 一个完整的MNIST测试集,其中包含60000个测试样本
一个完整的MNIST测试集,其中包含60000个测试样本
尽管MNIST是源于NIST数据库的基准数据集,但是导出MNIST的精确处理过程已经随着时间的推移被人们多遗忘。因此,作者提出了一种足以替代MNIST数据集的重建数据集,并且它不会带来准确度的降低。作者将每个MNIST数字与它在NIST中的源相对应,并得到了更加丰富的元数据,如作者标识符、分区标识符等。作者还重建了一个完整的MNIST测试集,其中包含60000个测试样本,而不是通常使用的10000个样本。由于多余的50000个样本没有被使用,因此可以用来探究25年来已有的MNIST实验模型在该数据集上的测试效果。
引言
MNIST数据集被用作机器学习的基准集已经超过二十年了。在过去的十年中,许多研究者都表示该数据集已经被过度使用了。特别是它仅有10000个样本用于测试,这引起了不少的关注。已有数百篇论文的方法在这个测试集上取得越来越好的效果。那这些模型是否在测试集上过拟合?我们还能相信在这个数据集上得到的新结论吗?机器学习的数据集多久会变得无用?
NIST手写字符集的第一部分已经在一年前发布,它是一个由2000名人口普查局员工手写的训练集和500名高中生手写的更具挑战性的测试集。 LeCun、Cortes 和Burges的目标是创建一个具有类似分布的训练集和测试集。这个过程生成了两组60000个样本的数据集,可能是由于当时电脑计算这些数据集的速度非常慢,他们将测试集下采样到仅10000个样本,因此多余的50000样本从未被用于任何的测试。
本文研究的目的是重建MNIST预处理算法,以便将每个MNIST数字图追溯到NIST中原始的手写体。这种重建是基于可用信息,之后通过迭代细化来提升它的水平。第2节描述了这个过程,并计算了重建样本与官方MNIST样本的匹配程度。重建的训练集包含了与原有MNIST训练集相匹配的60000张图片。类似的,重建的10000张测试图片也与MNIST测试集里面的每张图片相匹配。剩下的50000张是对在MNIST中丢失的50000张图像的重建。
与Recht等人一致,重建这50000张样本,使得研究人员可以量化官方MNIST测试集在25年来退化的过程。第3节比较和讨论了在一些知名算法在原始MNIST测试集、重建MNIST测试集,以及丢失的50000测试样本集上进行测试的性能。本文的实验结果在不同数据集上验证了Recht et al. [2018, 2019]指出的趋势。
重构MNIST
图1:LeCun94年文献中描述MNIST的处理过程
图1 显示的是MNIST创建的过程。作者提到,该描述错误地描述了数字图在hsf4分区中的位数,在原始的NIST测试集中应该是58527,而不是58646。这两段话给出了一个相对精确的处理方法,使用它生成的数据集比实际MNIST训练集多了一个0,少了一个8。尽管并不匹配,这些类分布是如此相近,以至于hsf4分区中确实好像缺少了119位。那么应该如何来裁剪128x128的二进制NIST图像?应该使用哪种启发式算法来忽略不属于图片本身的噪声像素?以及对于最终的中心坐标,应该如何四舍五入呢?
本文的初始重建算法是根据图1中的描述得到的,但作者在Lush代码库里面发现了另一种重采用的算法,它不是使用双线性插值或双三次插值,而是计算输入和输出的精确重叠像素。作者重建的第一个QMNISTV1与实际的MNIST非常相似,但是存在着锯齿图像,因此作者通过微调初始中心坐标和重采样算法,得到了QMNISTV2。
图2:并排显示MNIST和QMNIST的图像,其中放大图说明了重建的图片是抗锯齿像素的。
接着,作者又发现MNIST和QMNIST之间的最小距离L2是一个较可靠的指标,因此作者使用匈牙利算法计算匹配度,并进一步调整裁剪算法,这样一步一步迭代调整,又可以得到QMNISTV3、V4、V5。最终得到了QMNIST。
评估QMNIST
作者做了一系列实验来评估QMNIST与MNIST之间的差距。
表1:在MNIST和QMNIST之间抖动像素的四分位数,L2距离表示一个像素的差异,L1距离表示像素之间的最大绝对差。
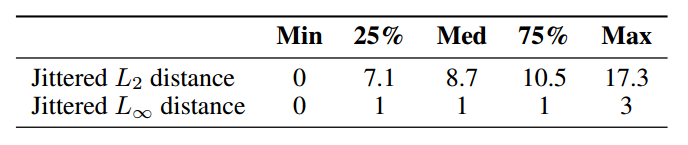
表2:在没有平移或+-1像素平移下,MNIST和QMNIST训练图像标齐的数量
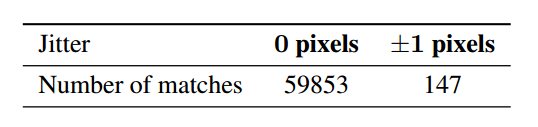
表3:在MNIST和QMNIST训练集上训练LeNet5卷积网络,并在MNIST测试集、QMNIST测试集和QMNIST新部分上进行测试

重构观察到的结论
重构MNIST,使作者发现了一些之前未报道过的关于MNIST的事情。
1、整个NIST手写字符集只有三个重复的数字,其中只有一个属于生成MNIST的字段,但被MNIST作者删除了。
2、MNIST测试集的前5001张图片似乎是从高中生(#2350-#2599)写的图片中随机挑选出来的,接下来的4999张图片是按顺序(#35000-#39998)由48位人工普查局员工(#326-#373)撰写的,虽然人数有点少,可能让人担心统计样本有问题,但这些图像比较干净,几乎对总测试误差没有影响。
3、第一个MNIST训练集样本中的偶数图像与高中学生所写的数字完全匹配,其余图像是NIST图像#0到#30949的顺序。这意味着在连续的mini-batch的MNIST训练图像中,图像可能是同一人写的。因此作者建议在minibatch中,打乱训练集。
4、28x28MNIST图像的中心点存在舍入误差。事实中,MNIST数字的平均中心原理图像几何中心至少半个像素。这很重要,因为使用正确的图像进行训练,然后在MNIST上进行测试,可能会使模型性能下降很多。
5、MNIST重采样代码中的缺陷会在粗字符的暗区域产生低幅周期性的图像。这在Lush代码中仍然可见,这些模式的周期取决于传递给重采样代码的输入和输出图像的相对大小。
6、关于将二次采样图像的连续值像素转换为整数值像素有一些奇怪的事情。我们当前的代码将每个图像中观察到的范围线性映射到区间【0.0,255.0】,之后四舍五入到最接近的整数。然而,像素比较直方图显示MNIST值128的像素更多,值255的像素更少。
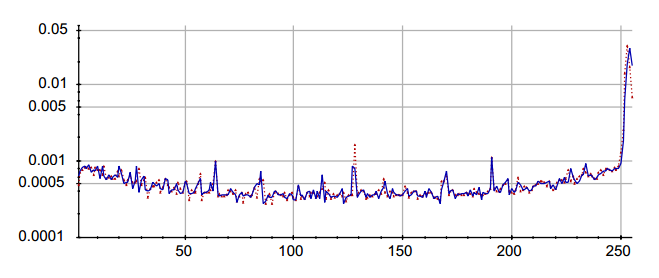
图3:像素直方图对比,红色为MNIST,蓝色为QMNIST。
泛化性能评估
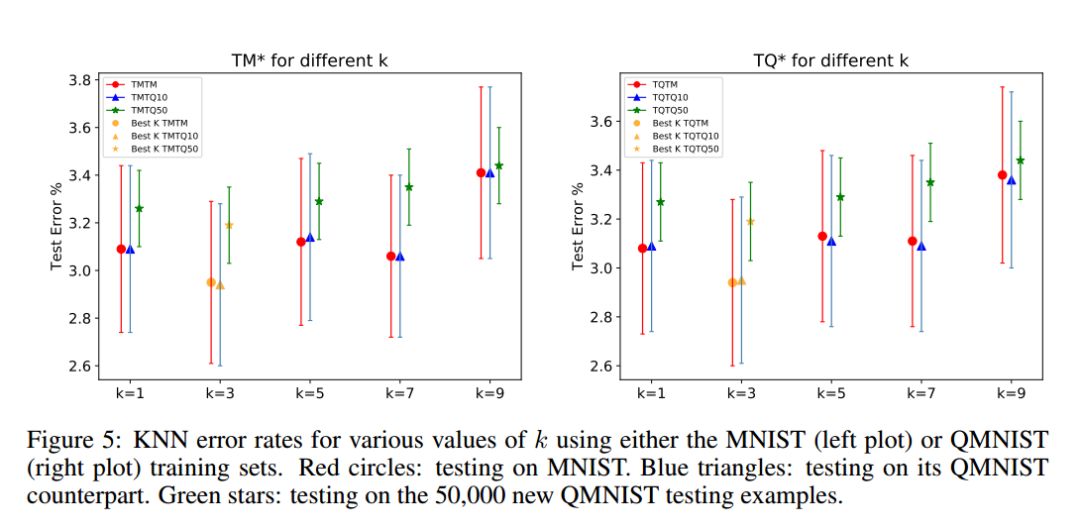
本节是利用未用的50000个样本,来重新审视已经报道过的一些论文结论。Recht等人对CIFAR10和ImageNet有类似的研究。作者使用了三个测试集:MNIST测试集(10000张)、重建的QMNIST测试集(10000张,QMNIST10),以及重建的未用的50000张测试集(QMNIST50)。在MNIST训练集上,类似地,我们使用TQTM、TQTQ10和TQTQ50来表示结果。这些数据都没有使用数据增强。作者使用了KNN、SVM、MLP、Lenet5等方法。
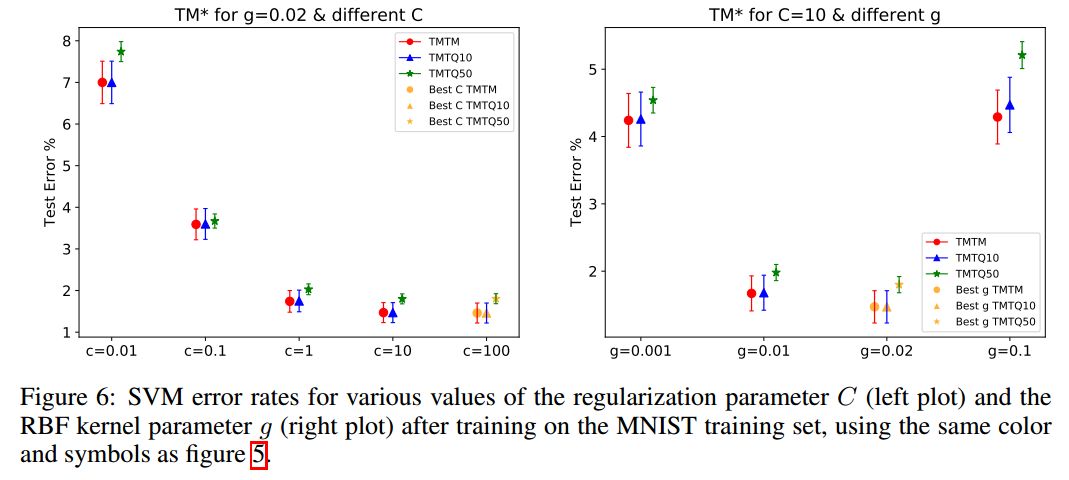
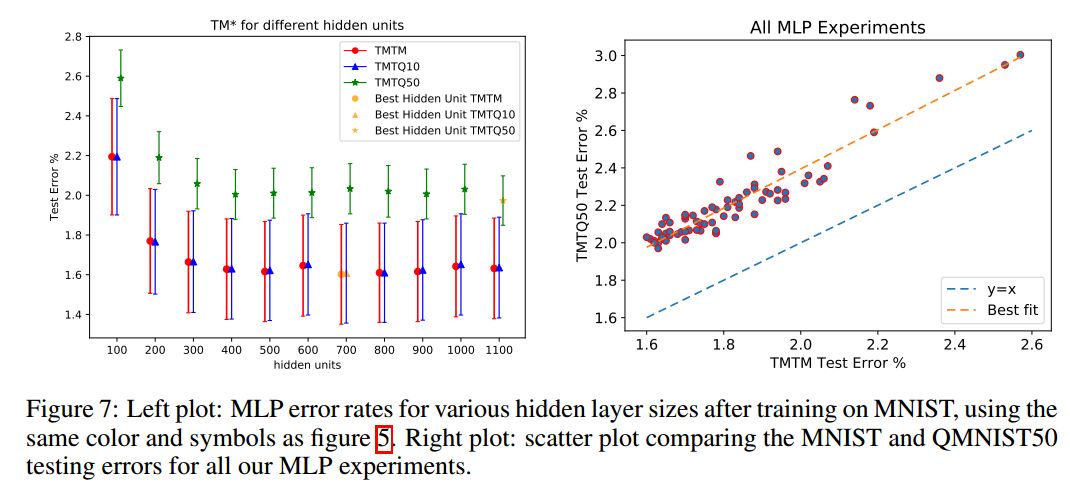
总结
作者重构了MNIST数据集,不仅是重新溯源到NIST源图像和相关元数据,还重构了原始MNIST测试集,包括从未发布的50000个测试样本。经过长时间的研究,作者的发现与Recht等人的成果一致。所有这些结果都表明“测试集腐烂”问题确实存在,但远远没有研究者担心的那么严重,重复使用相同测试集会影响性能,但它同样有利于模型选择。
-
机器学习
+关注
关注
66文章
8458浏览量
133285 -
数据集
+关注
关注
4文章
1212浏览量
24941 -
MNIST
+关注
关注
0文章
10浏览量
3419
原文标题:MNIST重生,测试集增加至60000张!
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
清洗误标注的开发集和测试集样本
如何研究带有菊花链路由的BGA测试样本?
TensorFlow逻辑回归处理MNIST数据集
TensorFlow逻辑回归处理MNIST数据集
如何利用keras打包制作mnist数据集
针对特定测试样本的隐写分析方法
如何用Fashion-MNIST数据集搭建一个用于辨认时尚单品的机器学习模型
基于测试样本误差重构的协同表示分类方法
兆易创新“一种NAND闪存芯片的测试样本”专利获授权





 工商网监
工商网监
评论