 无需权重训练!谷歌再向深度学习炼丹术发起 “攻击”
无需权重训练!谷歌再向深度学习炼丹术发起 “攻击”
神经网络训练中“权重”有多重要不言而喻。但现在,可以把权重抛诸脑后了。谷歌大脑最新研究提出“权重无关神经网络”,通过不再强调权重来搜索网络结构,所搜索的网络无需权重训练即可执行任务!
还在为 “调参炼丹” 感到痛苦吗?是时候重视下神经网络结构了!
前不久,新智元报道了谷歌给出首个神经网络训练理论的证明。这一研究在训练深度神经网络被戏谑为 “调参炼丹” 的当下,犹如一道希望的强光,射进还被排除在 “科学” 之外的深度学习领域,激动人心。
而今天,谷歌再向炼丹术发起 “攻击”:提出一种神经网络结构的搜索方法,该方法无需任何显式的权值训练即可执行任务!

arXiv 地址:
https://arxiv.org/pdf/1906.04358.pdf
这项研究的作者之一David Ha发表 Twitter 表示:
这项研究的关键思想是通过不再强调权重来搜索网络结构。
在搜索过程中,网络每次在 rollout 的时候会分配一个共享的权重值,并进行优化,这就让它能够在很大的权重值范围内良好运行。
这样做的好处就是可以绕过高昂的内部训练循环代价。
这项工作是由 Adam Gaier 所领导的,他在东京的谷歌大脑实习了 3 个月。特别有意思的是,这个研究想法是他在六本木喝了几杯酒之后产生的。
Adam Gaier是一名AI研究员,在教学和研究方面具有广泛的国际经验,在生物启发的计算、机器人和机器学习方面有很强的背景。目前的研究主要集中在机器学习和进化计算的集成上,其目标是将人工智能应用于现实世界的设计和控制问题。
Adam Gaier的经历也颇为神奇,LinkedIn资料显示,他本科在英国里士满美国国际大学读信息系统专业,后又在英国萨塞克斯大学和德国波恩-莱茵-锡格应用技术大学分别获得硕士学位,攻读自主系统专业。
而在2005年本科毕业到2011年再次回到学校的期间,有两年半的时间 Adam Gaier 在北京乌巢餐厅担任餐厅经理、市场及 IT 总监;然后在清华大学国际学校,计算机科学系系主任。2019年1月至今他在谷歌大脑东京部门担任实习研究员。
接下来,新智元带来这篇论文的详细解读:
无需学习权重,“一出生”就很秀的神经网络
在生物学中,早成物种(precocial species)是指那些从出生的那一刻起就具有某些能力的物种。有证据表明,蜥蜴和蛇的幼仔一出生就具备了躲避捕食者的行为,鸭子刚孵化后不久就能自己游泳和进食。相反,我们在训练AI智能体执行任务时,通常要选择一个我们认为适合为任务编码策略的神经网络架构,并使用学习算法找到该策略的权重参数。
在这项工作中,我们受到自然界进化的早成行为的启发,开发了具有自然就能够执行给定任务的架构的神经网络,即使其权重参数是随机采样的。通过使用这样的神经网络架构,AI智能体可以在不需要学习权重参数的情况下在其环境中运行良好。
权重无关神经网络的例子:两足步行者(左),赛车(右)
我们通过不再强调权重(deemphasizing weights)来搜索神经网络架构。在每次rollout,网络都被分配一个单独的共享权重值来代替训练。在很大范围的权重值上为预期性能进行优化的网络结构仍然能执行各种任务,而无需权重训练。
数十年的神经网络研究为各种任务领域提供了具有很强归纳偏差的构建块。卷积网络特别适合于图像处理。例如,Ulyanov等人证明,即使是一个随机初始化的CNN也可以用作图像处理任务(如超分辨率和图像修复)的手工预处理。Schmidhuber等人证明,具有学习线性输出层的随机初始化LSTM可以预测传统RNN失效的时间序列。self-attention和capsule网络的最新发展扩展了构建模块的工具包,用于为各种任务创建具有强烈归纳偏差的架构。
被随机初始化的CNN和LSTM的内在能力所吸引,我们的目标是搜索与权重无关的神经网络(weight agnostic neural networks),这种结构具有很强的归纳偏差,已经可以使用随机权重执行各种任务。
MNIST分类网络演化为使用随机权重
使用随机权重的网络架构不仅易于训练,而且还提供了其他优势。例如,我们可以为同一个网络提供一个(未经训练的)权重集合来提高性能,而不需要显式地训练任何权重参数。
具有随机初始化的传统网络在MNIST上的精度约为10%,但这种随机权重的特殊网络架构在MNIST上的精度(> 80%)明显优于随机初始化网络。在没有进行任何权重训练的情况下,当我们使用一组未经训练的权重时,精度提高到> 90%。
为了寻找具有强归纳偏差的神经网络架构,我们提出通过降低权重的重要性来搜索架构。
具体实现方法是:
(1)为每个网络连接分配一个共享权重参数;
(2)在此单一权重参数的大范围内评估网络。
我们没有优化固定网络的权重,而是优化在各种权重范围内性能良好的网络结构。我们证明了,我们的方法能够产生可以预期用随机权重参数执行各种连续控制任务的网络。
作为概念证明,我们还将搜索方法应用于监督学习领域,发现它可以找到即使没有显式的权重训练也可以在MNIST上获得比chance test准确率高得多(∼92%)的网络。
我们希望对这种权重无关的神经网络的demo将鼓励进一步研究探索新的神经网络构建块,不仅具有有用的归纳偏差,而且还可以使用不一定限于基于梯度的方法的算法来学习。
Demo:
一个执行CartpoleSwingup任务的权重无关神经网络。请点击本文原文链接,拖动滑块控制权重参数,观察不同共享权重参数下的性能。你也可以在这个demo中微调所有连接的各个权重。
关键技术解析:权重无关神经网络搜索
创建编码解决方案的网络架构是一个与神经结构搜索(NAS)所解决的问题完全不同的问题。NAS技术的目标是产生经过训练的架构,其性能优于人类设计的架构。从没有人声称这个解决方案是网络结构固有的。NAS创建的网络“可训练”——但没有人认为这些网络在不训练权重的情况下就能解决任务。权重就是解决方案;所发现的结构仅仅是一个更好的承载权重的基底。
要生成自己编码解决方案的架构,就必须将权重的重要性降到最低。与其用最优权重来判断网络的性能,不如根据随机分布的权重来衡量网络的性能。用权重采样代替权重训练可以确保性能仅是网络拓扑结构的产品。
不幸的是,由于高维数,除了最简单的网络外,可靠第对权重空间进行采样是不可行的。虽然维数灾难(curse of dimensionality)阻碍了我们有效地采样高维权重空间,但是通过强制所有权重共享(weight-sharing),权重值的数量被减少到一个。系统地对单个权重值进行采样是直接且高效的,这使我们能够在少数试验中近似网络性能,然后可以使用这种近似来驱动搜索更好的架构。
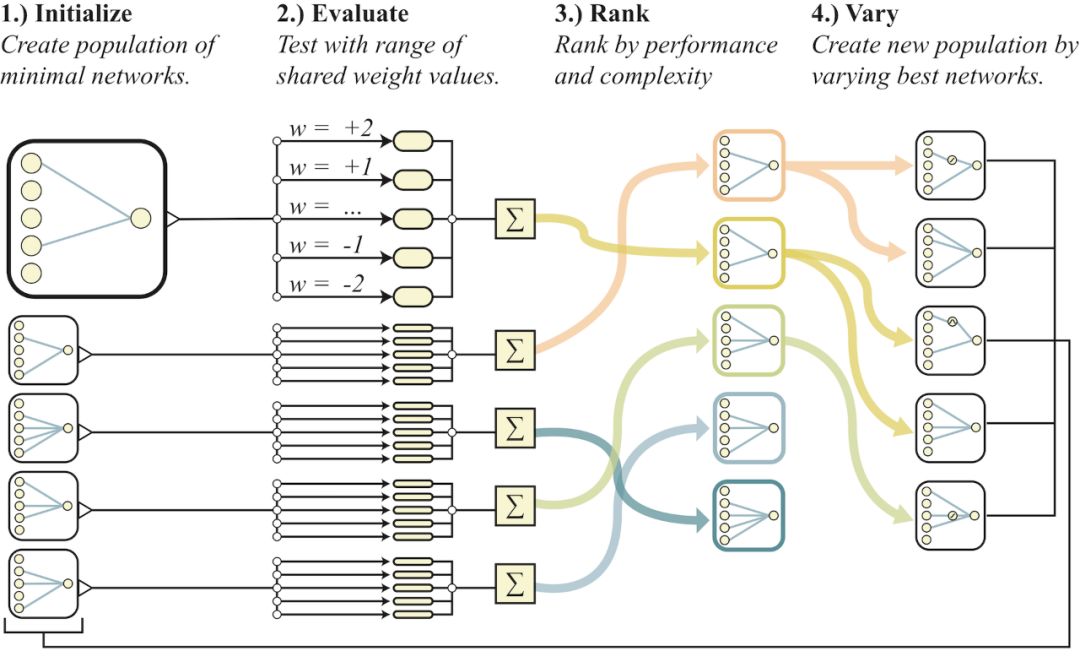
权重无关的神经网络搜索概述
在探索神经网络拓扑空间时,权值无关的神经网络搜索避免了权重训练,方法是在每次rollout时采样一个共享的权值。网络将通过多次rollout进行评估。在每次rollout,都会为单个共享权重分配一个值,并记录试验期间的累计奖励。然后根据网络的性能和复杂度对网络群体进行排序。然后,概率性地选择排名最高的网络,并随机变化以形成新的群体,然后重复这个过程。
搜索权重无关神经网络(weight agnostic neural networks, WANNs)的过程可以概况如下(见上图):
创建最小神经网络拓扑的初始群体(population)。
通过多个rollout评估每个网络,每个rollout分配一个不同的共享权重值。
根据网络的性能和复杂度对其进行排名。
通过改变排名最高的网络拓扑结构来创建新的population。
然后,算法从(2)开始重复,生成复杂度逐渐增加的与权重无关的拓扑结构,这些拓扑结构在连续的几代中表现得更好。
拓扑搜索(Topology Search)
用于神经网络拓扑搜索的运算符(operators)受到神经进化算法NEAT的启发。在NEAT中,拓扑和权重值同时优化,这里我们忽略了权重值,只应用拓扑搜索运算符。
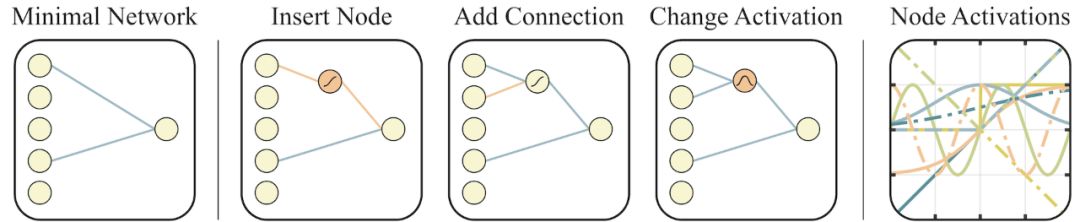
用于搜索网络拓扑空间的运算符
左:一个最小的网络拓扑结构,输入和输出仅部分连接。
中间:网络以三种方式进行改变:
(1)插入节点:通过拆分现有连接插入新节点。
(2)添加连接:通过连接两个以前未连接的节点来添加一个新连接。
(3)变更激活:重新分配隐藏节点的激活函数。
右:在[2, 2]范围内可能的激活函数(线性、阶跃、正弦、余弦、高斯、tanh、sigmoid、inverse、绝对值、ReLU)。
实验设置与结果
对连续控制权重无关神经网络(WANN)的评估在三个连续控制任务上进行。
第一个任务:CartPoleSwingUp,这是一个典型的控制问题,在给定的推车连杆系统下,杆必须从静止位置摆动到直立位置然后平衡,而推车不会越过轨道的边界。这个问题无法用线性控制器解决。每个时间步长上的奖励都是基于推车与轨道边缘的距离和杆的角度决定的。
第二个任务是BipedalWalker-v2 ,目的是引导一个双腿智能体跨越随机生成的地形。奖励是针对成功行进距离,以及电动机扭矩的成本确定。每条腿都由髋关节和膝关节控制,响应24个输入。与低维的CartPoleSwingUp任务相比,BipedalWalker-v2的可能连接数更多更复杂,WANN需要选择输入到输出的路线。
第三个任务CarRacing-v0是一个从像素环境中自上而下行驶的赛车问题。赛车由三个连续命令(点火,转向,制动)控制,任务目标是在一定时限内行驶过尽量长的随机生成的道路。我们将任务的像素解释元素交给经过预训练的变分自动编码器(VAE),后者将像素表示压缩为16个潜在维度,将这些信息作为网络的输入。这个任务测试了WANN学习抽象关联的能力,而不是编码输入之间的显式几何关系。
在实验中,我们比较了以下4种情况下100次试验的平均表现:
1.随机权重:从μ(-2,2)范围内抽取的单个权重。
2.随机共享权重:从μ(- 2,2)范围内中抽取的单个共享权重。
3.调整共享权重:在μ(-2,2)范围内表现最好的共享权重值。
4.调整权重:使用基于人口信息的强化调整的个体权重。
连续控制任务的随机抽样和训练权重的性能
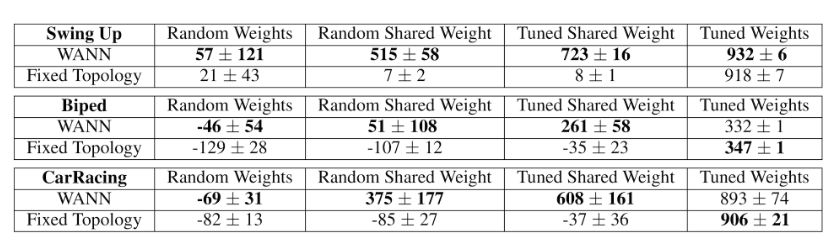
我们比较了过往研究中常用的标准前馈网络的最佳权重无关网络架构的平均性能(测试次数超过100次)。通过均匀分布采样的共享权重来测量其性能,从结果中可以观察到网络拓扑的固有偏差。通过调整此共享权重参数,可以测出其最佳性能。为了便于与基线架构进行比较,允许网络获得独特的权重参数,并对其进行调整。
结果如上表所示,作为基线的传统固定拓扑网络在经过大量调整后只产生有用行为,相比之下,WANN甚至可以使用随机共享权重。虽然WANN架构编码强烈偏向解决方案,但并不完全独立于权重值,当单个权重值随机分配时,模型就会失败。WANN通过编码输入和输出之间的关系来起作用,因此,虽然权重大小并不重要,但它们的一致性,特别是符号的一致性,是非常重要的。单个共享权重的另一个好处是,调整单个参数变得非常容易,无需使用基于梯度的方法。
表现最佳的共享权重值会产生令人满意的行为:连杆系统在几次摆动之后即获得平衡,智能体沿道路有效行进,赛车实现高速过弯。这些基本行为完全在网络架构内编码。虽然WANN能够在未经训练的情况下使用,但这并不能妨碍其在训练权重后达到类似的最佳性能。
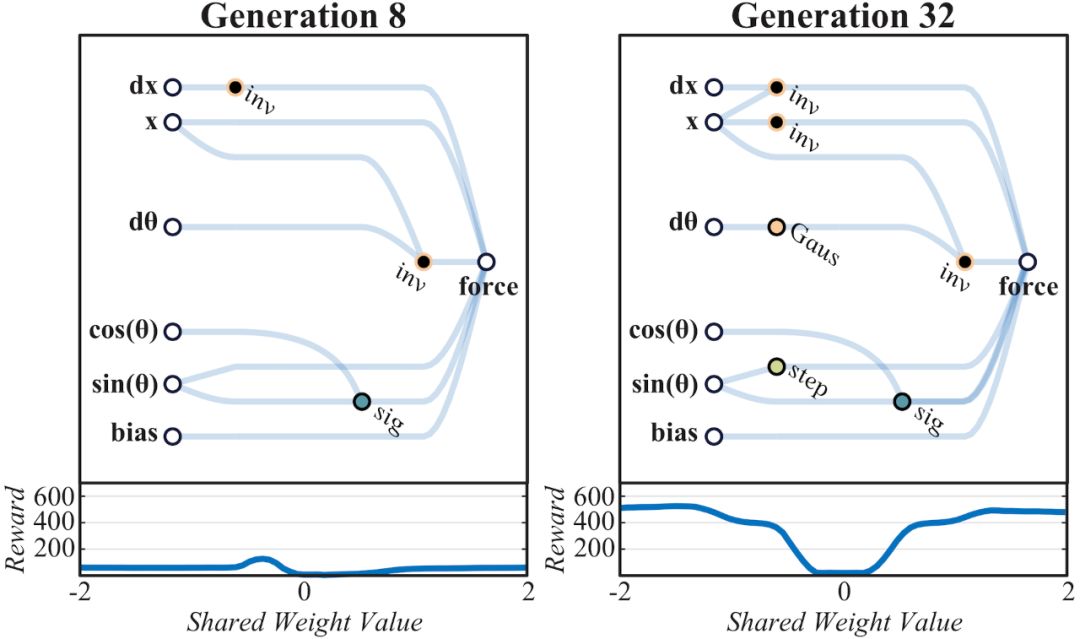
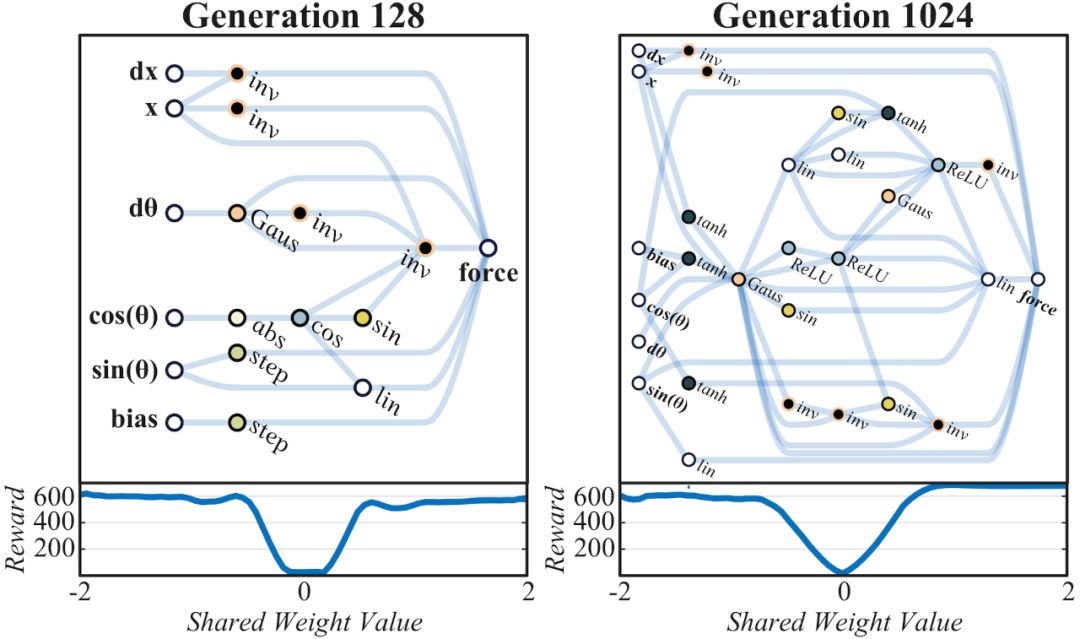
由于网络规模小到可以解释,我们可以通过查看网络图来了解其运行机制(见上图)。解决“杆车实验”的WANN网络开发过程就体现了在网络架构内对关系的编码方式。在早期时代的网络空间中,不可避免的需要使用随机探索的方式。
网络在第32代时形成初步架构,能够支持比较一致的任务表现,在轨道某某位置的逆变器可以防止小车冲出轨道,轨道中间为0点,左边为负,右边为正。在小车处于负区域时对其施加正方向作用力,反之亦然,网络通过编码在轨道中间设置一个强力牵引器。最终经调整权重,在1024代达成最佳性能。
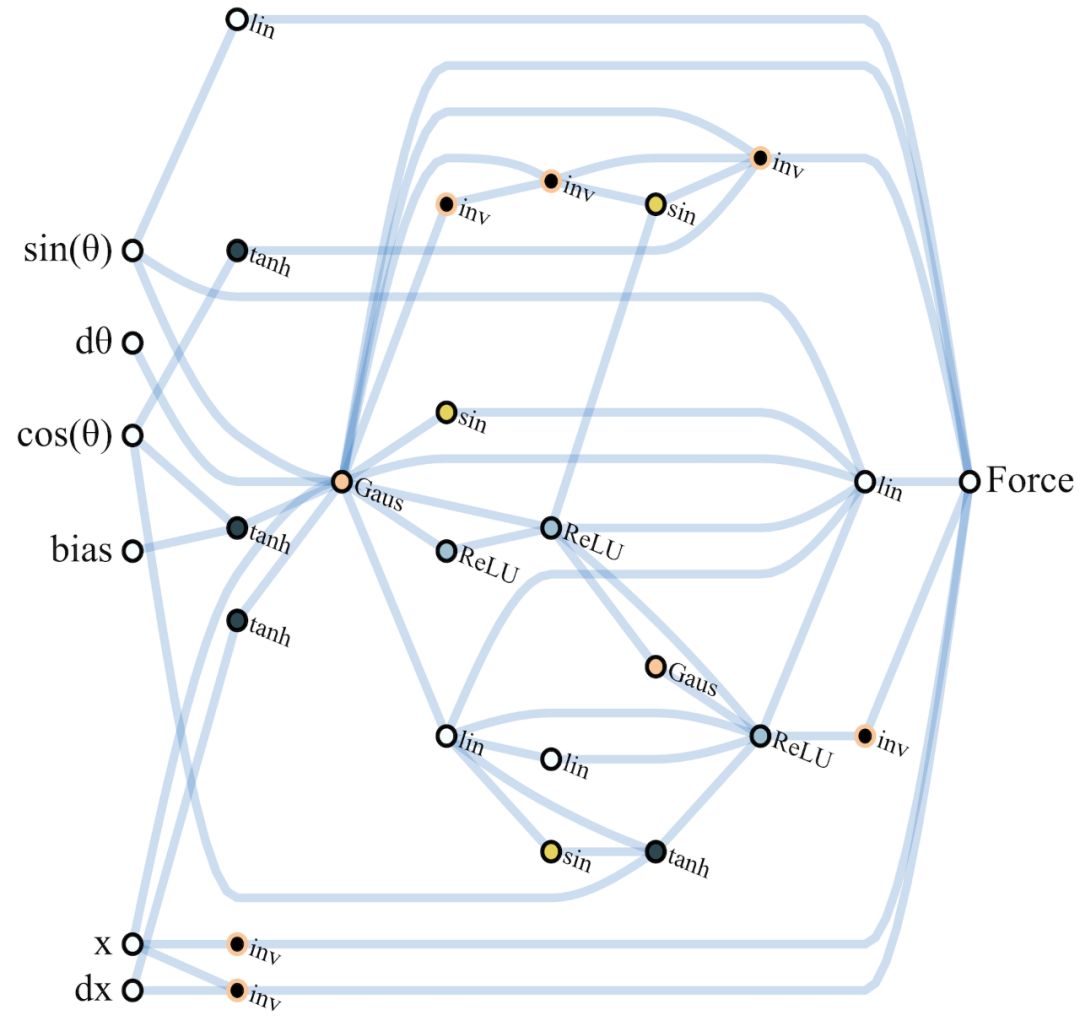
第1024代最佳性能的CartPoleSwingUp任务WANN网络示意图
我们可以使用最佳共享权重作为起点,由共享权重参数得到偏移量,轻松训练网络的每个单独的权重连接。可以使用基于人口信息的强化对权重进行微调,但原则上可以使用任何其他学习算法。
为了在训练分布之外可视化智能体的性能,可以使用比原始设置更多更杂初始条件。
随着搜索过程的继续,有些控制器能够在直立位置保持更长时间,到第128代时,这个保持时间已经长到能够让杆保持平衡。虽然在可变权重条件下,这种更复杂的平衡机制在可靠性上低于摆动和居中行为,但更可靠的行为可以确保系统恢复,并再次尝试直到找到新的平衡状态。值得注意的是,由于这些网络对关系进行编码,并依赖于相互设置的系统之间的张力,因此网络的行为与广泛的共享权重值保持一致。
在BipedalWalker-v2和CarRacing-v0任务中,WANN网络控制器在简单性和模块性方面的表现同样出色。前者仅使用了25种可能输入中的17种,忽略了许多LIDAR传感器信息和膝盖运动速度数据。 WANN架构不仅可以在未训练单个权重的情况下完成任务,而且仅使用了210个连接,比常用拓扑网络架构(SOTA基线方法中使用了2804个连接)低一个数量级。
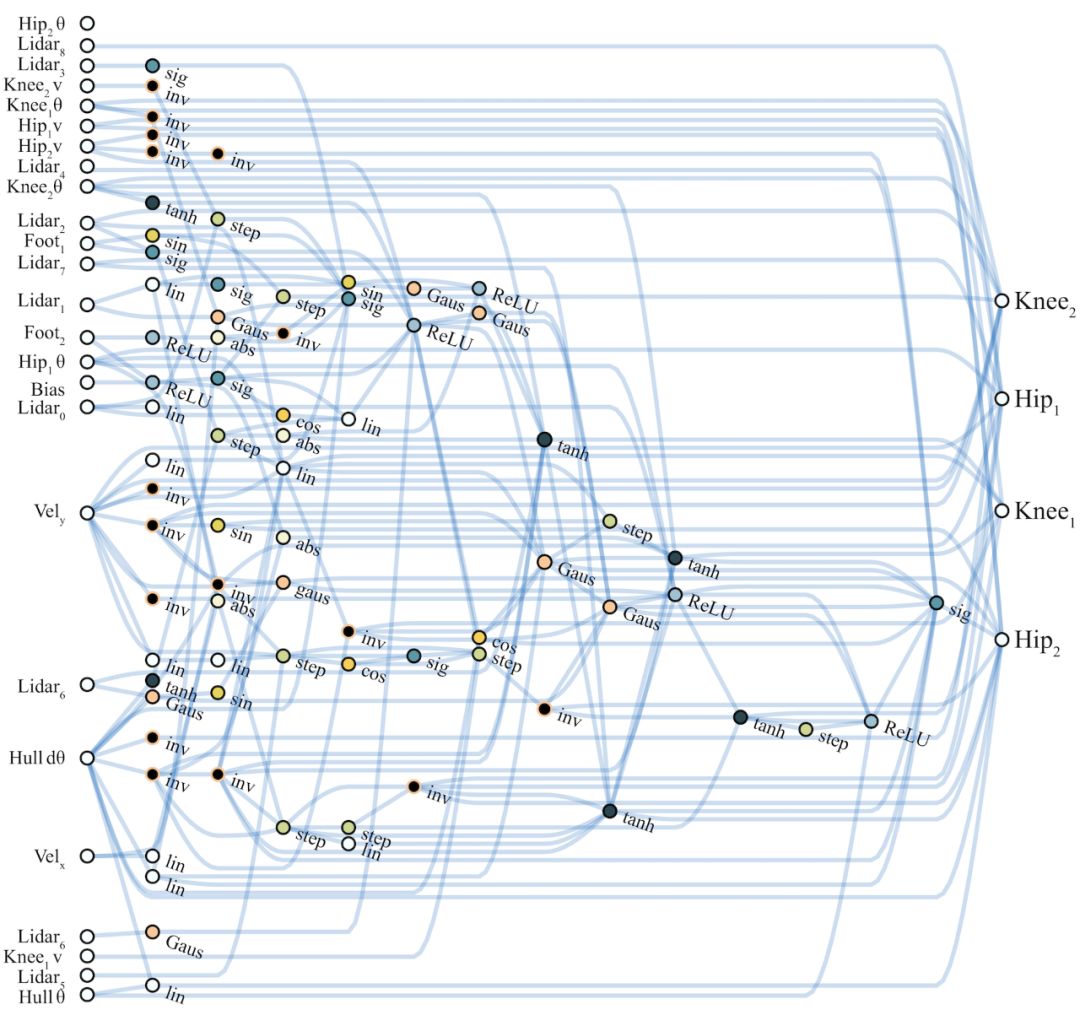
BipedalWalker任务最佳性能网络示意图
权重设置-1.5
权重设置-1.0
性能最优的网络
在赛车任务实验中,WANN架构简单的优势也很突出。只需要稀疏连接的双层网络和单个权重值,就能编码合格的驾驶行为。虽然SOTA基线方法也给出了预训练RNN模型的隐藏状态,但除了VAE对其控制器的表示外,我们的控制器仅在VAE的潜在空间上运行。尽管如此,WANN还是能够开发出一种前馈控制器,可以获得性能相当的分数。未来我们将探索如何从搜索中去掉前馈约束,让WANN开发出与内存状态相关的循环连接。
权重设置+1.0
权重设置-1.4
性能最优的网络
WANN的应用扩展:探索图像分类任务
在强化学习任务中取得的好成绩让我们考虑扩大WANN的应用范围。对输入信号之间的关系进行编码的WANN非常适合强化学习任务。不过,分类问题远没有这么模糊,性能要求也要严格得多。与强化学习不同,分类任务中的架构设计一直是人们关注的焦点。为了验证概念,我们研究了WANN在MNIST数据集上的表现,MNIST一个图像分类任务,多年来一直是分类任务架构设计的关注焦点。
WANN在4种权重设定下在MNIST图像数据集上的分类表现,WANN的分类精度用多个权重值作为集合进行实例化,其性能远远优于随机采样权重
即使在高维分类任务中,WANN的表现也非常出色。 只使用单个权重值,WANN就能够对MNIST上的数字以及具有通过梯度下降训练的数千个权重的单层神经网络进行分类,产生的架构灵活性很高,仍然可以继续进行权重,进一步提高准确性。
按权重计算的数字精度
直接对权重范围进行全部扫描,当然可以找到在训练集上表现最佳的权重值,但WANN的结构提供了另一个有趣的方式。在每个权重值处,WANN的预测是不同的。在MNIST上,可以看出每个数字的精度是不一样的。可以将网络的每个权重值视为不同的分类器,这样可能使用具有多个权重值的单个WANN,作为“自包含集合”。
MNIST分类器。并非所有神经元和连接都用于预测每个数字
将具有一系列权重值的WANN进行实例化来创建网络集合是最简单的方法之一。集合中的每个网络给与一票,根据得票最多的类别对样本进行分类。这种方法产生的预测结果远比随机选择的权重值更准确,而且仅仅比最佳权重值稍差。今后在执行预测或搜索网络架构任务时可以不断尝试更复杂的技术。
-
谷歌
+关注
关注
27文章
6153浏览量
105244 -
神经网络
+关注
关注
42文章
4767浏览量
100663 -
深度学习
+关注
关注
73文章
5497浏览量
121068
原文标题:告别深度学习炼丹术!谷歌大脑提出“权重无关”神经网络
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

AI大模型与深度学习的关系
深度学习中的无监督学习方法综述
深度学习与nlp的区别在哪
深度学习中的模型权重
深度学习的典型模型和训练过程
FPGA在深度学习应用中或将取代GPU
谷歌模型训练软件有哪些功能和作用
如何优化深度学习模型?
如何基于深度学习模型训练实现工件切割点位置预测

如何基于深度学习模型训练实现圆检测与圆心位置预测






 工商网监
工商网监
评论