 从零开始学习机器学习最简单的 KNN 算法
从零开始学习机器学习最简单的 KNN 算法
今天开始,我打算写写机器学习教程。说实话,相比爬虫,掌握机器学习更实用竞争力也更强些。
目前网上大多这类教程对新手都不友好,要么直接调用 Sklearn 包,要么满篇抽象枯燥的算法公式文字,看这些教程你很难入门,而真正适合入门的手写 Python 代码教程寥寥无几。最近看了慕课网 bobo 老师的机器学习课程后,大呼过瘾,最好的机器学习教程没有之一。我打算以他的教程为基础并结合自己的理解,从零开始更新机器学习系列推文。
第一篇推文先不扯诸如什么是机器学习、机器学习有哪些算法这些总结性的文章,在你没有真正知道它是什么之前,这些看了也不会有印象反而会增加心理负荷。
所以我将长驱直入直接从一个算法实战开始,就像以前爬虫教程一样,当你真正感受到它的趣味性后,才会有想去学它的欲望。
下面就从一个场景故事开始。
01 场景代入
在一个酒吧里,吧台上摆着十杯几乎一样的红酒,老板跟你打趣说想不想来玩个游戏,赢了免费喝酒,输了付 3 倍酒钱,赢的概率有 50%。你是个爱冒险的人,果断说玩。
老板接着道:你眼前的这十杯红酒,每杯略不相同,前五杯属于「赤霞珠」,后五杯属于「黑皮诺」。现在,我重新倒一杯酒,你只需要根据刚才的十杯正确地告诉我它属于哪一类。
听完你有点心虚:根本不懂酒啊,光靠看和尝根本区分辨不出来,不过想起自己是搞机器学习的,不由多了几分底气爽快地答应了老板。
你没有急着品酒而是问了老板每杯酒的一些具体信息:酒精浓度、颜色深度等,以及一份纸笔。老板一边倒一杯新酒,你边疯狂打草稿。很快,你告诉老板这杯新酒应该是「赤霞珠」。
老板瞪大了眼下巴也差点惊掉,从来没有人一口酒都不尝就能答对,无数人都是反复尝来尝去,最后以犹豫不定猜错而结束。你神秘地笑了笑,老板信守承诺让你开怀畅饮。微醺之时,老板终于忍不住凑向你打探是怎么做到的。
你炫耀道:无他,但机器学习熟尔。
02 kNN 算法介绍
接下来,我们就要从这个故事中开始接触机器学习了,机器学习给很多人的感觉就是「难」,所以我编了上面这个故事,就是要引出机器学习的一个最简单算法:kNN 算法(K-Nearest Neighbor),也叫 K 近邻算法。
别被「算法」二字吓到,我保证你只要有高中数学加上一点点 Python 基础就能学会这个算法。
学会 kNN 算法,只需要三步:
了解 kNN 算法思想
掌握它背后的数学原理(别怕,你初中就学过)
最后用简单的 Python 代码实现
在说 kNN 算法前说两个概念:样本和特征。
上面的每一杯酒称作一个「样本」,十杯酒组成一个样本集。酒精浓度、颜色深度等信息叫作「特征」。这十杯酒分布在一个多维特征空间中。说到空间,我们最多能感知三维空间,为了理解方便,我们假设区分赤霞珠和黑皮诺,只需利用:酒精浓度和颜色深度两个特征值。这样就能在二维坐标轴来直观展示。
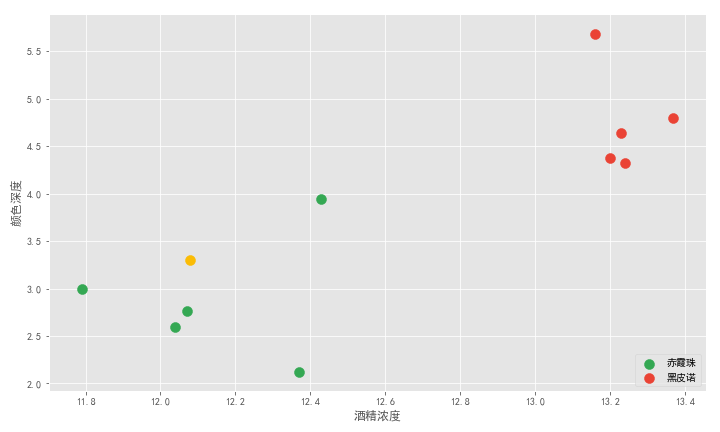
横轴是酒精浓度值,纵轴是颜色深度值。十杯酒在坐标轴上形成十个点,绿色的 5 个点代表五杯赤霞珠,红色的 5 个点代表五杯黑皮诺。可以看到两类酒有明显的界限。老板新倒的一杯酒是图中黄色的点。
记得我们的问题么?要确定这杯酒是赤霞珠还是黑皮诺,答案显而易见,通过主观距离判断它应该属于赤霞珠。
这就用到了 K 近邻算法思想。该算法首先需要取一个参数 K,机器学习中给的经验取值是 3,我们假设先取 3 ,具体取多少以后再研究。对于每个新来的点,K 近邻算法做的事情就是在所有样本点中寻找离这个新点最近的三个点,统计三个点所属类别然后投票统计,得票数最多的类别就是新点的类别。
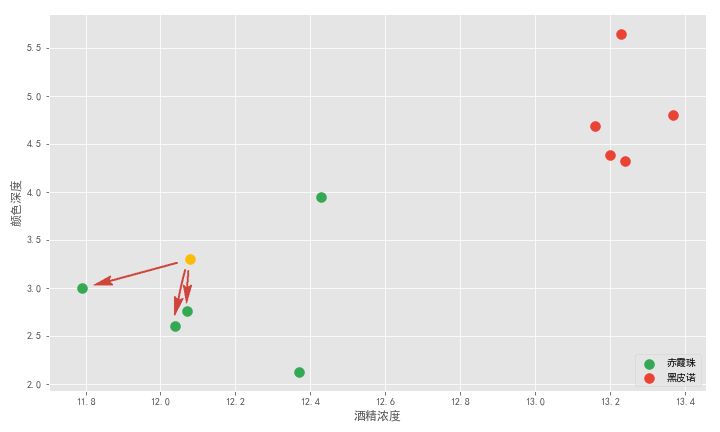
上图有绿色和红色两个类别。离黄色最近的 3 个点都是绿点,所以绿色和红色类别的投票数是 3:0 ,绿色取胜,所以黄色点就属于绿色,也就是新的一杯就属于赤霞珠。
这就是 K 近邻算法,它的本质就是通过距离判断两个样本是否相似,如果距离够近就觉得它们相似属于同一个类别。当然只对比一个样本是不够的,误差会很大,要比较最近的 K 个样本,看这 K 个 样本属于哪个类别最多就认为这个新样本属于哪个类别。
是不是很简单?
再举一例,老板又倒了杯酒让你再猜,你可以在坐标轴中画出它的位置。离它最近的三个点,是两个红点和一个绿点。红绿比例是 2:1,红色胜出,所以 K 近邻算法告诉我们这杯酒大概率是黑皮诺。
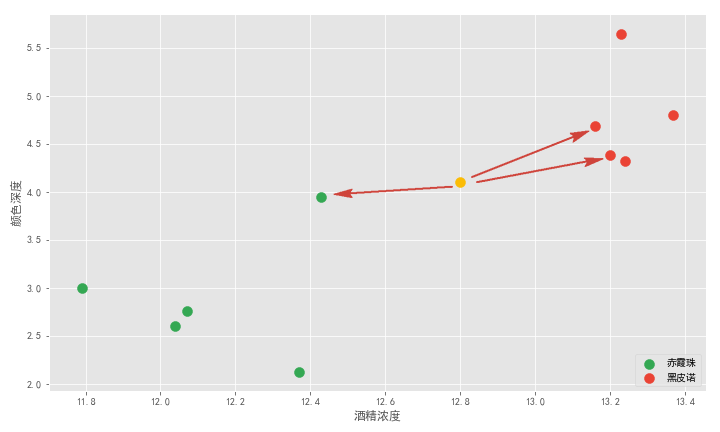
可以看到 K 近邻算法就是通过距离来解决分类问题。这里我们解决的二分类问题,事实上 K 近邻算法天然适合解决多分类问题,除此之外,它也适合解决回归问题,之后一一细讲。
02 数学理论
K 近邻算法基本思想我们知道了,来看看它背后的数学原理。该算法的「距离」在二维坐标轴中就是两点之间的距离,计算距离的公式有很多,一般常用欧拉公式,这个我们中学就学过:
![]()
解释下就是:空间中 m 和 n 两个点,它们的距离等于 x y 两坐标差的平方和再开根。
如果在三维坐标中,多了个 z 坐标,距离计算公式也相同:
![]()
当特征数量有很多个形成多维空间时,再用 x y z 写就不方便,我们换一个写法,用 X 加下角标的方式表示特征维度,这样 n 维 空间两点之间的距离公式可以写成:
![]()
公式还可以进一步精简:

这就是 kNN 算法的数学原理,不难吧?
只要计算出新样本点与样本集中的每个样本的坐标距离,然后排序筛选出距离最短的 3 个点,统计这 3 个点所属类别,数量占多的就是新样本所属的酒类。
根据欧拉公式,我们可以用很基础的 Python 实现。
03 Python 代码实现
首先随机设置十个样本点表示十杯酒,我这里取了 Sklearn 中的葡萄酒数据
集的部分样本点,这个数据集在之后的算法中会经常用到会慢慢介绍。
1import numpy as np 2X_raw = [[14.23, 5.64], 3 [13.2 , 4.38], 4 [13.16, 5.68], 5 [14.37, 4.80 ], 6 [13.24, 4.32], 7 [12.07, 2.76], 8 [12.43, 3.94], 9 [11.79, 3. ],10 [12.37, 2.12],11 [12.04, 2.6 ]]1213y_raw = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
X_raw 的两列值分别是颜色深度和酒精浓度值,y_raw 中的 0 表示黑皮诺,1 表示赤霞珠。
新的一杯酒信息:
1x_test = np.array([12.8,4.1])
在机器学习中常使用 numpy 的 array 数组而不是列表 list,因为 array 速度快也能执行向量运算,所以在运算之前先把上面的列表转为数组:
1X_train = np.array(X_raw)2y_train = np.array(y_raw)
有了 X Y 坐标就可以绘制出第一张散点图:
1import matplotlib.pyplot as plt 2plt.style.use(‘ggplot’) 3plt.figure(figsize=(10,6)) 4 5plt.scatter(X_train[y_train==1,0],X_train[y_train==1,1],s=100,color=color_g,label=‘赤霞珠’) 6plt.scatter(X_train[y_train==0,0],X_train[y_train==0,1],s=100,color=color_r,label=‘黑皮诺’) 7plt.scatter(x_test2[0],x_test2[1],s=100,color=color_y) # x_test 8 9plt.xlabel(‘酒精浓度’)10plt.ylabel(‘颜色深度’)11plt.legend(loc=‘lower right’)1213plt.tight_layout()14plt.savefig(‘葡萄酒样本.png’)
接着,根据欧拉公式计算黄色的新样本点到每个样本点的距离:
1from math import sqrt 2distances = [sqrt(np.sum((x - x_test)**2)) for x in X_train] # 列表推导式 3distances 4 5[out]: 6[1.7658142597679973, 7 1.5558920271021373, 8 2.6135799203391503, 9 1.9784084512557052,10 1.5446682491719705,11 0.540092584655631,12 0.7294518489934753,13 0.4172529209005018,14 1.215113163454334,15 0.7011419257183239]
上面用到了列表生成式,以前的爬虫教程中经常用到,如果不熟悉可以在公众号搜索「列表生成式」关键字复习。
这样就计算出了黄色点到每个样本点的距离,接着找出最近的 3 个点,可以使用 np.argsort 函数返回样本点的索引位置:
1sort = np.argsort(distances)2sort34[out]:array([7, 5, 9, 6, 8, 4, 1, 0, 3, 2], dtype=int64)
通过这个索引值就能在 y_train 中找到对应酒的类别,再统计出排名前 3 的就行了:
1K = 3 2topK = [y_train[i] for i in sort[:K]]3topK45[out]:[1, 1, 1]
可以看到距离黄色点最近的 3 个点都是绿色的赤霞珠,与刚才肉眼观测的结果一致。
到这里,距离输出黄色点所属类别只剩最后一步,使用 Counter 函数统计返回类别值即可:
1from collections import Counter2votes = Counter(topK)3votes4[out]:Counter({1: 3})56predict_y = votes.most_common(1)[0][0]7predict_y8[out]:1
最后的分类结果是 1 ,也就是新的一杯酒是赤霞珠。
我们使用 Python 手写完成了一个简易的 kNN 算法,是不是不难?
如果觉得难,来看一个更简单的方法:调用 sklearn 库中的 kNN 算法,俗称调包,只要 5 行代码就能得到同样的结论。
04 sklearn 调包
1from sklearn.neighbors import KNeighborsClassifier 2kNN_classifier = KNeighborsClassifier(n_neighbors=3)3kNN_classifier.fit(X_train,y_train )4x_test = x_test.reshape(1,-1)5kNN_classifier.predict(x_test)[0]67[out]:1
首先从 sklearn 中引入了 kNN 的分类算法函数 KNeighborsClassifier 并建立模型,设置最近的 K 个样本数量 n_neighbors 为 3。接下来 fit 训练模型,最后 predict 预测模型得到分类结果 1,和我们刚才手写的代码结果一样的。
你可以看到,sklearn 调包虽然简单,不过作为初学者最好是懂得它背后的算法原理,然后用 Python 代码亲自实现一遍,这样入门机器学习才快。
-
KNN
+关注
关注
0文章
22浏览量
10895 -
机器学习
+关注
关注
66文章
8464浏览量
133528
原文标题:Python手写机器学习最简单的KNN算法
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
智能机器人学习机WT3000A AI芯片方案-自然语音交互 打造沉浸式学习体验

机器学习模型市场前景如何
传统机器学习方法和应用指导

NPU与机器学习算法的关系
【每天学点AI】KNN算法:简单有效的机器学习分类器
人工智能、机器学习和深度学习存在什么区别

合肥汤诚音频功放芯片XA9812B早教机套装儿童智能学习机应用解决方案






 工商网监
工商网监
评论