 为什么说AI推理芯片大有可为?
为什么说AI推理芯片大有可为?
近年来科技热潮一波接一波,2013年、2014年开始倡议物联网、穿戴式电子,2016年开始人工智能,2018年末则为5G。人工智能过往在1950年代、1980年代先后热议过,但因多项技术限制与过度期许而回复平淡,2016年随云端资料日多与影音辨识需求再次走红(图1)。
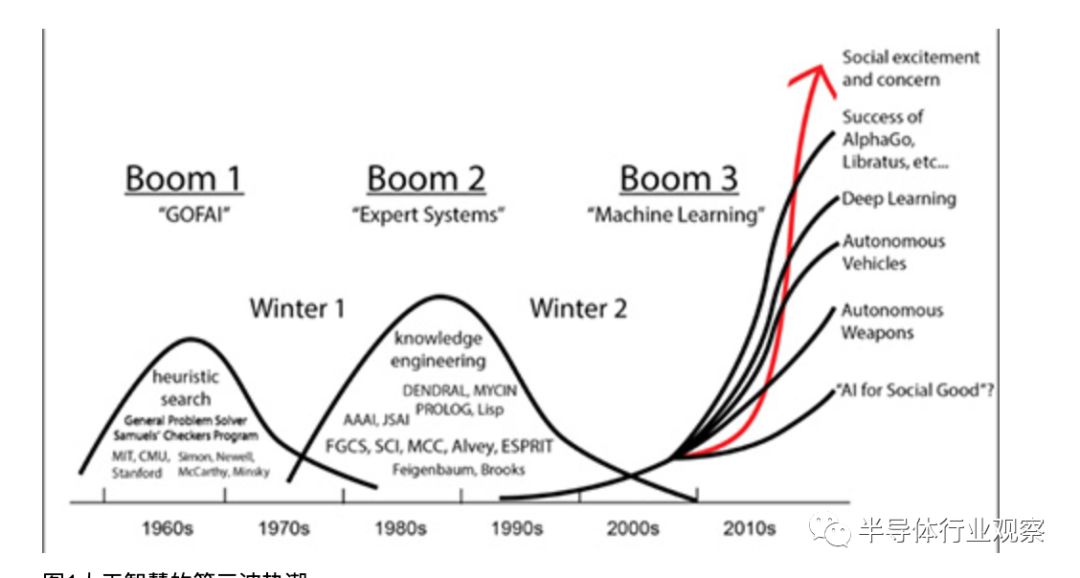
图1人工智能的第三波热潮。
人工智能的运用分成两个阶段,一是学习训练阶段,二是推理阶段,此与应用程序相类似,程序开发阶段即为学习训练阶段,程序正式上线执行运作则为推理阶段。开发即是船舰在船坞内打造或维修,执行则为船舰出海航行作业执勤(图2)。
图2人工智能训练与推理的差别。
训练与推理阶段对运算的要求有所不同,训练阶段需要大量繁复的运算,且为了让人工智能模型获得更佳的参数调整数据,运算的精准细腻度较高,而推理阶段则相反,模型已经训练完成,不再需要庞大运算量,且为了尽快获得推理结果,允许以较低的精度运算。
例如一个猫脸辨识应用,训练阶段要先提供成千上万张各种带有猫脸的照片来训练,并从中抓出各种细腻辨识特点,但真正设置在前端负责辨识来者是否为猫的推理运算,只是辨识单张脸,运算量小,且可能已简化特征,只要简单快速运算即可得到结果(是猫或不是)。
推理专用芯片需求显现
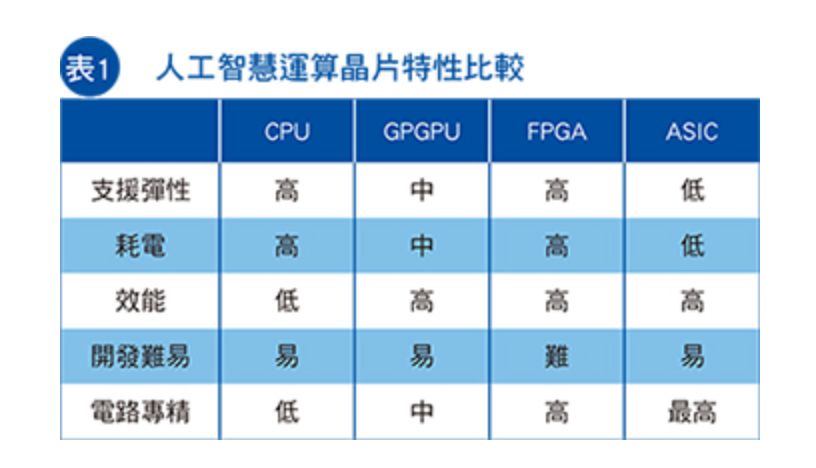
对于人工智能的训练、推理运算,近年来已普遍使用CPU之外的芯片来加速,例如GPGPU、FPGA、ASIC等,特别是GPGPU为多,原因在于GPGPU的高阶软体生态较为完备、可支援多种人工智能框架(Framework),相对的FPGA需要熟悉低阶硬体电路者方能开发,而ASIC通常只针对限定的软体或框架最佳化(表1)。虽然FPGA与ASIC较有难度与限制,但仍有科技大厂愿意投入,如Microsoft即主张用FPGA执行人工智能运算,Google则针对TensorFlow人工智能框架开发ASIC,即Cloud TPU芯片。
人工智能模型的开发(训练)与执行(推理)过往多使用同一芯片,用该芯片执行训练运算后也用该芯片执行推理运算。但近1、2年来随着训练成果逐渐增多,成熟的人工智能模型逐渐普及,以相同芯片负责推理运算的缺点逐渐浮现。以GPGPU而言,芯片内具备大量的平行运算单元是针对游戏绘图、专业绘图或高效能运算而设计,可运算32、64位元浮点数,这在人工智能模型训练阶段亦适用,但到推理阶段,可能只需16位元浮点、16位元整数、8位元整数等运算即可求出推理结果,甚至是4位元整数便足够。如此过往的高精度大量平行运算单元便大材小用,电路与功耗均有所浪费,所以需要人工智能的推理专用处理芯片。
半导体厂纷发展推理芯片
推理芯片的需求在人工智能重新倡议后的2年开始浮现,但在此之前已有若干产品,如2014年Google对外揭露的探戈专案(Project Tango)即使用Movidius公司的Myriad芯片(图3)。
图3 Intel Movidius Myriad X芯片
Movidius之后于2016年推出Myriad 2芯片,同样也在2016年,Intel购并Movidius取得Myriad 1/2系列芯片,并接续推出Myriad X芯片。Google除探戈专案外其他硬体也采用Intel/Movidius芯片,如2017年的Google Clips人工智能摄影机、2018年Google AIY Vision人工智能视觉应用开发套件等。
不过真正受业界瞩目的仍在2018年,包含NVIDIA推出T4芯片(严格而论是已带芯片的加速介面卡)(图4)、Google推出Edge TPU芯片(图5),以及Amazon Web Services在2018年11月宣告将在2019年推出Inferentia芯片,均为推理型芯片。
图4 NVIDIA展示T4介面卡
图5 Google Edge TPU小于一美分铜板。
另外,脸书(Facebook)也已经意识到各形各色的推理型芯片将会在未来几年内纷纷出笼,为了避免硬体的多元分歧使软体支援困难,因此提出Glow编译器构想,期望各人工智能芯片商能一致支援该编译标准,目前Intel、Cadence、Marvell、Qualcomm、Esperanto Technologies(人工智能芯片新创业者)均表态支持。
与此同时,脸书也坦承开发自有人工智能芯片中,并且将与Intel技术合作;目前脸书技术高层已经表示其芯片与Google TPU不相同,但是无法透露更多相关的技术细节。而Intel除了在2016年购并Movidius之外,在同一年也购并了另一家人工智能技术业者Nervana System,Intel也将以Nervana的技术发展推理芯片。
推理芯片不单大厂受吸引投入新创业者也一样积极,Habana Labs在2018年9月对特定客户提供其推理芯片HL-1000的工程样品,后续将以该芯片为基础产制PCIe介面的推理加速卡,代号Goya。Habana Labs宣称HL-1000是目前业界最快速的推理芯片(图6)。
图6 Habana Labs除推出HL-1000推理芯片Goya外也推出训练芯片Gaudi。
云端机房/快速反应推理芯片可分两种取向
透过前述可了解诸多业者均已投入发展推理芯片,然严格而论推理芯片可分成两种取向,一是追求更佳的云端机房效率,另一是更快速即时反应。前者是将推理芯片安置于云端机房,以全职专精方式执行推理运算,与训练、推理双用型的芯片相比,更省机房空间、电能与成本,如NVIDIA T4。
后者则是将推理芯片设置于现场,例如配置于物联网闸道器、门禁摄影机内、车用电脑上,进行即时的影像物件辨识,如Intel Movidius Myriad系列、Google Edge TPU等。
设置于机房内的推理芯片由于可自电源插座取得源源不绝的电能,因此仍有数十瓦用电,如NVIDIA T4的TDP(Thermal Design Power)达70瓦,相对的现场设置的推理芯片必须适应各种环境可能,例如仅以电池供电运作,因此尽可能节约电能,如Google Edge TPU的TDP仅1.8瓦。现场型目前观察仅有车用例外,由于汽车有蓄电瓶可用,电能充沛性居于电池与电源插座间,因此芯片功耗表现可高些。
为能快速反应推理芯片精度须调整
如前所述,推理芯片为能即时快速求解,通常会采较低精度进行运算,过去过于高效能运算的64位元双精度浮点数(Double Precision, DP),或用于游戏与专业绘图的32位元单精度浮点数(Single Precision, SP)可能都不适用,而是降至(含)16位元以下的精度。
例如Intel Movidius Myriad X原生支援16位元浮点数(新称法为半精度Half-Precision, HP)与8位元整数;Google Edge TPU则只支援8位元、16位元整数,未支援浮点数;NVIDIA T4则支援16与32位元浮点数外,也支援8位元与4位元整数。
进一步的,推理芯片可能同时使用两种以上的精度运算,例如NVIDIA T4可同时执行16位元浮点数与32位元浮点数的运算,或者尚未推出的AWS Inferentia宣称将可同时执行8位元整数与16位元浮点数的运算(图7),同时使用两种以上精度的作法亦有新词,称为混精度(Mixed Precision, MP)运算。
图7 AWS预告2019年将推出自家推理芯片Inferentia,将可同时推算整数与幅点数格式。图片来源:AWS
上述不同位元表达长度的整数、浮点数格式,一般写成INT4(Integer)、INT8、FP16、FP32(Float Point)等字样,另也有强调可针对不带正负表达,单纯正整数表达的格式运算,如Habana Labs的HL-1000强调支援INT8/16/32之余,也支援UINT8/16/32格式,U即Unsigned之意。
推理芯片虽然支援多种精度格式,然精度愈高运算效能也会较低,以NVIDIA T4为例,在以INT4格式推算下可以有260 TOPS的效能,亦即每秒有260个Tera(10的12次方)运算,而改以INT8格式时则效能减半,成为130 TOPS,浮点格式也相同,以FP16格式运算的效能为65 TFOPS(F=Float),而以FP32格式运算则降至8.1 TFLOPS,浮点格式的位元数增加一倍效能退至1/8效能,比整数退减程度高。
推理芯片前景仍待观察芯片商须步步为营
推理芯片是一个新市场,重量级芯片业者与新兴芯片商均积极投入发展,但就数个角度而言其后续发展难以乐观,主要是超规模(Hyperscale)云端机房业者自行投入发展。
例如Google在云端使用自行研发的Cloud TPU芯片,针对Google提出的人工智能框架TensorFlow最佳化,如此便限缩了Intel、NVIDIA的机会市场(虽然2019年1月NVIDIA T4已获Google Cloud采用并开放Beta服务)。而Google也在2018年提出针对人工智能框架TensorFlow Lite最佳化的Edge TPU,如此也可能排挤过往已使用的Intel Movidius芯片。
类似的,脸书过去使用NVIDIA Tesla芯片,但随着脸书力主采行PyTorch技术,以及与Intel合作发展人工智能芯片,未来可能减少购置NVIDIA芯片。而Intel与脸书合作开发,也意味着脸书无意购置Intel独立自主发展的人工智能芯片,即便Intel于此合作中获得收益,也比全然销售完整芯片来得少,Intel须在技术上有所让步妥协,或提供客制服务等。
AWS方面也相同,AWS已宣告发展自有推理芯片,此意味着NVIDIA T4的销售机会限缩,其他业者的推理芯片也失去一块大商机。AWS同样有其人工智能技术主张,如MXNet。
如此看来,人工智能芯片的软体技术主导权与芯片大买家,均在超规模机房业者身上,芯片商独立研发、独立供应人工智能芯片的机会将降低,未来迁就超规模机房业者,对其提供技术合作与客制的可能性增高。因此推理芯片会以企业为主要市场,多数企业面对芯片商并无议价能力、技术指导能力,仍会接受芯片商自主研发销售的芯片。
训练/推理两极化
除了推理芯片市场外,人工智能的训练芯片市场也值得观察,由于人工智能应用的开发、训练、参数调整等工作并非时时在进行,通常在历经一段时间的密集开发训练后回归平淡,直到下一次修改调整才再次进入密集运算。类似船只多数时间出海航行,仅少数时间进入船坞整修,或软体多数时间执行,少数时间进行改版修补。
因此,企业若为了人工智能应用的开发训练购置大量的伺服器等运算力,每次训练完成后,大量的伺服器将闲置无用,直到下一次参数调整、密集训练时才能再次显现价值。鉴于此,许多企业倾向将密集训练的运算工作交付给云端服务供应商,依据使用的运算量、运算时间付费,而不是自行购置与维护庞大运算系统,如此训练芯片的大买家也会是云端服务商。
不过企业须要时时运用人工智能的推理运算,如制造业的生产良率检测、医疗业的影像诊断等,部份推理运算不讲究即时推算出结果,亦可抛丢至云端运算,之后再回传运算结果,但追求即时反应者仍须要在前端现场设置推算芯片,此即为一可争取的市场,除了独立的芯片商Intel、NVIDIA积极外,云端业者也在争取此市场,如Google已宣布Edge TPU不仅自用也将对外销售,国内的工控电脑业者已有意配置于物联网闸道器中。
由此看来,人工智能软体技术的标准走向、训练芯片的大宗买家、训练的运算力服务等均为超规模业者,加上推理芯片的自主化,推理与训练的前后整合呼应等,均不利芯片商的发展,芯片商与超规模业者间在未来数年内必须保持亦敌亦友的态势,一方面是大宗芯片的买家,另一方面是技术的指导者、潜在的芯片销售竞争者。
所以,未来的企业将会减少购置训练用的人工智能芯片,并尽可能的使用云端运算力进行短暂且密集的训练;而对于时时与现场营运连结的部份,则会配置推理用芯片,且以即时反应、低功耗的推理芯片为主。至于机房端的推理芯片,仍然会是云端业者为主要采购者,次之为大企业为自有机房而添购,以增进机房运算效率为主。
由上述来看似乎云端服务商占足优势,不过科技持续变化中,目前已有人提出供需两端均分散的作法,即家家户户释出闲置未用的CPU、GPU运算力,汇集成庞大的单一运算力,供有密集训练需求的客户使用。
此作法甚至导入区块链技术,供需双方采代币系统运作,需要运算力者购买数位代币,释出运算力者可获得代币,代币再透过市场交易机制与各地的法定发行货币连结,如此可跳略过云端供应商,一样在短时间获得密集运算力。
不过,完全零散调度型的作法,仍有可能无法即时凑得需求运算力,或因为在全球各地调度运算力,反应速度恐有不及,且发展者多为小型新创业者,现阶段仍难对AWS、Google等大型云端服务商竞争,仅能若干削弱其价值,追求稳定充沛效能者仍以AWS、Google为首选。
面对完全分散化的趋势,国际大型云端业者亦有所因应,例如AWS原即有EC2 Spot Instance服务,对于机房闲置未租出去的运算效能,或有人临时退租退用所释出的效能,能够以折扣方式再卖或转让,类似客机即将起飞,未卖尽的座位票价较低廉,或饭店将入夜的空房折扣租出等,以便减少固定成本的负担。
不过,Spot Instance这类的超折扣机会可遇不可求,或有诸多限制(最高仅能连续运算6个小时),以便维持正规租用者的质感,如此与前述完全分散化的运算调度服务相去不远,均带有较高的不确定性。
-
芯片
+关注
关注
454文章
50676浏览量
423003 -
物联网
+关注
关注
2909文章
44500浏览量
372643 -
AI
+关注
关注
87文章
30636浏览量
268821 -
5G
+关注
关注
1354文章
48418浏览量
563885
原文标题:为什么说AI推理芯片大有可为
文章出处:【微信号:iawbs2016,微信公众号:宽禁带半导体技术创新联盟】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
苏茨克维预测:推理型AI将带来不可预测性
AI推理CPU当道,Arm驱动高效引擎

AMD助力HyperAccel开发全新AI推理服务器

如何基于OrangePi AIpro开发AI推理应用


萨科微总经理宋仕强:华强北贸易商来卖国产品牌大有可为
AMD EPYC处理器:AI推理能力究竟有多强?
不只专攻国内市场,RISC-V芯片出海大有可为
Groq LPU崛起,AI芯片主战场从训练转向推理
这些传感器,大有可为
金航标kinghelm萨科微slkor
AI算法在RZ/V芯片中的移植推理流程





 工商网监
工商网监
评论