 自动驾驶模拟仿真系统中的传感器模型
自动驾驶模拟仿真系统中的传感器模型
摄像头
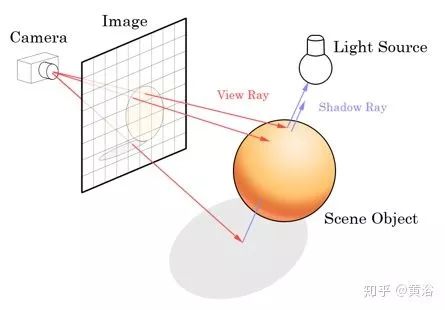
摄像头仿真就是生成图像,逼真的图像,通过计算机图形学对三维景物(CAD)模型添加颜色与光学属性。现在流行的Unreal Engine或者Unity 3D,就是基于物理的渲染引擎,实现一些CAD模型的绘制算法,比如光线跟踪(ray tracing)或者光线投射(ray casting),来实现图像合成(如图展示光线和图像的关系)。一些开源的自动驾驶仿真系统比如Intel Carla(Car Learning to Act)和Microsoft AirSim都采用了这些渲染引擎。
有一些开源的虚拟图像库,已经在计算机视觉的研究中得到应用,比如Virtual KITTI,FCAV (UM Ford Center for Autonomous Vehicles)和Synthia等,下面图有一些各自的图像例子。
理论上,在计算机图形学有各种光照模型和绘制模型,当年Nvidia在GPU硬件对图形学算法加速做出了重大贡献,包括著名的voxel shader和pixel shader(fragment shader)。大家说计算机视觉是计算机图形学的逆过程,只是它和计算机图形学也可以结合,结果有两个重要输出,一个是增强现实(AR),另一个是基于图像的绘制(IBR)。
AR的思想在仿真系统也可以体现,比如在真实的街景中可以插入合成的车辆或者行人。IBR在虚拟环境生成的过程中可以通过一些拍摄的图像生成一些背景以简化实际渲染的计算量。更甚至,通过机器学习,比如GAN,在大量真实图像数据的训练情况下,和图形学的CAD模型结合,也可以合成新场景图像。
除了3-D几何和物理模型之外,还需要对相机镜头的结构与光学特性,内部数据采集过程进行仿真,例如焦距,畸变,亮度调节,伽玛调节,景深(depth of field),白平衡,高动态范围(HDR)色调调整等。
激光雷达
介绍一篇模拟激光雷达的论文。首先,采用非常流行的游戏GTA-V(Grand Theft Auto V)获取模拟的点云和高保真图像。
为了模拟真实的驾驶场景,在游戏中使用自主车(ego vehicle),安装有虚拟激光雷达,并通过AI接口在虚拟世界中进行自动驾驶。系统同时收集激光雷达点云并捕捉游戏图像。在虚拟环境中,虚拟摄像头和虚拟激光雷达放在同一个位置。这样做有两个优点:
可以轻松地对收集的数据进行健全性检查(sanity check),因为点云和相应的图像必须保持一致;
游戏的虚拟摄像头和虚拟激光雷达之间的标定可以自动完成,然后收集的点云和场景图像可以组合在一起作为传感器融合任务的神经网络训练数据集。
光线投射(ray tracing)用于模拟虚拟激光雷达发射的每个激光射线。光线投射将光线起点和终点的3D坐标作为输入,并返回该光线命中的第一个点3D坐标,该点将用于计算点的距离。激光雷达参数包括垂直视场(VFOV),垂直分辨率,水平视场(HFOV),水平分辨率,俯仰角,激光射线的最大范围和扫描频率。
如下图显示了一些可配置的参数:(a)虚拟激光雷达前向图的正视图:黑色虚线是水平线,α是垂直视场(FOV),θ是垂直分辨率,σ是俯仰角; (b)表示虚拟激光雷达的俯视图,β是水平FOV,φ是水平分辨率。
该系统实现3-D激光雷达点云和摄像头图像的自动校准,而且用户可以选择所需的游戏场景,并指定和改变游戏场景的8个维度:汽车模型,位置,方向,数量,背景,颜色,天气和时间。前5个维度同时影响激光雷达点云和游戏图像,而后3个维度仅影响游戏图像。
介绍一篇基于机器学习模拟雷达的论文工作。由于多径反射,干涉,反射表面,离散单元和衰减等影响,雷达建模不简单。详细基于物理原理的雷达模拟是有的,但对实际场景而言计算量难以承受。
一种构建概率随机汽车雷达模型的方法基于深度学习和GAN,产生的模型体现了基本的雷达效应,同时保持实时计算的速度。采用深度神经网络作为雷达模型,从数据中学习端到端的条件概率分布。网络的输入是空间栅格和对象列表,输出是读取的传感器数据。
如上图是在深度学习框架下模拟雷达数据的表示。空间栅格是具有两个主要尺寸,即距离和方位角的的3D张量,第3维度是由不同类型的信息层组成。这个类似于RGB图像,其像素信息存储在空间维度和颜色通道中。那么,这种空间栅格同样适合CNN模型。
提供两个直接参数化概率分布的基准雷达模型:正态分布和高斯混合模型。多变量正态分布通常用于机器学习,因为它具有良好的数学性能。不过,正态分布是单峰的。而且正态分布的参数与目标变量的维数呈二次方增长。这里CNN模型的输出是具有两层的张量网格:一个平均值,一个对角对数方差。
随机雷达模型的一个重要挑战是,传感器输出是多模态和空间相关的。回归方法将平滑可能的解决方案,导致模糊的预测。而变分自动编码器(VAE)允许学习一对多概率分布而无需明确输出哪个分布。
该模型的架构是一个编码器-解码器网络。
编码器获取光栅和对象列表并产生潜在的特征表示x,解码器采用特征表示和随机生成的噪声值并产生预测的传感器测量值。编码器由两分支组成,即一个空间光栅和一个对象列表,这些分支合并在一起产生潜在的特征表示。两个分支完全由卷积层组成。输出被扁平化级联在一起,然后使用有ReLU的全连接层处理。
解码器使用编码特征和随机噪声生成功率值的雷达极坐标网格。 在VAE重新参数化时候,随机噪声加入输入信号。使用ReLU激活的全连接层连接和处理噪声和潜在特征,然后重新整形和一系列反卷积层处理,产生输出雷达信号。
其他传感器
其他传感器,如GPS,IMU,超声波雷达和V2X传感器,也可以模拟仿真其数据。
GPS模拟GPS位置以及GPS噪声模型参数,输出车的经纬度,速度,航向等。
IMU模拟车的加速度和角速度,特别是GPS信号丢失时车的位置,速度、和航向的累积误差。
超声波雷达(主要是自动泊车)模拟超声波雷达位置,角度和障碍物的距离。
V2X模拟动态交通流设备数据,甚至要反映通信延时或丢包的情况。
-
摄像头
+关注
关注
59文章
4793浏览量
95255 -
自动驾驶
+关注
关注
782文章
13619浏览量
165916
原文标题:自动驾驶模拟仿真系统中的传感器模型
文章出处:【微信号:IV_Technology,微信公众号:智车科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
FPGA在自动驾驶领域有哪些优势?
FPGA在自动驾驶领域有哪些应用?
自动驾驶识别技术有哪些
自动驾驶汽车传感器有哪些
XV7181BB 陀螺仪传感器在自动驾驶设备中的应用

自动驾驶仿真测试实践:高精地图仿真

揭秘自动驾驶:未来汽车的感官革命,究竟需要哪些超级传感器?
未来已来,多传感器融合感知是自动驾驶破局的关键
探索自动驾驶传感器仿真模型的可信度







 工商网监
工商网监
评论