNN,但我真的很喜欢在训练期间学习RNN,然后将其转换为DFA以供参考的想法,正如Koul等人的论文中所介绍的那样。最终的有限表示只需要3个离散的记忆状态和10场观察的乒乓球游戏。有限状态表示也有助于解释RNN。
4.RNN正在失去研究的光芒
2018年至2019年提交(论文)主题的相对变化表明,RNN的下降幅度最大。这并不奇怪,因为尽管RNN对于序列数据是直观的,但它们有一个巨大的缺点:它们不能被并行化,因此不能利用自2012年以来推动研究进展的最大因素:计算能力。RNN在CV或RL中从未流行过,而对于NLP,它们正被基于注意力的体系结构所取代。
这是不是意味着RNN已经over了?不一定。今年的两个最佳论文奖之一是“有序神经元:将树结构集成到递归神经网络中”。(Shen等人)。除了本文和上面提到的两篇关于自动机的文章之外,今年又有9篇关于RNN的论文被接受,其中大多数都深入研究了RNN的数学基础,而不是发现新的RNN应用方向。
RNN在行业中仍然非常活跃,特别是对于交易公司等处理时间序列数据的公司来说,不幸的是,这些公司通常不会发布它们的工作成果。即使RNN现在对研究人员没有吸引力,说不定它可能会在未来卷土重来。
5.GAN持续火热
尽管与去年相比GAN的相对增长略有下降, 但论文数量实际上从去年的约70篇涨到了今年的100多篇。Ian Goodfellow做了一个关于GAN的特邀报告,更是受其信徒大力推崇。以至于到了最后一天, 他不得不遮住胸前的徽章, 这样人们才不会因为看到他的名字而激动不已。
第一个海报展示环节全是关于GAN的最新进展,涵盖了全新的GAN架构、旧架构的改进、GAN分析、以及从图像生成到文本生成再到语音合成的GAN应用。
衍生出了PATE-GAN, GANSynth, ProbGAN, InstaGAN, RelGAN, MisGAN, SPIGAN, LayoutGAN, KnockoffGAN等等不同的GAN网络。总而言之,只要提到GAN我就好像变成了一个文盲,迷失在林林总总的GAN网络中。值得一提的是,Andrew Brock没有把他的大规模GAN模型叫做giGANtic让我好生失望。
GAN的海报展示环节也揭示了在GAN问题上,ICLR社区是多么的两极分化。我听到有些人小声嘟囔着“我已经等不及看到这些GAN的完蛋啦”,“只要有人提到对抗(adversarial)我的脑瓜仁就疼”。当然,据我分析,他们也可能只是嫉妒而已。
6.缺乏生物启发式深度学习
想想之前的舆论充斥着对基因测序和CRISPR 婴儿(基因编辑婴儿)的焦虑,而令我感到惊讶的是在ICLR上竟然没有几篇关于生物深度学习的论文。事实上,关于这一主题满打满算也就六篇:
两篇关于受生物启发的架构
一篇关于学习设计 RNA (Runge et al.)
三篇关于蛋白质操纵
关于基因组学的论文为零。也没有关于这一专题的研讨会。尽管这一现象令人遗憾, 但也为对生物学感兴趣的深度学习研究人员或对深度学习感兴趣的生物学家提供了巨大的机会。
7.强化学习仍旧是最受欢迎的主题。
会议上的报告表明,RL社区正在从model-free 方法向sample-efficient model-based和meta-learning算法转移。这种转变可能是受TD3和SAC在Mujoco平台的连续控制任务,以及R2D2在Atari离散控制任务上的极高得分所推动的。
基于模型的算法(即从数据中学习环境模型,并利用它规划或生成更多数据的算法)终于能逐渐达到其对应的无模型算法的性能,而且只需要原先十分之一至百分之一的经验。
这一优势使他们适合于实际任务。尽管学习得到的单一模拟器很可能存在缺陷,但可以通过更复杂的动力学模型,例如集成模拟器,来改善它的缺陷。
另一种将RL应用到实际问题的方法是允许模拟器支持任意复杂的随机化(arbitrarily complex randomizations):在一组不同的模拟环境上训练的策略可以将现实世界视为另一个随机化(randomization),并力求成功
元学习(Meta-learning)算法,可实现在多个任务之间的快速迁移学习,也已经在样本效率(smaple-efficiency)和性能方面取得了很大的进步(Promp(Rothfuss等人)
这些改进使我们更接近“the ImageNet moment of RL”,即我们可以复用从其他任务中学到的控制策略,而不是每个任务都从头开始学习。
大部分已被接受的论文,连同整个Structure and Priors in RL研讨会,都致力于将一些有关环境的知识整合到学习算法中。虽然早期的深度RL算法的主要优势之一是通用性(例如,DQN对所有Atari游戏都使用相同的体系结构,而无需知道某个特定的游戏),但新的算法表明,结合先验知识有助于完成更复杂的任务。例如,在Transporter Network(Jakab et al.)中,使用的先验知识进行更具信息量的结构性探索。
综上所述,在过去的5年中,RL社区开发了各种有效的工具来解决无模型配置下的RL问题。现在是时候提出更具样本效率(sample-efficient)和可迁移性(transferable)的算法来将RL应用于现实世界中的问题了。
趣闻轶事:Sergey Levine可能是这届ICLR发表论文最多的人了,一共15篇。。。
8.大部分论文都会很快被人遗忘
当我问一位著名的研究人员,他对今年被接受的论文有何看法时,他笑着说:“大部分论文都会在会议结束后被遗忘”。在一个和机器学习一样快速发展的领域里,可能每过几周甚至几天曾经的最好记录就会被打破,正因此对于论文还没发表就已经out了这一现象也就见怪不怪了。例如,根据Borealis Ai对ICLR 2018的统计,“每八篇里面有七篇论文的结果,在ICLR会议开始之前就已经被超越了。”
在会议期间我经常听到的一个评论是,接受/拒绝决定的随机性。尽管我不会指明有哪些,但在过去几年中,确实有一些如今被谈论最多/引用最多的论文在最初提交给会议的时候被拒了。而许多被接受的论文仍将持续数年而不被引用。
作为这个领域的研究者,我经常面临生存危机。不管我有什么想法,似乎别人都已经在做了,越来越好,越来越快。如果一篇论文对任何人都毫无用处,那么发表它又有什么意义呢?救救我吧!!!
结论
当然还有一些其他的趋势需要提及:
优化和正则化:Adam与SGD之争仍在继续。许多新技术已经被提出了,其中一些非常令人兴奋。现在似乎每个实验室都在开发自己的优化器 - 甚至我们团队也在开发新的优化器并且很快就会发布了。
评估指标(evaluation metrics):随着生成模型越来越流行,我们不可避免地需要制定一些指标来评估生成的结果。生成的结构化数据的度量指标至今还问题重重,而生成的非结构化数据(如开放域对话和GAN生成的图像)的度量更是未知的领域。
-
人工智能
+关注
关注
1820文章
50355浏览量
267011 -
rnn
+关注
关注
0文章
92浏览量
7374
原文标题:ICLR 2019八大趋势:RNN正在失去光芒,强化学习仍最受欢迎
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
安路科技2025年度总结
西井科技携手同济大学 三篇AI研究成果入选顶会ICLR 2026

2026年人工智能通信技术发展趋势展望

华为发布2026充电网络产业十大趋势
华为发布2026智能光伏十大趋势
2026年十大远程办公趋势

一文浅谈2026年五大趋势

一文读懂LSTM与RNN:从原理到实战,掌握序列建模核心技术

微软畅谈亚太地区AI跃迁的四大趋势
2025人工智能十大趋势
Abrupt Junction Varactor Diode Chip skyworksinc

Gartner 发布2025年中国人工智能十大趋势
Gartner发布云技术发展的六大趋势



评论