 智能语音机器人工作原理
智能语音机器人工作原理
信息时代,科学技术的飞速发展带动人工智能化技术的更新进步。机器人的应用领域和范围也越来越广泛,在生产、建筑、旅游等各个行业都能够看到人工智能机器人的身影。 旅游产业与互联网的结合,要随着信息技术的发展与时俱进。物联网、人工智能、虚拟现实等新兴的互联网技术让旅游产业的未来充满了挑战与机遇,导游等依赖大数据的职业完全可能被人工智能机器人取代。
语音助手越来越像人类了,与人类之间的交流不再是简单的你问我答,不少语音助手甚至能和人类进行深度交谈。在交流的背后,离不开自然语言处理(NLP)和自然语言生成(NLG)这两种基础技术。机器学习的这两个分支使得语音助手能够将人类语言转换为计算机命令,反之亦然。
这两种技术有什么差异?工作原理是什么?
NLP vs NLG:了解基本差异
什么是NLP?
NLP指在计算机读取语言时将文本转换为结构化数据的过程。简而言之,NLP是计算机的阅读语言。可以粗略地说,在NLP中,系统摄取人语,将其分解,分析,确定适当的操作,并以人类理解的语言进行响应。
NLP结合了计算机科学、人工智能和计算语言学,涵盖了以人类理解的方式解释和生成人类语言的所有机制:语言过滤、情感分析、主题分类、位置检测等。
什么是NLG?
自然语言处理由自然语言理解(NLU)和自然语言生成(NLG)构成。NLG是计算机的“编写语言”,它将结构化数据转换为文本,以人类语言表达。即能够根据一些关键信息及其在机器内部的表达形式,经过一个规划过程,来自动生成一段高质量的自然语言文本。
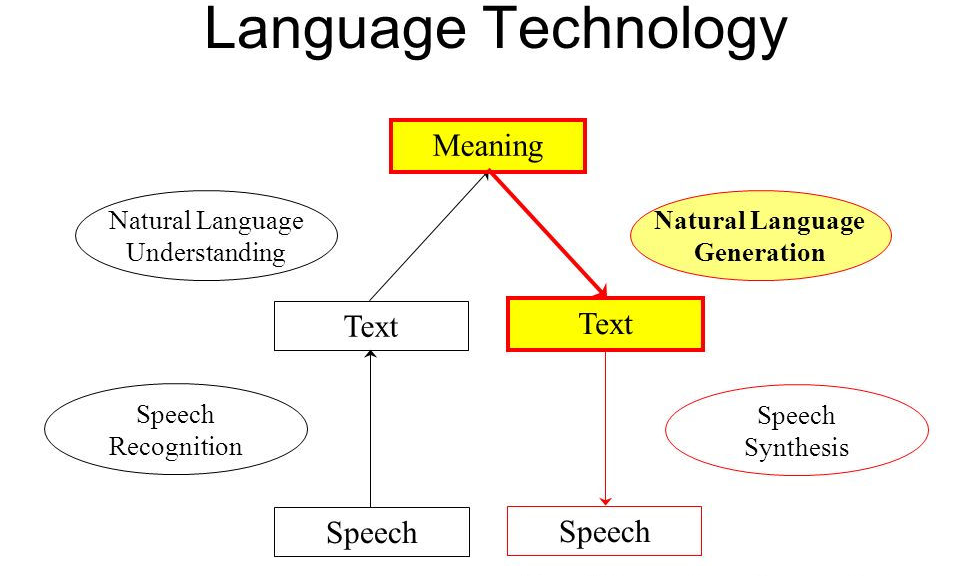
NLP vs NLG:聊天机器人的工作方式
人类谈话涉及双向沟通的方式,聊天机器人也一样,只是沟通渠道略有不同——您是与机器交谈。当给机器人发送消息时,它会将其拾取并使用NLP,机器将文本转换为自身的编码命令。然后将该数据发送到决策引擎。
在整个过程中,计算机将自然语言转换为计算机理解的语言,处理,识别语音。语音识别系统常用的是Hidden Markov模型(HMM),它将语音转换为文本以确定用户所说的内容。通过倾听您所说的内容,将其分解为小单元,并对其进行分析以生成文本形式的输出或信息。
此后的关键步骤是自然语言理解(NLU),如上文所说,它是NLP的另一个子集,试图理解文本形式的含义。重要的是计算机要理解每个单词是什么,这是由NLU执行的部分。在对词汇、语法和其他信息进行筛选时,NLP算法使用统计机器学习、应用自然语言的语法规则,并确定所说的最可能的含义。
另一方面,NLG是一种利用人工智能和计算语言学生成自然语言的系统。它还可以将该文本翻译成语音。NLP系统首先确定要翻译成文本的信息,然后组织表达结构,再使用一组语法规则,NLG就能系统形成完整的句子并读出来。
应用
语音助手只是NLP众多应用程序之一。它还可用于网络安全文章、白皮书、科研等领域。例如,NLP对在线内容进行情绪分析,以改进服务并为客户提供更好的产品。
而NLG通常用于Gmail,它可以为您自动创建答复。创建公司数据图表的描述说明时,NLG也是很好的工具。
说NLP和NLG完全不相关,也不正确,因为NLP和NLG相当于学习中的阅读、写作过程,还是有内在关联的。
一般智能语音助理或语音机器人工作原理大致如下:
第一阶段:语音到文本的过程。信号源→设备(捕获音频输入)→增强音频输入→检测语音→转换为其他形式(如文本)
第二阶段:响应过程。处理文本(如用NLP处理文本,识别意图)→操作响应。
在检测语音过程中,就包括分辨是否为语音信号,该过程会通过指定的频率对模拟信号进行采样,将模拟声波转换为数字数据。这一过程很重要,是否成功地识别语音。如果生成数字数据都是错误的,那么后期的处理响应那肯定是错的。这也是影响智能语音助理或语音机器人识别率的重要因素。
在这个过程,用于语音处理的技术是语音活性检测 (Voice activity detection,VAD),目的是检测语音信号是否存在。 VAD技术主要用于语音编码和语音识别。它可以简化语音处理,也可用于在音频会话期间去除非语音片段:可以在IP电话应用中避免对静音数据包的编码和传输,节省计算时间和带宽。
与大家分享VAD技术,首先讲两个概念:
信噪比(缩写为SNR或S / N)是科学和工程中使用的一种度量,它将所需信号的电平与背景噪声电平进行比较。SNR定义为信号功率与噪声功率之比,通常以分贝表示。比率高于1:1(大于0 dB)表示信号多于噪声。
窗口,研究信号源,我们将其分成滑动窗口或仅窗口。
能量检测器
能量检测器对于高SNR信号是有效的,但是当SNR下降直到它在1以下变得无效时失去效率。它也不能将语音与诸如冲击噪声(将笔放在桌子上),打字,空调或任何噪声之类的噪声区分开来。比人声更响亮或更响亮。
波形和频谱分析
在波形和频谱分析中,语音活动检测利用语音的已知特征。在该方法中应用VAD比基于能量的解决方案更加计算密集,但是能够更好地检测非平稳噪声和低SNR场景中的噪声。对于浊音音素,声带的振动产生谐波丰富的声音,具有50到250 Hz之间的明显音调。所有元音,但也有一些辅音,表现出这种谐波结构,因此是语音的特征。代表谐波结构的特征是语音的可靠指标。然而,单独使用基于谐度或基于音调的特征不能预期无声语音部分(例如一些摩擦音)被检测到。此外,音乐或其他谐波噪声分量可能被误解为语音。总的来说,对信号的倒谱的分析可以揭示信号能量的来源。同样的,基于该共振峰结构,也是语音识别系统的重要特征。人类声道中的可变腔允许扬声器形成不同的音素。强调谐振(或共振峰)频率,导致频谱包络的特征形状。平滑很重要,在一个对话中,一个人只有50%的时间在说话,并且存在大量非活动帧。诸如[p] [t] [k] [b]之类的音是静音,并且静音部分可能不会被算法识别为语音,这将影响自动语音识别系统的性能。解决方案如下:
要被视为语音,必须至少有3个连续的窗口标记语音(192ms)。它可以防止短暂的噪音被视为语音。
要被认为是沉默,必须至少连续3个窗口标记为静音。它可以防止过多的语音切入影响语音节奏。
如果窗口被认为是语音,则前3个窗口和3个窗口被认为是语音。它可以防止在句子开头和结尾丢失信息。
基于统计分析
MFCC,FBANK,PLP是最常用的语音识别功能。有数学运算的连接,旨在通过保持最相关的数据来减少和压缩信息的数量。
在“信号源→设备(捕获音频输入)→增强音频输入→检测语音”过程中,语音成功采样识别为数字数据,是后期语言处理的前提,在检测中文面临更大挑战,断句、语气、语调等因素直接影响识别率。
-
机器人
+关注
关注
211文章
28483浏览量
207432 -
智能语音
+关注
关注
10文章
786浏览量
48808 -
自然语言处理
+关注
关注
1文章
619浏览量
13579
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论