 对抗性解耦学习,让“夏虫语冰”
对抗性解耦学习,让“夏虫语冰”
人们常说“夏虫不可语冰”。如果将这句话视为机器学习任务,可以这样理解:夏天生死的虫子只见过液态的水,但从未见过冰。故而你即便拿给它一张冰的照片,它也认不出来这是另一种形态的水。而本文要解决的,就是通过迁移学习,让夏天的虫子也能认出“冰实际就是水。”

摘要
身份认证旨在确认样本和人的身份之间的从属关系。典型的身份认证包含人脸识别(face recognition)、行人重识别(personre-identification),基于移动设备的身份验证。
近年来数据驱动的身份认证过程可能是有偏的,即,模型经常只在一个领域里训练(例如对于穿着春装的人),而可能需要在另一个领域里测试(例如这些人换上了夏装)。
为了解决这个问题,我们提出了一个新颖的两阶段的方法来从领域差异里解耦出类别/身份的特征表示,且我们考虑多种类型的领域差异。在第一阶段中,我们采用一个一对多的解耦学习(one-versus-rest disentangle learning , OVRDL)机制来学习解耦的特征表示。
在第二阶段中,我们提出一个加性对抗学习(additive adversarial learning, AAL)机制来进一步提升解耦性能。并且我们讨论了如何避免由于解耦有因果关系的领域差异而陷入学习困境。实验结果充分证明了我们方法的有效性和优越性。
相关代码即将公布,请关注:https://github.com/langlrsw/AAL-unbiased-authentication。
研究目的:数据驱动的身份验证中的数据偏差问题
身份认证考虑学习与验证数据样本与人的身份之间的匹配关系。近年来,身份验证技术取得了巨大进展,包括指纹验证、人脸验证、声纹/虹膜验证、行人重识别等。然而,数据驱动的身份认证过程经常会面临数据中的偏差,例如领域差异,即一个模型在一个领域中训练却在另一个领域中进行验证。例如在行人重识别领域中,当季节导致人们穿衣变化时或者人与摄像机的相对角度发生变化时,验证都可能受到影响。
特别地,随着智能终端的不断普及,基于智能终端的身份验证技术也飞速发展。而上述情况在基于智能终端的身份验证上也会发生。比如,某个具体用户(由一个虚拟账号关联)的设备类型(由硬件特性或软件编码决定)可能会每一年变化一次,但是用来训练身份验证模型的数据可能每月采集一次。那么当用户对应的设备类型改变时,如果我们依然用旧的设备类型上训练的模型来进行身份认证,就可能输出错误的认证结果。
面临上述的训练和测试数据之间的领域差异的问题,简单地应用数据驱动的模型可能导致模型聚焦于每个领域的偏差,即便训练数据是充足的。为了避免该问题,本文研究了无偏身份验证的学习任务。
简单起见,我们把身份认证视为一个识别问题,即每个身份对应于一个类。我们考虑多种类型的领域差异,每种领域差异有多种领域。例如,对于行人重识别而言,季节和拍摄角度是两种类型的领域差异,其中季节包括四种不同的领域:春、夏、秋、冬,而拍摄角度包含的领域可以有:正面、侧面、背面等。
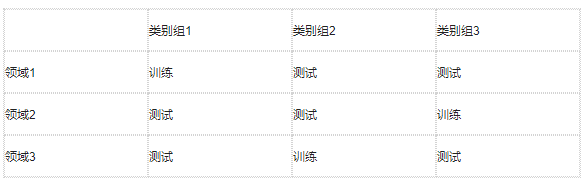
表1 问题假设的范例
为了更好地理解我们的问题,我们展示了一个简单的例子,其中只有一种类型的领域差异,见表 1。在训练阶段,对于每个类别组,我们只有它们一个领域上的数据。换言之,不同的领域不会共享类别。在测试阶段,我们需要识别的数据对应于训练阶段没有见过的<类别,领域>的组合。
在数学上,该问题与领域自适应相关,但是二者也有显著区别:
其一,领域自适应允许源域和目标域共享类别;其二,领域自适应不提供目标域的标签。领域自适应在迁移学习领域中已经被广泛研究。而我们的问题可以被转化为一个领域自适应问题,如果测试领域的数据允许用于训练,且不提供对应的标签的话。因此,我们把该问题称之为一个广义的跨领域识别(generalized cross-domain recognition, GCDR)问题。类似的问题在面向公平的机器学习(fairness-oriented machine learning, FML)领域中被研究过。该领域考虑的偏差主要来自于人口统计学群体的差别,例如肤色、性别等。在这种设定下,FML方法通常也是应用迁移学习方法来进行解决。
在本文中,我们同样考虑应用迁移学习方法来学习无偏的表示。具体地,我们假设领域的差别对于数据的影响是未知的,且我们考虑应用对称、同质的迁移学习方法,即,对所有域学出一个共同的特征空间,且假设所有域的原始特征空间都相同或者至少维数相同。
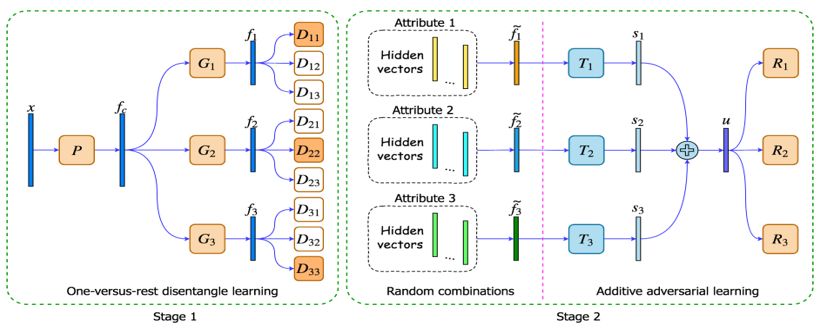
图 1 解耦学习方法详细网络架构图
在本文中,我们提出了一个新颖的识别方法来学习解耦的特征表示,用于解决领域差异,最终实现无偏的识别。如表1中所示,对于一个具体的类别组,类别是不同的,但是领域是相同的。所以,学习一个无偏的模型来进行类别识别是可能的。对于一个数据样本,其类别标签和领域标签都被视为其属性。我们的模型就是通过解耦这些属性来学习无偏的表示。我们方法的详细架构见图 1,其包含两个阶段。
在第一个阶段中,我们提出一对多的解耦学习(one-versus-restdisentangle learning , OVRDL)机制来将每个样本映射到多个隐层空间。在每个隐层空间里,我们将一个属性与其他属性解耦。在第二阶段中,由于训练数据中仅见过有限的属性值的组合,我们采用了一种数据增广的方法来随机组合属性标签,以及拼接其对应的隐层特征向量来作为一个新的数据样本。
基于随机拼接的特征,我们提出一个加性对抗学习(additive adversarial learning, AAL)机制来进一步提升阶段1的解耦性能。
简单来讲,我们通过最小化负面的副作用来消除偏差。我们将讨论扩展到如何避免由于解耦有因果关系的属性而陷入学习困境。在基准数据集和真实数据集上的实验证明了我们方法的有效性和优越性。我们同时进行了消融实验来展示我们框架的每一种成分的贡献。
接下来,我们将具体介绍本文提出的方法的每一个具体技术和思路。
第一步: 更直接地解耦:扬汤止沸,不如釜底抽薪。
通过多任务学习,可以将多属性解耦学习的框架简单地以图 2的形式来构建。其中不同任务对应的特征变换网络的输出特征是假设相互独立的。
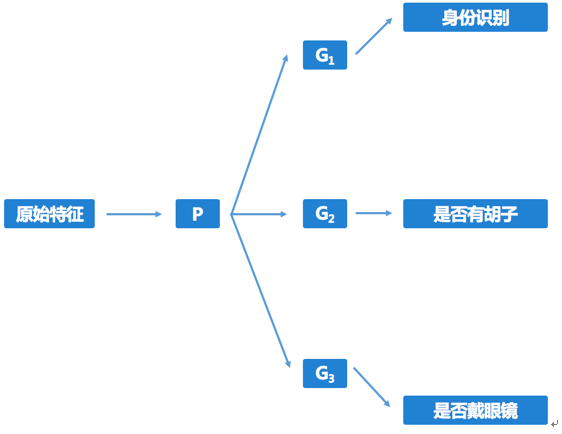
图 2:“假设独立”的学习框架。G网络均为特征变换网络。身份识别、是否有胡子、是否戴眼镜为三个属性,分别建模为三个任务进行学习。不同G网络输出的特征假设相互独立。
但是这种假设只是假设,三个网络输出的特征的独立性是无法保证的。
本文中我们提出通过对抗学习来进行直接解耦,直接逼近“独立”的假设目标。如图 3所示。
假设属性数量图中,D网络分为两类:对于
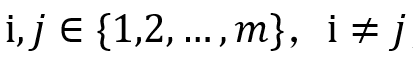
(1)所有的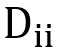 是用于学习第i个属性的特征,所有的
是用于学习第i个属性的特征,所有的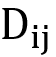
(2)所有的Dii的学习是用标准的监督学习,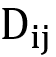
对于 ,一个简单的对抗学习流程可以视为如下两个交替进行的步骤:
,一个简单的对抗学习流程可以视为如下两个交替进行的步骤:
步骤1:固定所有 ,优化
,优化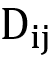 来使得输出逼近与之对应的独热编码的标签;
来使得输出逼近与之对应的独热编码的标签;
步骤2:固定所有
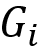

该对抗学习的最终目标是使得所有可以提取与之对应的第i个属性的特征,而不能提取与之对应的其他属性的特征。如此,第i个属性就可以和其他属性解耦。
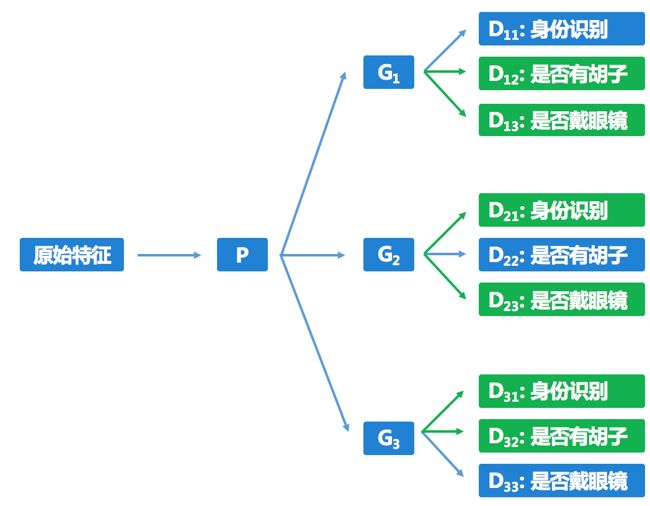
图 3 “直接解耦实现独立”的学习框架。其中绿色的D网络通过对抗学习实现与蓝色D网络目标的解耦,最终实现多个任务的相互独立。
这一步骤中,我们的思路简单可以概括为:假设独立,不如直接解耦令之独立。正如:扬汤止沸,不如釜底抽薪。
第二步:数据增广。张冠李戴,属性随机组合。
由于训练集中不同属性的组合类型比较有限,我们将不同属性对应的隐层特征随机组合。该机制模仿了人类通过想象未见过的属性组合来进行解耦学习的行为。
如图4所示,假设我们只见过棕色的马和白色的兔子,那么我们随机组合马和白色,组合出白色的马,模仿人想象没见过的白色的马。
图 4 属性随机组合示例
不过,这一步骤本身并不进行解耦学习,只是为之后我们提出的加性对抗解耦学习做准备。其他迁移学习方法也有随机生成,不过是在数据原空间生成,可能会引入新的误差。而我们的方法相当于在隐层空间生成新样本,引入的误差较少。
第三步,深入解耦,加性对抗学习。
知白马是马而更识白,知白马是白而更识马。
这一步骤的思路是这样的:当认识到白马也是马,就会知道“白”这个概念中并没有“不是马”的概念,从而能更好地认知“白”这个概念。反过来说,当认识到白马也是白色的,就会知道“马”这个概念中,并没有“不是白色”的概念,从而能更好地认知“马”这个概念。
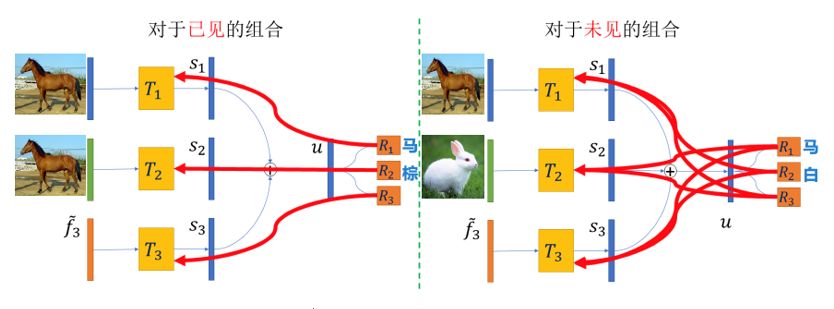
图 5 加性对抗网络的优化机制。红色的曲线箭头表示loss进行BP回传的方向。对于左右两张图,最左边的3个隐层特性向量都是由上一步的随机组合得到的。
加性对抗网络的优化机制如图 5所示。假设前两个属性分别为:物体类别和颜色类别。加性对抗网络的前两条支路依次对应于这两个属性的学习。这里的第一路作为输入的隐层向量是代表物体类别的特征向量,第二路作为输入的隐层向量是代表颜色类别的特征向量。
首先,假设对于见过的属性组合已经学好了,例如,一匹棕色的马可以被精确地识别为物体“马”和颜色“棕”。之后,对于没见过的属性组合,一匹棕色的马和一只白色的兔子,我们要让网络输出物体“马”和颜色“白”。
在假设见过的组合已经学好的前提下,如果现在输出的颜色不是“白”,那么我们有理由相信,误差是来自于网络第一条支路中的“棕色”的信息。那么我们将第二支路输出产生的颜色误差回传至第一条支路来消除其中的颜色信息。这样一来,在第一支路中的颜色信息产生的域差异就被消除了。同理,第二路中的物体信息产生的域差异也可以类似地被消除。
这种加性对抗网络有很好的性质:可以使得经过T网络学习的s向量空间是加性空间,且对于多个特征向量,每一维的含义都相同。最终导致s向量空间中,所有维度的特征被划分为若干组,每一组对应于一个属性。这样一来就有很好的可解释性。同时可以进一步利用稀疏方法进行优化。
这一步骤的idea可以概括为:通过组合概念的加性混合交叉学习而消除概念之间的耦合关系。知白马是马而更识白,知白马是白而更识马。
第四步:拓展讨论。避免因果关系造成的学习困境:皮之不存,毛将焉附。
之前的解耦方式是对每一个属性,都选择所有其他属性进行解耦,但这样可能会将本来有关系的两个属性强制解耦,偏离真实情况。最极端的例子是,如果两个属性本身完全相同,那么在同一个特征空间里,不可能一个属性可以识别而另一个无法识别。
故而,直观上讲,我们不应该将相关的属性解耦。但是,“相关”是一个非常宽泛、不精确的概念。如果但凡有两个属性有关系,我们就放弃对它们解耦,又可能会导致解耦不充分,每种属性还是学不好。
所以,我们考虑一种特殊的相关关系:因果关系。我们在定理2中证明,对于任意的属性A,如果另一个属性B是A的因,那么学习识别A的特征且让该特征无法识别B会有损于对A的识别。这是因为如果该特征与B独立,那么由于属性B是A的因,该特征与A的相关也就很有限了。
如图6所示,以阶段1的学习为例。
在图像上,由于刘海会遮挡眼镜,故而“是否有刘海”会影响“是否有眼镜”的判断;但是反过来,“是否有眼镜”不会影响“是否有刘海”的判断。故而如果G3输出的特征无法区分是否有刘海,那么区分是否有眼镜也很难保证,故而我们学习“是否戴眼镜”的时候放弃了对于“是否有刘海”的解耦学习。综上,如果有关于属性间因果关系的先验信息的话,我们应该停止某些解耦过程来避免上述的学习困境。
这一步骤中,我们的思路可以简单概括为:因不可解耦。因为,因不可辨则果亦难辨,正如:皮之不存,毛将焉附。
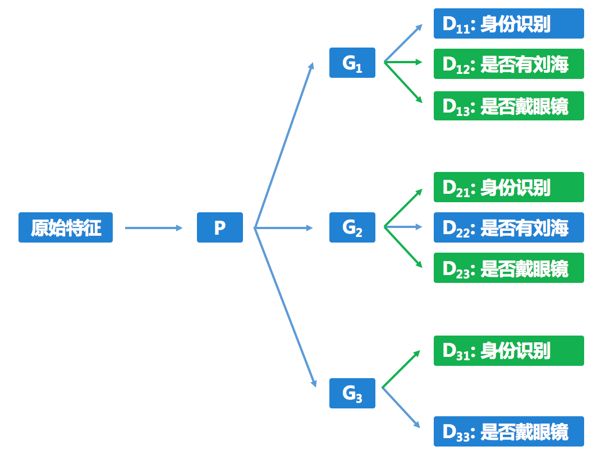
图 6 基于因果关系有选择地解耦学习示例
实验方法
阶段1 对抗学习的优化问题如下:
首先是属性学习的优化问题:
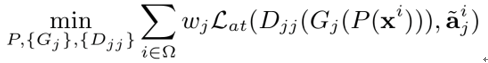
其中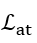 是属性学习的损失函数,
是属性学习的损失函数,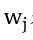 是第j个属性的权重,
是第j个属性的权重,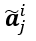 是属性标签的one-hot向量。
是属性标签的one-hot向量。
其次是域差异的判别学习:
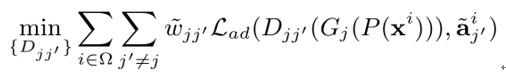
其中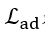 是对抗学习的损失函数, 是(j, j’)属性对的权重。
是对抗学习的损失函数, 是(j, j’)属性对的权重。
第三步是消除域差异:
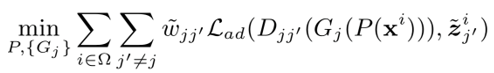
其中

在第三步中,我们也会同时强化属性学习:
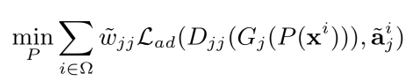
判别网络的最后一层的激活函数是softmax,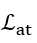 是交叉熵损失,
是交叉熵损失,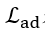 是平均平方误差损失。上述4个优化问题循环依次进行。其中,每个循环中,前两个优化问题优化1步,后两个优化问题优化5步。
是平均平方误差损失。上述4个优化问题循环依次进行。其中,每个循环中,前两个优化问题优化1步,后两个优化问题优化5步。
在阶段2中,对于每个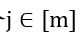 ,我们随机采样训练样本,然后取其第j个属性向量。采样得到的第i个样本的第j个属性的属性向量表示为
,我们随机采样训练样本,然后取其第j个属性向量。采样得到的第i个样本的第j个属性的属性向量表示为 ,其中
,其中 。则对于每个我们将组合为一个新的隐层样本。对于每个属性,每个类别值的采样概率是相同的。我们采用了ABS-Net中剔除低预测概率对应的样本。
。则对于每个我们将组合为一个新的隐层样本。对于每个属性,每个类别值的采样概率是相同的。我们采用了ABS-Net中剔除低预测概率对应的样本。
定义如下两个下标集合:

如图1所示,在阶段2中,随机组合的属性向量被m个加性空间转换网络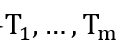
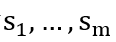
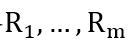
对于训练中见过的属性组合的样本,损失回传至每个属性自己对应的网络,不传至其他属性对应的网络。即对于每个
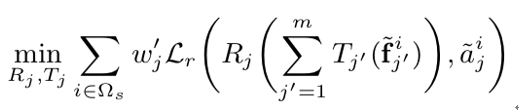
对于训练中没见过的属性组合的样本,损失回传至其他属性对应的网络,不传至自己属性对应的网络。即对于每个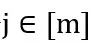 ,我们优化如下的优化问题:
,我们优化如下的优化问题:
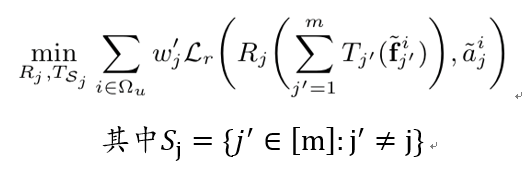
所有识别网络(R网络)的最后一层激活函数也是softmax函数。 是交叉熵损失函数。
是交叉熵损失函数。
根据我们对于有因果关系的属性的讨论,我们采用一个元素值为{0,1}的矩阵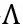
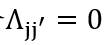 ,否则即令
,否则即令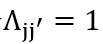 。对于阶段1,我们可以将
。对于阶段1,我们可以将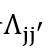 乘在
乘在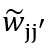 上,对于阶段2,我们可以删掉
上,对于阶段2,我们可以删掉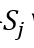 中以j为因的属性。
中以j为因的属性。
实验结果:多个数据集上性能优于对比方法
数据集方面,我们分别基于C-MNIST的数字识别数据集、CelebA的身份识别数据集、手机传感器数据的身份识别数据集构造了我们关注的身份类别由于领域差异而分组的数据集。我们主要参考aAUC、(aFAR+aFRR)/2、ACC@1作为衡量指标。
在C-MNIST数据集上,我们比较了多种迁移学习方法的性能。其中除了SE-GZSL方法,我们的方法达到了最优性能。而SE-GZSL在后面两个真实数据集上表现不佳。
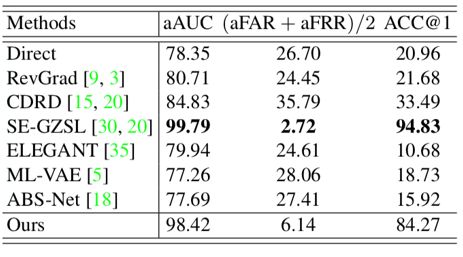
表2 C-MNIST数据集上的性能对比
在CelebA数据集、移动手机数据集上,我们的aAUC和(aFAR+aFRR)/2指标都显著优于对比方法。
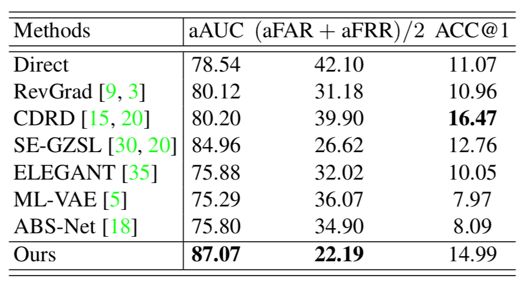
表3 CelebA数据集上性能对比
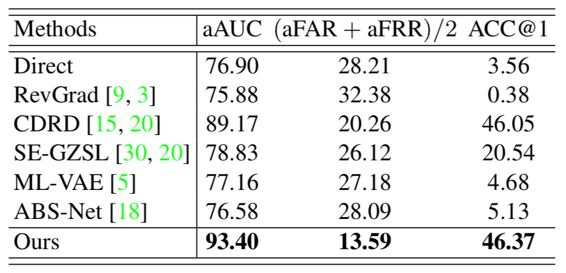
表4 移动手机数据集上的性能对比
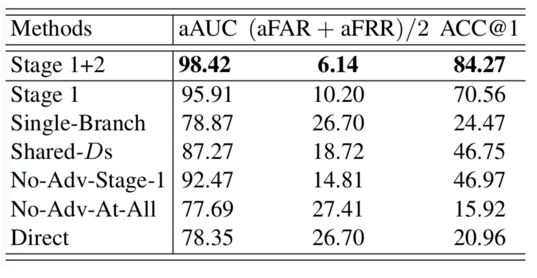
表 5消融实验结果
此外,我们还提供了充分的消融实验证明我们方法中每个技术是有效的,见表5。特别地,我们验证了我们提出的加性对抗学习对阶段1网络有显著的提升效果,见图7。

图 7 加性对抗学习的提升效果。横轴每个值代表阶段1的模型在每个迭代步数时停下来输出模型给阶段2。红色代表阶段1模型的性能,蓝色代表经过加性对抗网络提升后的模型性能。
-
数据集
+关注
关注
4文章
1208浏览量
24700 -
解耦
+关注
关注
0文章
40浏览量
11897 -
迁移学习
+关注
关注
0文章
74浏览量
5561
原文标题:加性对抗学习新模型,消灭身份识别偏差 | CVPR 2019
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
人工智能深度学习发展迅速,智能科技公司都已经涉足人工智能产品的研发!
深度学习DeepLearning实战
常用的解耦设计方法
多变量解耦控制实验
对抗性神经网络是什么?为何入选MIT2018十大突破性技术
对抗样本是如何在不同的媒介上发挥作用的,为什么保护系统很难对抗它们?
迫使神经网络完成计划之外的任务
抗压缩对抗框架ComReAdv:可让人脸识别算法失效
电容解耦如何放置
PWIL:不依赖对抗性的新型模拟学习

一种产生DSN放大攻击的深度学习技术
永磁同步电机控制之反馈解耦及复矢量解耦

人工智能在实现对抗性后勤方面的作用
鉴源实验室·如何通过雷达攻击自动驾驶汽车-针对点云识别模型的对抗性攻击的科普





 工商网监
工商网监
评论