 真正的神经网络到底要不要学习权重
真正的神经网络到底要不要学习权重
难道神经网络不用学权重也能完成各种任务?难道我们以为 CNN 学习到的图像特征只是我们以为?神经网络只不过是函数的排列组合,没有其它意义?从这篇论文来看,这些答案似乎都是肯定的。
昨天,谷歌大脑 David Ha 等人一篇名为《Weight Agnostic Neural Networks》的论文引爆了机器学习圈。其「颠覆性」的理论让人惊呼:「到头来我们对神经网络一无所知?」
Reddit 上有一些研究者认为,《Weight Agnostic Neural Networks》这篇论文更有趣的意义在于,它也宣告了深度学习分层编码特征这一解释寿终正寝。
通常情况下,权重被认为会被训练成 MNIST 中边角、圆弧这类直观特征,而如果论文中的算法可以处理 MNIST,那么它们就不是特征,而是函数序列/组合。对于 AI 可解释性来说,这可能是一个打击。
很容易理解,神经网络架构并非「生而平等」,对于特定任务一些网络架构的性能显著优于其他模型。但是相比架构而言,神经网络权重参数的重要性到底有多少?
来自德国波恩-莱茵-锡格应用技术大学和谷歌大脑的一项新研究提出了一种神经网络架构搜索方法,这些网络可以在不进行显式权重训练的情况下执行各种任务。
为了评估这些网络,研究者使用从统一随机分布中采样的单个共享权重参数来连接网络层,并评估期望性能。结果显示,该方法可以找到少量神经网络架构,这些架构可以在没有权重训练的情况下执行多个强化学习任务,或 MNIST 等监督学习任务。
如下是两个不用学习权重的神经网络示例,分别是二足行走智能体(上)和赛车(下):
为什么神经网络不用学习权重
在生物学中,早成性物种是指那些天生就有一些能力的幼生体。很多证据表明蜥蜴和蛇等动物天生就懂得逃避捕食者,鸭子在孵化后也能自己学会游泳和进食。
相比之下,我们在训练智能体执行任务时,会选择一个典型的神经网络框架,并相信它有潜力为这个任务编码特定的策略。注意这里只是「有潜力」,我们还要学习权重参数,才能将这种潜力变化为能力。
受到自然界早成行为及先天能力的启发,在这项工作中,研究者构建了一个能「自然」执行给定任务的神经网络。也就是说,找到一个先天的神经网络架构,然后只需要随机初始化的权重就能执行任务。研究者表示,这种不用学习参数的神经网络架构在强化学习与监督学习都有很好的表现。
其实在我们的理解中,如果我们想象神经网络架构提供的就是一个圈,那么常规学习权重就是找到一个最优「点」(或最优参数解)。但是对于不用学习权重的神经网络,它就相当于引入了一个非常强的归纳偏置,以至于,整个架构偏置到能直接解决某个问题。
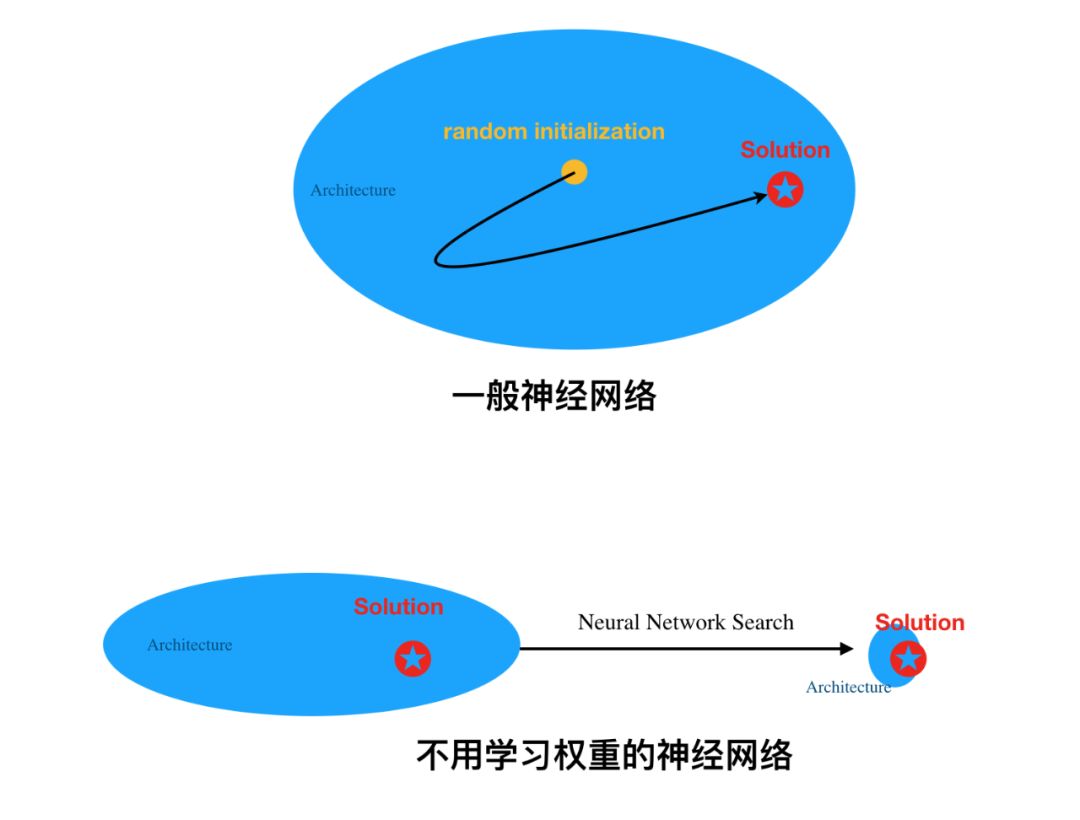
如上是我们对两种网络的直观理解。一般神经网络在架构内随机初始化权重,再学习权重以找到最优解,这样的模型就能完成特定任务。一般只要架构足够「大」,那么它很可能包含最优解,梯度下降也就能大致找到它了。
但是对于不用学习权重的神经网络,它相当于不停地特化架构,或者说降低模型方差。这样,当架构越来越小而只包含最优解时,随机化的权重也就能解决实际问题了。当然,如研究者那样从小架构到大架构搜索也是可行的,只要架构能正好将最优解包围住就行了。
以前就有懒得学习的神经网络
几十年的神经网络研究为不同的任务提供了具有强归纳偏置的构造块。比如卷积神经网络就尤其适合处理图像。
Ulyanov 等人 [109] 展示了随机初始化的 CNN 可在标准逆问题(如去噪、超分辨率和图像修复)中作为手工先验知识(handcrafted prior)使用,且性能优越。
Schmidhuber 等人 [96] 展示了使用习得线性输入层的随机初始化 LSTM 可以预测时序,而传统 RNN 不行。近期在自注意力 [113] 和胶囊网络 [93] 方面的研究拓宽了创建适用于多个任务的架构的构造块范围。
受随机初始化 CNN 和 LSTM 的启发,该研究旨在搜索权重无关的神经网络,即这些具备强归纳偏置的网络可以使用随机权重执行不同任务。
核心思想
为了寻找具备强归纳偏置的神经网络架构,研究者提出通过降低权重重要性的方式来搜索架构。具体步骤为:1)为每一个网络连接提供单一的共享权重参数;2)在较大的权重参数值范围内评估网络。
该研究没有采用优化固定网络权重的方式,而是优化在大范围权重值上都有良好性能的架构。研究者证明,该方法可生成使用随机权重参数执行不同连续控制任务的网络。
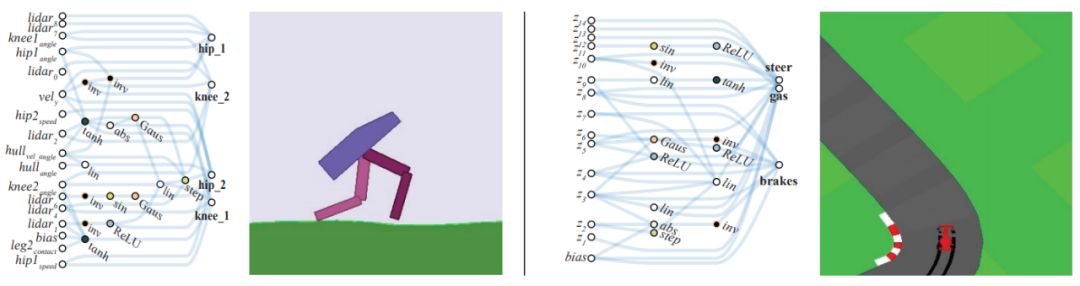
图 1:权重无关神经网络示例:二足行走智能体(左)、赛车(右)。研究者通过降低权重重要性的方式搜索架构。网络使用单一的共享权重值。所有架构在大范围权重值上进行性能优化后,仍然能够在没有权重训练的情况下执行不同任务。
权重无关的神经网络搜索
创建编码解的网络架构与神经架构搜索(NAS)解决的问题有着本质上的区别。NAS 技术的目标是生成训练完成后能够超越人类手工设计的架构。从来没有人声称该解是该网络架构所固有的。
为了生成自身能够编码解的架构,权重的重要性必须最小化。在评估网络性能时,研究者没有选择使用最优权重值的网络,而从随机分布中抽取权重值。用权重采样取代权重训练可以确保性能只与网络拓扑结构有关。
然而,由于维度很高,除了最简单的网络外,权重空间的可靠采样在所有网络上都是不可行的。尽管维度问题阻碍了研究者对高维权重空间进行高效采样,但通过在所有权重上执行权重共享,权重值的数量减少到 1。
系统采样单个权值非常简单、高效,可以让我们进行几次试验就能近似网络性能。然后可以利用这一近似来搜索更好的架构。
主要流程
搜索权重无关的神经网络(WANN)的流程如下:
创建最少神经网络拓扑结构的初始群组;
在多个 rollout 上对每个网络进行评估,每个 rollout 分配一个不同的共享权重值;
根据网络的性能和复杂度对其进行排序;
通过改变排名最高的网络拓扑结构创建新的群组,这些拓扑结构是通过锦标赛选择法(tournament selection)根据概率选择的。
接下来,算法从 (2) 开始重复,生成复杂度递增的权重无关拓扑结构,其性能优于之前的几代。
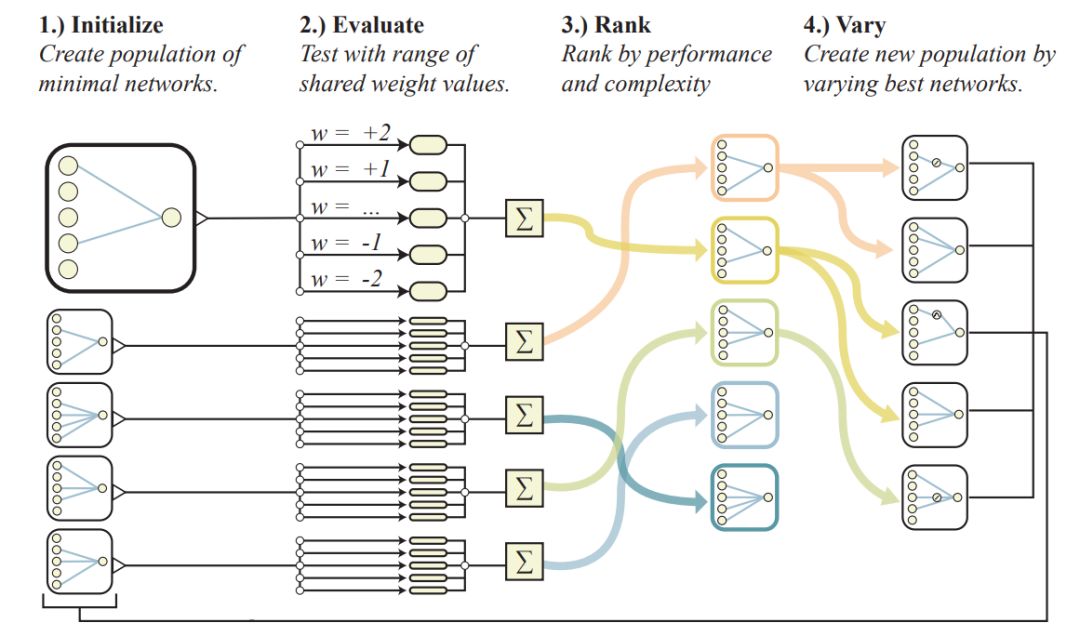
图 2:与权重无关的神经网络搜索图示。
通过每次 rollout 时采样单个共享权重,与权重无关的神经网络搜索在避免权重训练的同时,探索神经网络拓扑结构的空间。研究者基于多次 rollout 评估网络,在每次 rollout 时,为单个共享权重指定相应的值,并记录实验期间的累积奖励。
之后,根据网络的性能和复杂度对网络群组进行排序。然后,根据概率选出排名最高的网络以生成新的群组,排名最高的网络是会随机变化的。之后重复这一过程。
最最核心的拓扑搜索
用于搜索神经网络拓扑的算子受到神经进化算法 NEAT 的启发。不过 NEAT 中的拓扑和权重值是同时进行优化的,而本研究无视权重,仅使用拓扑搜索算子。
最初的搜索空间包括多个稀疏连接网络、没有隐藏节点的网络,以及输入和输出层之间仅有少量可能连接的网络。使用 insert node、add connection、change activation 这三个算子中的其中一个修改已有网络,从而创建新网络。新节点的激活函数是随机分配的。
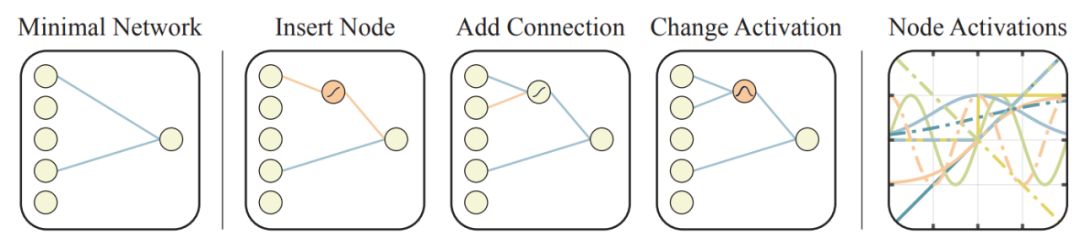
图 3:搜索网络拓扑空间的算子。
鉴于网络的前馈本质,在之前不连接的节点之间添加新连接。当隐藏节点的激活函数被改变后,激活函数进入随机分配模式。激活函数包括常见函数(如线性激活函数、sigmoid、ReLU)和不那么常见的(如 Gaussian、sinusoid、step),它们编码输入和输出之间的多种关系。
实验结果
该研究在三个连续控制任务上评估权重无关神经网络(WANN):CartPoleSwingUp、BipedalWalker-v2 和 CarRacing-v0。研究者基于之前研究常用的标准前馈网络策略创建权重无关网络架构,从中选取最好的 WANN 架构进行平均性能对比(100 次试验)。
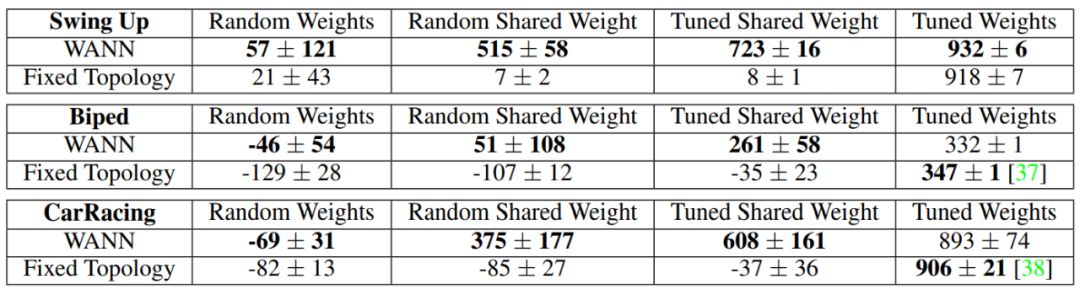
表 1:随机采样网络和使用权重训练的网络在连续控制任务上的性能。
传统的固定拓扑网络仅在大量调参后才能生成有用的行为,而 WANN 使用随机共享权重都可以执行任务。
由于 WANN 很小,很容易解释,因此我们可以查看以下网络图示,了解其工作原理。
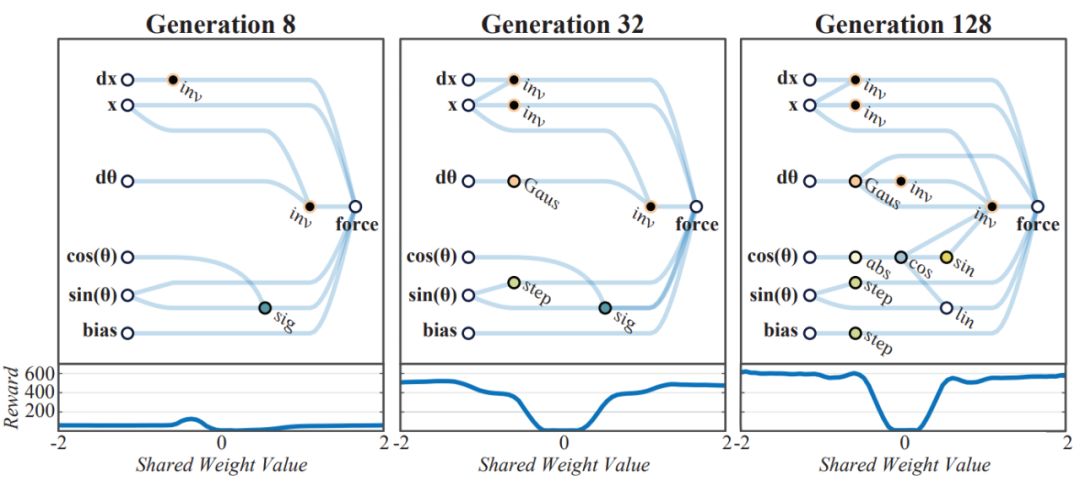
图 4:权重无关拓扑随着时间的变化。Generation 128:添加复杂度,以改进小车的平衡动作。
模型最终在 BipedalWalker-v2 任务上获得的最好效果。

模型最终在 CarRacing-v0 任务上获得的最好效果。
有监督分类问题又怎样
WANN 方法在强化学习任务上取得的成果让我们开始思考,它还可以应用到哪些问题?WANN 能够编码输入之间的关系,非常适合强化学习任务:低维输入加上内部状态和环境交互,使反应型和自适应控制器得以发现。
然而,分类问题没那么模糊,它界限分明,对就是对,错就是错。作为概念证明,研究者调查了 WANN 在 MNIST 数据集上的表现。
即使是在高维分类任务中,WANN 方法依然表现非常好(如图 5 左所示)。虽然局限于单个权重值,WANN 方法能够分类 MNIST 数字,且性能堪比具备数千个权重的单层神经网络(权重通过梯度下降进行训练)。创建的架构依然保持权重训练所需的灵活性,从而进一步提升准确率。
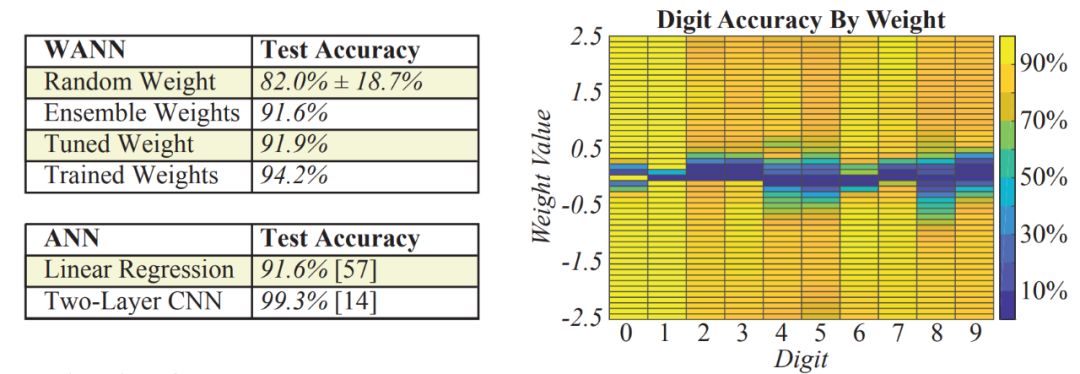
图 5:MNIST 数据集上的分类准确率。
上图左:以多个权重值作为集成进行实例化的 WANN 比随机权重采样的网络性能好得多,且性能与具有数千个权重的线性分类器相同。上图右:在所有数字上具有更高准确率的单个权重值不存在。WANN 可被实例化为多个不同网络,它们具有创建集成的可能性。
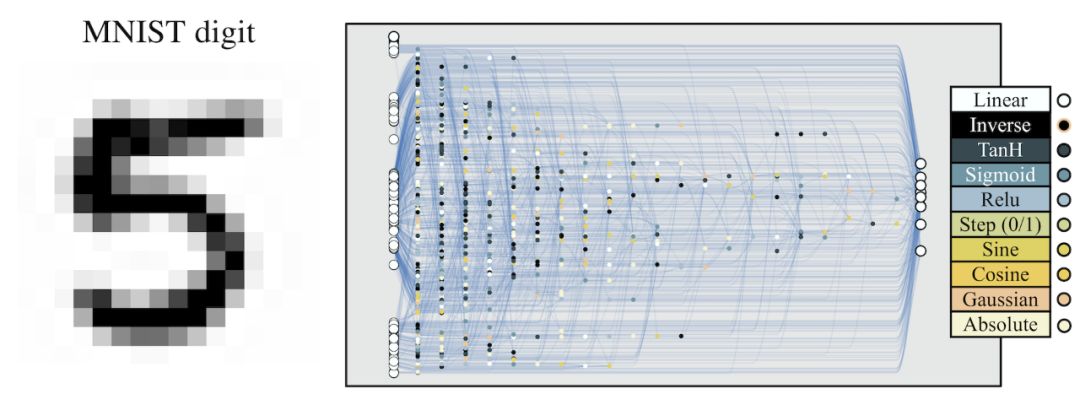
MNIST 分类网络进化为可以使用随机权重。
-
控制器
+关注
关注
113文章
16562浏览量
180303 -
神经网络
+关注
关注
42文章
4789浏览量
101530 -
机器学习
+关注
关注
66文章
8459浏览量
133374
原文标题:真正的神经网络,敢于不学习权重
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐








 工商网监
工商网监
评论