 ICML 2019最佳论文新鲜出炉!
ICML 2019最佳论文新鲜出炉!
今日,国际机器学习顶会ICML公布2019年最佳论文奖:来自苏黎世联邦理工大学、谷歌大脑等的团队和英国剑桥大学团队获此殊荣。另外,大会还公布了7篇获最佳论文提名的论文。
ICML 2019最佳论文新鲜出炉!
今日,国际机器学习顶会ICML 2019于美国长滩市公布了本届大会最佳论文结果:
本届ICML两篇最佳论文分别是:
《挑战无监督解耦表示中的常见假设》,来自苏黎世联邦理工学院(ETH Zurich)、MaxPlanck 智能系统研究所及谷歌大脑;
《稀疏高斯过程回归变分的收敛速度》,来自英国剑桥大学。
除此之外,大会还公布了七篇获得提名奖(Honorable Mentions)论文。
据了解,今年ICML共提交3424篇论文,其中录取774篇,论文录取率为22.6%。录取率较去年ICML 2018的25%有所降低。
论文录取结果地址:
https://icml.cc/Conferences/2019/AcceptedPapersInitial?fbclid=IwAR0zqRJfPz2UP7dCbZ8Jcy7MrsedhasX13ueqkKl934EsksuSj3J2QrrRAQ
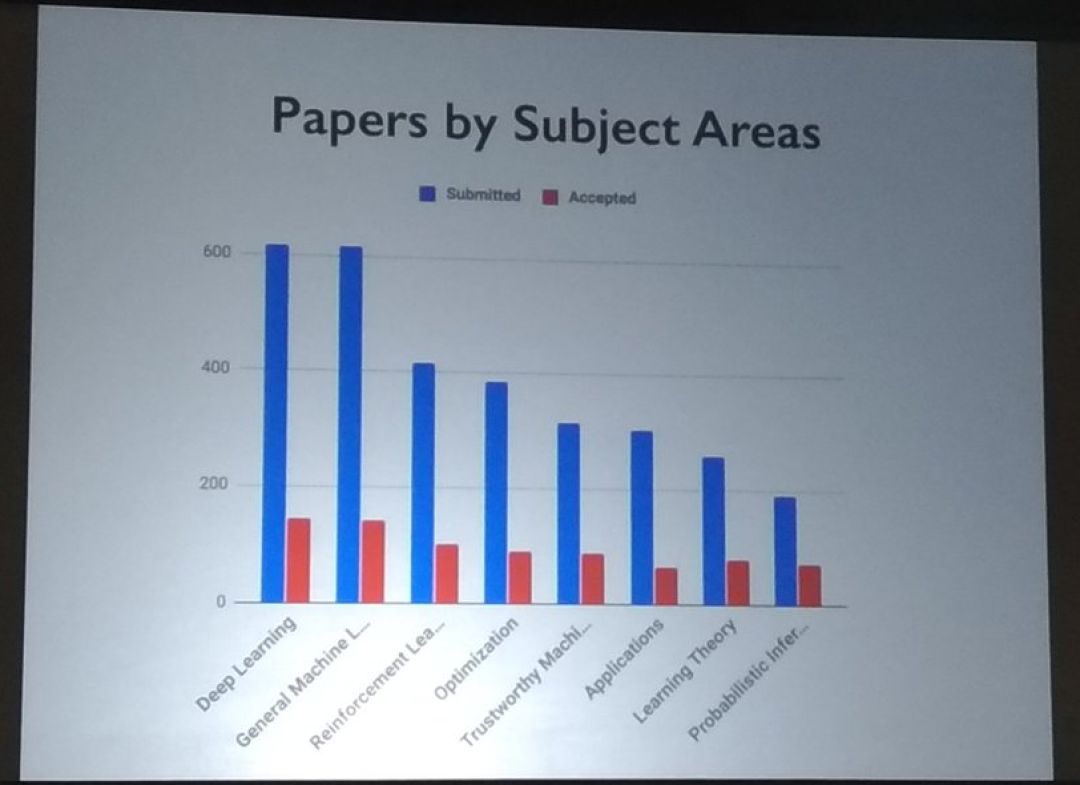
提交论文最多的子领域分别是:深度学习、通用机器学习、强化学习、优化等
最佳论文:大规模深入研究无监督解耦表示
第一篇最佳论文的作者来自苏黎世联邦理工学院(ETH Zurich)、MaxPlanck 智能系统研究所及谷歌大脑。
论文标题:挑战无监督解耦表示中的常见假设
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
作者:Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar Rätsch, Sylvain Gelly, Bernhard Schölkopf, Olivier Bachem
论文地址:
http://proceedings.mlr.press/v97/locatello19a/locatello19a.pdf
这是一篇大规模深入研究无监督解耦表示(Disentangled Representation)的论文,对近年来绝大多数的非监督解耦表示方法进行了探索、利用 2.5GPU 年的算力在 7 个数据集上训练了 12000 多个模型。基于大规模的实验结果,研究人员对这一领域的一些假设产生了质疑,并为解耦学习的未来发展方向给出了建议。此外,研究人员还同时发布了研究中所使用的代码和上万个预训练模型,并封装了 disentanglement_lib供研究者进行实验复现和更深入的探索。
论文摘要
无监督学习解耦表示背后的关键思想是,真实世界数据是由一些变量的解释因子生成的,这些因子可以通过无监督学习算法恢复。在本文中,我们认真回顾了该领域的最新进展,并对一些常见假设提出挑战。
我们首先从理论上证明,如果没有对模型和数据的归纳偏置,解耦表示的无监督学习基本上是不可能的。然后,我们在7个不同数据集上训练了超过12000个模型,涵盖了最重要的方法和评估指标,进行了可重复的大规模实验研究。
我们观察到,虽然不同的方法都成功地执行了相应损失“鼓励”的属性,但如果没有监督,似乎无法识别出良好解耦的模型。此外,增加解耦似乎不会降低下游任务学习的样本复杂度。
我们的研究结果表明,未来关于解耦学习的工作应该明确归纳偏见和(隐式)监督的作用,研究强制解耦学习表示的具体好处,并考虑覆盖多个数据集的可重复的实验设置。
本文从理论和实践两方面对这一领域中普遍存在的一些假设提出了挑战。本研究的主要贡献可概括如下:
我们在理论上证明,如果没有对所考虑的学习方法和数据集产生归纳偏置,那么解耦表示的无监督学习基本上是不可能的。
我们在一项可重复的大规模实验研究中研究了当前的方法及其归纳偏置,该研究采用了完善的无监督解耦学习实验方案。我们实现了六种最新的无监督解耦学习方法以及六种从头开始的解耦方法,并在七个数据集上训练了超过12000个模型。
我们发布了disentanglement_lib,这是一个用于训练和评估解耦表示的新库。由于复制我们的结果需要大量的计算工作,我们还发布了超过10000个预训练的模型,可以作为未来研究的基线。
我们分析实验结果,并挑战了无监督解耦学习中的一些共识:
(i)虽然所有考虑的方法都证明有效确保聚合后验的各个维度不相关,我们观察到的表示维度是相关的
(ii)由于random seeds和超参数似乎比模型选择更重要,我们没有发现任何证据表明所考虑的模型可以用于以无监督的方式可靠地学习解耦表示。此外,如果不访问ground-truth标签,即使允许跨数据集传输良好的超参数值,似乎也无法识别良好训练的模型。
(iii)对于所考虑的模型和数据集,我们无法验证以下假设,即解耦对于下游任务是有用的,例如通过降低学习的样本复杂性。
基于这些实证证据,我们提出了进一步研究的三个关键领域:
(i)归纳偏置的作用以及隐性和显性监督应该明确:无监督模型选择仍然是一个关键问题。
(ii) 应证明强制执行学习表示的特定解耦概念的具体实际好处。
(iii) 实验应在不同难度的数据集上建立可重复的实验设置。
最佳论文:稀疏高斯过程回归变分的收敛速度
第二篇最佳论文来自英国剑桥大学。
论文标题:《稀疏高斯过程回归变分的收敛速度》
Rates of Convergence for Sparse Variational Gaussian Process Regression
作者:DavidR. Burt1,Carl E. Rasmussen1,Mark van der Wilk2
arXiv地址:
https://arxiv.org/pdf/1903.03571.pdf
论文摘要
自从许多研究人提出了对高斯过程后验的变分近似法后,避免了数据集大小为N时O(N3)的缩放。它们将计算成本降低到O(NM2),其中M≤N是诱导变量的数量。虽然N的计算成本似乎是线性的,但算法的真正复杂性取决于M如何增加以确保一定的近似质量。
研究人员通过描述KL向后发散的上界行为来解决这个问题。证明了在高概率下,M的增长速度比N慢, KL的发散度可以任意地减小。
一个特别有趣的例子是,对于具有D维度的正态分布输入的回归,使用流行的 Squared Exponential核M就足够了。研究结果表明,随着数据集的增长,高斯过程后验可以真正近似地逼近,并为如何在连续学习场景中增加M提供了具体的规则。
总结
研究人员证明了稀疏GP回归变分近似到后验变分近似的KL发散的界限,该界限仅依赖于先验核的协方差算子的特征值的衰减。
这些边界证明了直观的结果,平滑的核、训练数据集中在一个小区域,允许高质量、非常稀疏的近似。这些边界证明了用M≤N进行真正稀疏的非参数推理仍然可以提供可靠的边际似然估计和点后验估计。
对非共轭概率模型的扩展,是未来研究的一个有前景的方向。
DeepMind、牛津、MIT等7篇最佳论文提名
除了最佳论文外,本次大会还公布了7篇获得荣誉奖的论文。

Analogies Explained: Towards Understanding Word Embeddings
作者:CarlAllen1,Timothy Hospedales1,来自爱丁堡大学。
论文地址:https://arxiv.org/pdf/1901.09813.pdf
SATNet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver
作者:Po-WeiWang1,Priya L. Donti1 2,Bryan Wilder3,Zico Kolter1 4,分别来自卡耐基梅隆大学、南加州大学、Bosch Center for Artificial Intelligence。
论文地址:https://arxiv.org/pdf/1905.12149.pdf
A Tail-Index Analysis of Stochastic Gradient Noise in Deep Neural Networks
作者:UmutŞimşekli∗,L, event Sagun†, Mert Gürbüzbalaban‡,分别来自巴黎萨克雷大学、洛桑埃尔科尔理工大学、罗格斯大学。
论文地址:https://arxiv.org/pdf/1901.06053.pdf
Towards A Unified Analysis of Random Fourier Features
作者:Zhu Li,Jean-François Ton,Dino Oglic,Dino Sejdinovic,分别来自牛津大学、伦敦国王学院。
论文地址:https://arxiv.org/pdf/1806.09178.pdf
Amortized Monte Carlo Integration
作者:Adam Golinski、Yee Whye Teh、Frank Wood、Tom Rainforth,分别来自牛津大学和英属哥伦比亚大学。
论文地址:http://www.gatsby.ucl.ac.uk/~balaji/udl-camera-ready/UDL-12.pdf
Social Influence as Intrinsic Motivation for Multi-Agent Deep Reinforcement Learning
作者:Natasha Jaques, Angeliki Lazaridou, Edward Hughes, Caglar Gulcehre, Pedro A. Ortega, DJ Strouse, Joel Z. Leibo, Nando de Freitas,分别来自MIT媒体实验室、DeepMind和普林斯顿大学。
论文地址:https://arxiv.org/pdf/1810.08647.pdf
Stochastic Beams and Where to Find Them: The Gumbel-Top-k Trick for Sampling Sequences Without Replacement
作者:Wouter Kool, Herke van Hoof, Max Welling,分别来自荷兰阿姆斯特丹大学,荷兰ORTEC和加拿大高等研究所(CIFAR)。
论文地址:https://arxiv.org/pdf/1903.06059.pdf
ICML 2019:谷歌成为最大赢家,清北、南大港中文榜上有名
本次大会还统计了收录论文的领域分布情况:
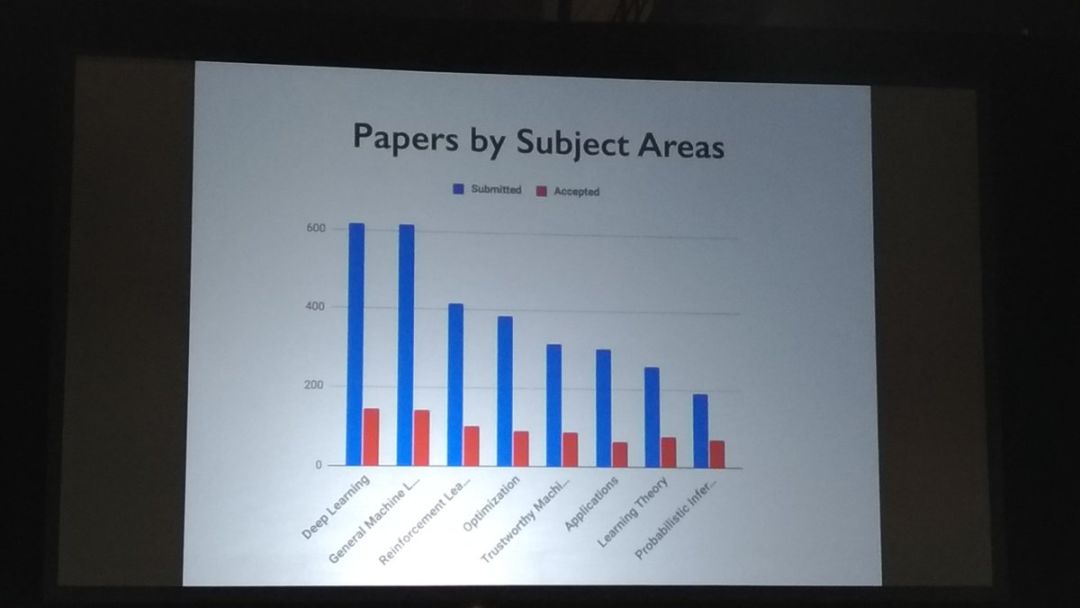
提交论文最多的子领域分别是:深度学习、通用机器学习、强化学习、优化等。
而早在上个月,Reddit网友就发表了他和他的公司对本次ICML 2019论文录取情况的统计结果。
地址:
https://www.reddit.com/r/MachineLearning/comments/bn82ze/n_icml_2019_accepted_paper_stats/
今年,在所有录取的论文中,谷歌无疑成为了最大赢家。
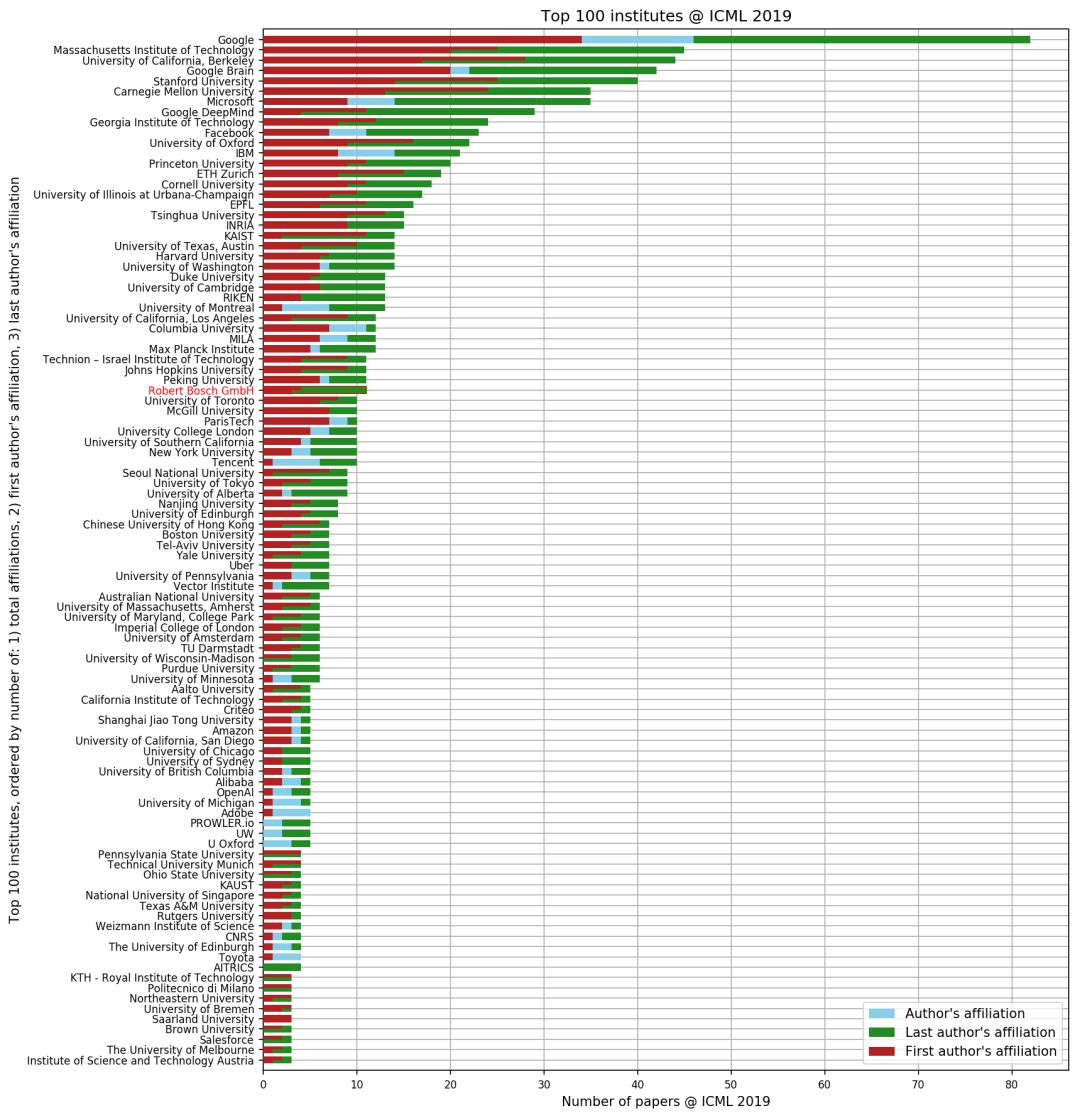
录取论文总数排名(按研究所)
上表显示了以研究所(包括产业界和学术界)为单位,录取论文总数的排名。这项统计中至少有一位作者隶属于某研究所,因此一篇论文可以出现多次且隶属多个研究所。
排名地址:
https://i.redd.it/wdbw91yheix21.png
其中,蓝色代表论文总数,绿色和红色分别代表第一作者和通讯作者参与录取论文的论文数量。并且,附属机构是手动合并到研究所的,例如Google Inc.、Google AI、Google UK都将映射到Google。
可以看到谷歌录取论文的数量远超其它研究所,位列第一;紧随其后的是MIT、伯克利、谷歌大脑、斯坦福、卡内基梅隆以及微软。
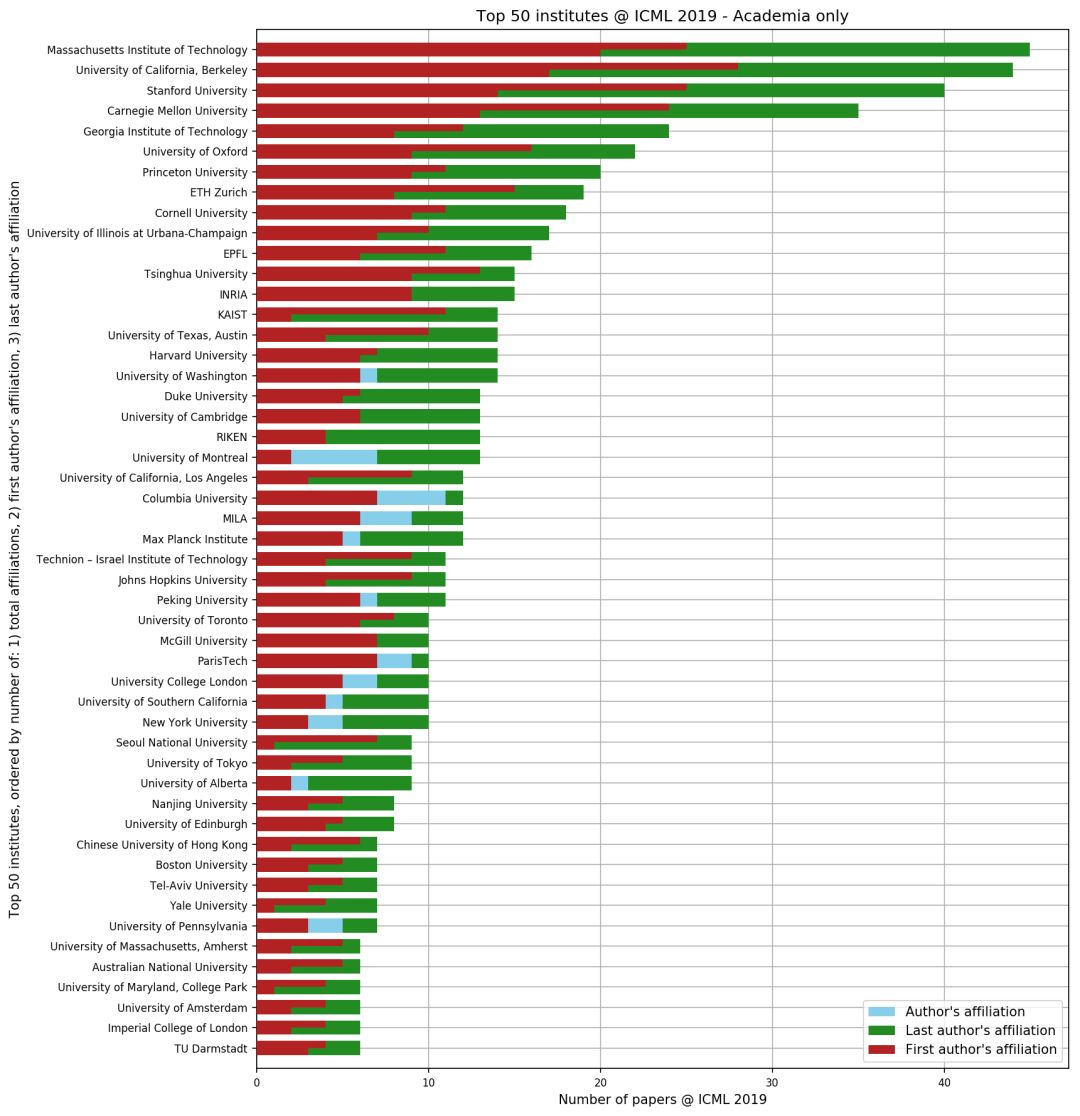
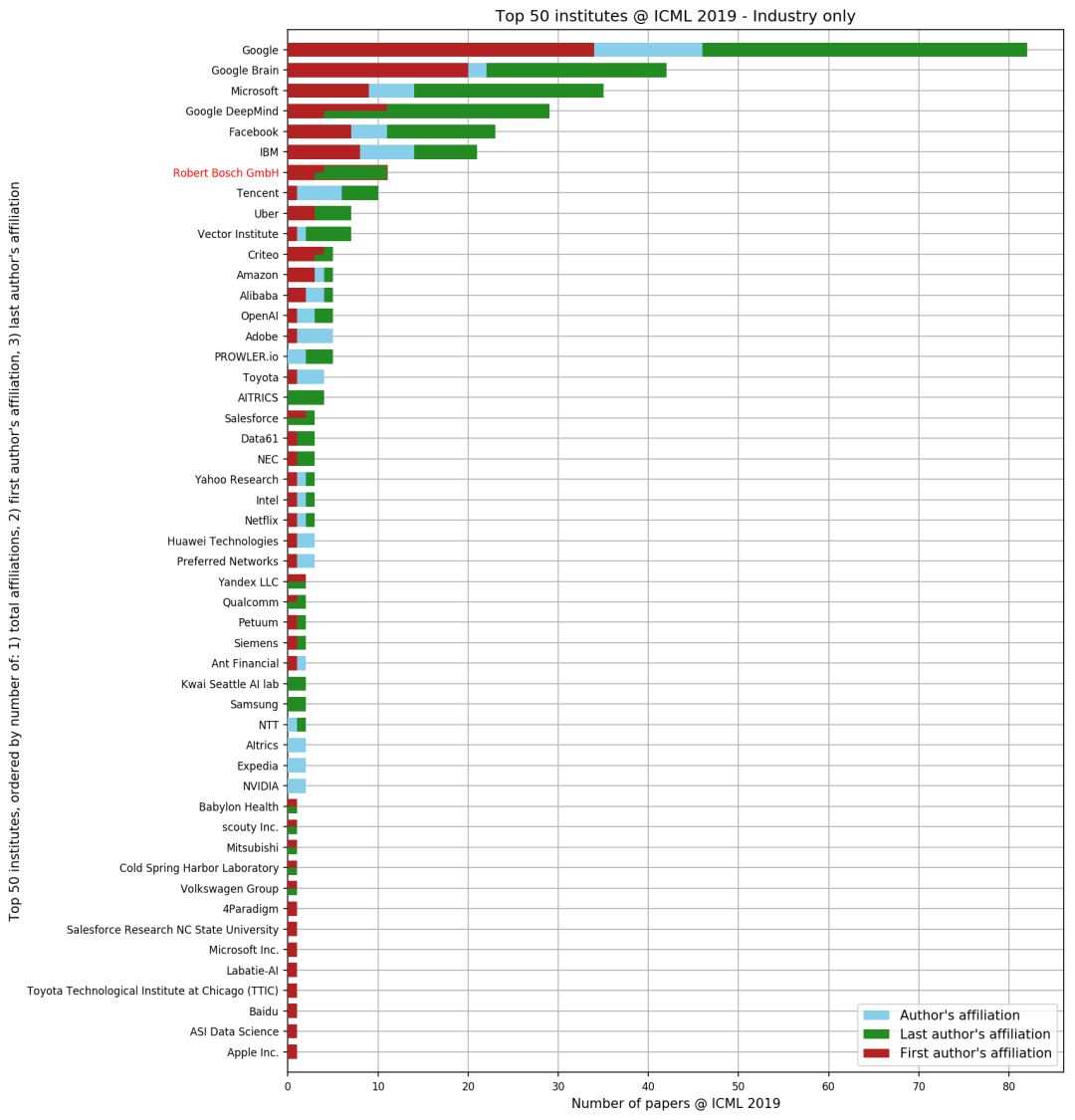
作者还分别根据学界和产业界进行了统计Top 50排名。
排名统计可视化地址:
https://i.redd.it/37hxhsmfzix21.png
在学界排名中,MIT、加州伯克利分校、斯坦福和卡内基梅隆夺冠前四,成为本届录取论文数的第一梯队,且与第二梯队拉开了一定差距。
国内上榜的院校包括清华大学、北京大学、南京大学、香港中文大学。
排名可视化地址:
https://i.redd.it/wa6kjzmhzix21.png
在企业研究所Top 50排名中,谷歌无疑成为最大赢家:谷歌、谷歌大脑和谷歌DeepMind分别取得第一、第二和第四的好成绩。微软、Facebook和IBM成绩也较优异,位居第三、第五和第六。
而对于国内企业,腾讯(Tencent)成绩较好,位居第八名。
此外,从本届ICML 2019录取论文情况来看,还可以得到如下统计:
452篇论文(58.4%)纯属学术研究;
60篇论文(7.8%)来自工业研究机构;
262篇论文(33.9%)作者隶属于学术界和工业界。
总结上述的统计,我们可以得到如下结果:
77%的贡献来自学术界;
23%的贡献来自产业界。
-
智能系统
+关注
关注
2文章
399浏览量
72662 -
机器学习
+关注
关注
66文章
8453浏览量
133166 -
论文
+关注
关注
1文章
103浏览量
14977
原文标题:ICML 2019最佳论文出炉,超高数学难度!ETH、谷歌、剑桥分获大奖
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
华邦电子安全闪存关键知识点
[求职] RK3588核心板,寻找志同道合的电子发烧友!
安波福再获“全球最佳企业”与“最佳管理企业”
比亚迪获评AUTOBEST 2025年度最佳企业
安波福苏州荣获“2024大苏州最佳雇主”及“2024最佳HR团队奖”
中科驭数联合处理器芯片全国重点实验室获得“CCF芯片大会最佳论文奖”
Samtec在2024慕尼黑上海电子展精彩回顾

格灵深瞳名列「智慧校园体育品牌影响力综合评价」榜首

2024年汽车软件开发状况调查结果出炉:软件研发人员必看

智能家居议程新鲜出炉!报名最后倒计时!

基于高光谱成像的蔬菜新鲜度检测






 工商网监
工商网监
评论