 机器学习/人工智能领域一些非常有创意的突破
机器学习/人工智能领域一些非常有创意的突破
本文介绍了近期在机器学习/人工智能领域一些非常有创意的突破,每一个都脑洞大开,不管是否是相关从业人员都值得一读。并附上一些论文、视频链接和简要总结。
与其他领域相比,机器学习/人工智能现在发展的非常快,经常有一些有趣的突破。让你不由自主的发出“wow”甚至“人间值得”的感叹!(两分钟论文作者的口头禅)
两分钟论文
https://www.youtube.com/channel/UCbfYPyITQ-7l4upoX8nvctg
免责声明:我并没有对“振奋人心”或“突破”进行严格的定义;这只是一个非正式的清单。我会用可能不那么严格的术语来让这篇文章更通俗易懂。
从看似不可用的信息中得出惊人的准确估计
透过墙对人体姿态做估计
麻省理工学院研究人员的网站/视频(2018年)
我们可以根据某人对WiFi信号的扰乱,准确地估计此人在墙壁另一侧是如何站着/坐着/走路的。
从视频中测量材料的物理特性
麻省理工学院研究人员的文章/视频(2015年)
http://news.mit.edu/2015/visual-microphone-identifies-structural-defects-0521
研究人员在2014年首次展示了根据振动情况从薯片包装袋的视频(没有声音)中重现人类的语音。该成果没有涉及机器学习。2015年,他们使用机器学习,并展示了通过视频来估计材料的刚度、弹性、单位面积的重量等(在某些情况下,仅仅空气正常循环引起的振动就足够了)。
从键盘旁边的智能手机估计键盘敲击
论文,2015
https://www.sigmobile.org/mobicom/2015/papers/p142-liuA.pdf
研究人员发现,从一台放在键盘旁边的智能手机中录制的音频,可以以94%的准确率估计键盘敲击。与以前在键盘周围放置许多麦克风的情况下使用有监督的深度学习方法不同,这篇论文实际上使用了相对简单的机器学习技术(k-均值聚类)和无监督学习。
生成模型
逼真的面部生成、样式混合和移植
Nvidia研究人员的论文/视频(2018年)
论文
https://arxiv.org/abs/1812.04948
视频
https://www.youtube.com/watch?v=kSLJriaOumA
研究人员将一种新的结构与大量的GPU结合起来,创造出极其逼真的人造人脸,这些人脸是其他人脸之间的移植,或者是一个人脸到另一个人脸的“样式”应用。这项工作建立在过去关于生成对抗网络(GANs)的工作之上。GANs是在2014年发明的,从那时起对它的研究就出现了爆炸式增长。GANs最基本的解释是两个相互对抗的神经网络(例如,一个是将图像分类为“真实”或“假冒”的神经网络,另一个是以试图“欺骗”第一个神经网络将假冒图像错误分类为真实的方式生成图像的神经网络……因此,第二个神经网络是第一个的“对手”)。
总的来说,关于对抗性机器学习有很多很酷的研究,已经存在了十多年。对网络安全等也有许多令人毛骨悚然的影响,但我再讲就跑题了。
很酷的研究
https://github.com/yenchenlin/awesome-adversarial-machine-learning
教机器绘图
Google Brain的博客帖子(2017年)
https://ai.googleblog.com/2017/04/teaching-machines-to-draw.html
两幅图之间的插值
我在Google Brain的好朋友David Ha用一个生成循环神经网络(RNN)来绘制基于矢量的图形(除了自动以外,我认为这就是Adobe Illustrator)。
David Ha
https://twitter.com/hardmaru
把炫酷的舞步迁移给不会跳舞的人
加州大学伯克利分校研究人员的网站/视频(2018年)
网站
https://carolineec.github.io/everybody_dance_now/
视频
https://www.youtube.com/watch?v=PCBTZh41Ris
想想“舞蹈版的Auto-Tune”。通过姿势估计和生成对抗训练,研究人员能够制作任何真人(“目标”人物)跳舞的假冒视频,视频中的人舞技精湛。所需输入仅为:
一段舞蹈高手的跳舞短视频
几分钟目标人物跳舞的视频(通常很糟,因为大多数人都不擅长跳舞)
我还看到了Nvidia的首席执行官黄延森(Jensen Huang)展示了一段自己像迈克尔杰克逊一样跳舞的视频(用这种技术)。很高兴我之前参加了GPU技术大会,哈哈。
强化学习
世界模型-人工智能在自己的梦里学习
Google Brain网站(2018年)
https://worldmodels.github.io/
人类并不真正了解或思考我们生活的世界里的所有细节。我们的行为基于我们头脑中世界的抽象。例如,如果我骑在自行车上,我不会想到自行车的齿轮/螺母/螺栓;我只是大致了解车轮、座椅和把手的位置以及如何与它们交互。为什么不对人工智能使用类似的方法呢?
这种“世界模型”方法(同样,由David Ha等人创建)允许“agent”(例如,在赛车游戏中控制汽车的人工智能)创建一个世界/周围环境的生成模型,这是对实际环境的简化/抽象。所以,你可以把这个世界模型看作是一个存在人工智能头脑中的梦。然后人工智能可以通过强化学习在这个“梦”中得到更好的表现。因此,这种方法实际上是将生成性机器学习与强化学习相结合。通过这种方式,研究人员能够在特定的电子游戏任务上实现目前最先进的水平。
[2019/2/15更新]在上述“世界模型”方法的基础上,谷歌刚刚发布了PlaNet:Deep Planning Network for Reinformation Learning,与以前的方法相比,数据效率提高了5000%。
PlaNet:Deep Planning Network for Reinformation Learning
https://ai.googleblog.com/2019/02/introducing-planet-deep-planning.html
AlphaStar——击败顶级职业玩家的星际争霸II AI
DeepMind(Google)的博客文章,e-sports-ish视频,2019年
博客文章
https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
e-sports-ish视频
https://www.youtube.com/watch?v=cUTMhmVh1qs
我们在李世石和DeepMind AlphaGo之间的历史性围棋比赛之后已经走了很长的路,这场比赛震撼了全世界,它仅仅发生在3年前的2016年(看看NetFlix纪录片,让一些人哭泣)。更令人惊讶的是,尽管没有使用任何来自人类比赛的训练数据,2017年的AlphaZero在围棋方面比AlphaGo更好(也比国际象棋、日本象棋等领域的其他算法更好)。但2019年的AlphaStar更惊人。
李世石和DeepMind AlphaGo之间的历史性围棋比赛
https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol
NetFlix纪录片
https://www.netflix.com/sg/title/80190844
自1998年以来,作为一名星际迷,我很了解星际的精髓“……需要平衡短期和长期目标,适应意外情况……这是一个巨大的挑战。”这是一个真正困难和复杂的游戏,需要多层次的理解才能玩得好。自2009年以来,对星际游戏算法的研究一直在进行。
AlphaStar基本上使用了监督学习(来自人类比赛)和强化学习(与自身对抗)的组合来实现其结果。
人类训练机器人
通过一次人工演示将任务传授给机器
Nvidia研究人员的文章/视频(2018年)
文章
https://news.developer.nvidia.com/new-ai-technique-helps-robots-work-alongside-humans/
视频
https://www.youtube.com/watch?time_continue=1&v=B7ZT5oSnRys
我可以想到三种典型的方法来教机器人做一些事情,但都需要大量的时间/劳力:
针对每种情况手动编程机器人的关节旋转等
让机器人多次尝试这个任务(强化学习)
多次向机器人演示任务
通常对深度学习的一个主要批评是,产生数以百万计的示例(数据)是非常昂贵的。但是,有越来越多的方法不依赖如此昂贵的数据。
研究人员根据一个单一的人类演示视频(一个实际的人类用手移动方块),找到了一种机器人手臂成功执行任务的方法(例如“拿起方块并将其堆叠起来,使它们按顺序排列:红色、蓝色、橙色”),即使视频是从不同角度拍摄的。该算法实际上生成了一个它计划执行的任务的可读描述,这对于故障排除非常有用。该算法依赖于具有姿态估计,合成训练数据生成和模拟到现实传递的对象检测。
无监督机器翻译
Facebook人工智能研究博客(2018年)
https://code.fb.com/ai-research/unsupervised-machine-translation-a-novel-approach-to-provide-fast-accurate-translations-for-more-languages/
通常,你需要一个庞大的翻译文档训练数据集(例如联合国议项的专业翻译),以便很好地进行机器翻译(即监督学习)。然后,许多主题和语言之间没有高质量、丰富的训练数据。在这篇论文中,研究人员发现,可以使用无监督学习(即不使用翻译数据,只使用每种语言中不相关的语料库),达到最先进的监督学习方法的翻译质量。Wow。
基本思想是,在任何语言中,某些单词/概念往往会出现在很近的位置(例如“毛茸茸的”和“猫咪”)。他们把这描述为“不同语言中的词嵌入具有相似的邻域结构。”好吧,我明白这个想法,但是使用这种方法,他们可以在没有翻译数据集的情况下达到如此高的翻译质量,仍然让人吃惊。
结语
如果你之前没有对机器学习/人工智能的发展感兴趣的话,我希望这篇文章能帮到你。也许一年后我会再写一篇类似的文章。
-
机器人
+关注
关注
212文章
28933浏览量
209709 -
模型
+关注
关注
1文章
3418浏览量
49482 -
机器学习
+关注
关注
66文章
8460浏览量
133437
原文标题:脑洞大开!机器学习与AI突破(附链接)
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
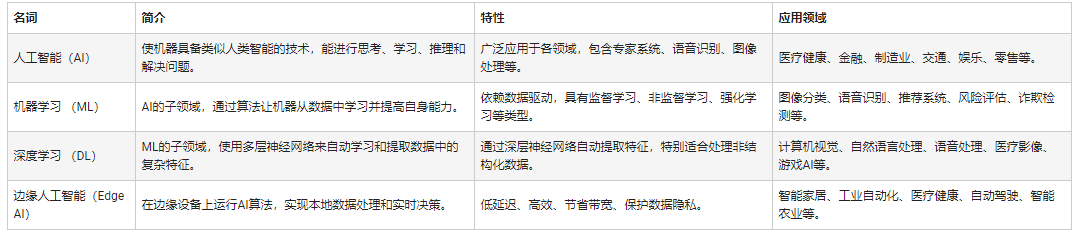
人工智能和机器学习以及Edge AI的概念与应用
人工智能工程师高频面试题汇总——机器学习篇

嵌入式和人工智能究竟是什么关系?
人工智能、机器学习和深度学习存在什么区别






 工商网监
工商网监
评论