 深度学习的最大短板原来是它!
深度学习的最大短板原来是它!
上文用简单的小学数学算了一下Alexnet的参数说需要的内存空间,但对于运行的神经网络,还有一个运行时的资源的问题。在github上的convnet-burden上有一个feature memory[1]的概念,这个和输入的图片的大小和运算的batch的size 都有关。
因此,Nvida的GPU上的HBM和GDDR对于大部分神经网络的炼丹师都是非常重要,能够在一个GPU的内存里完成模型的运算而不用考虑换进换出是大有裨益的。
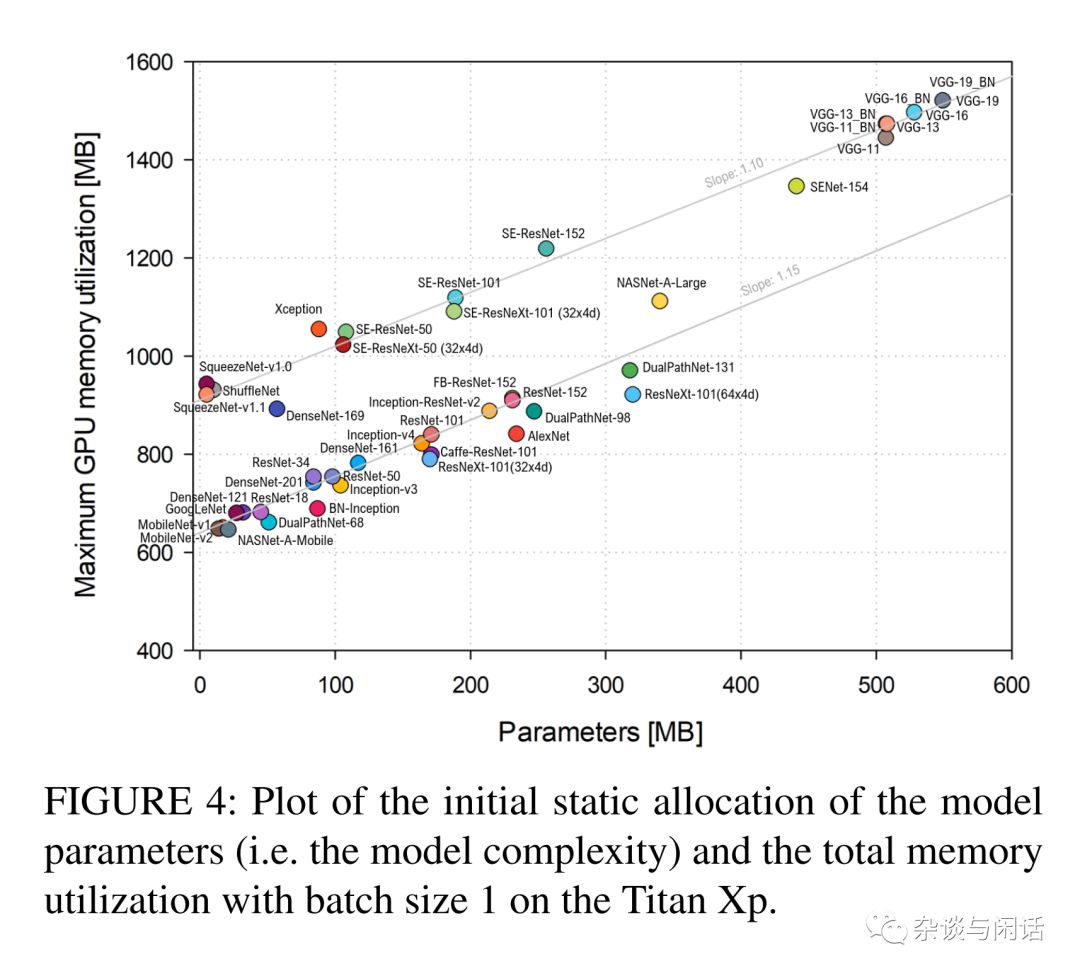
总体来说,这个统计还是很直观的[2],就是网络模型越复杂,参数的规模越大,资源的占用也就越多,对GPU的整体内存占用也是越多。因此如何在有限的GPU上完成模型的训练也成了一个非常有用的技巧。
在我们考虑计算对于内存带宽的需求之前,我们需要复习一下作为一个神经网络,每一层对于计算的需求,这个还是可以用小学数学搞定的东西。还是用标准的Alexnet为例。
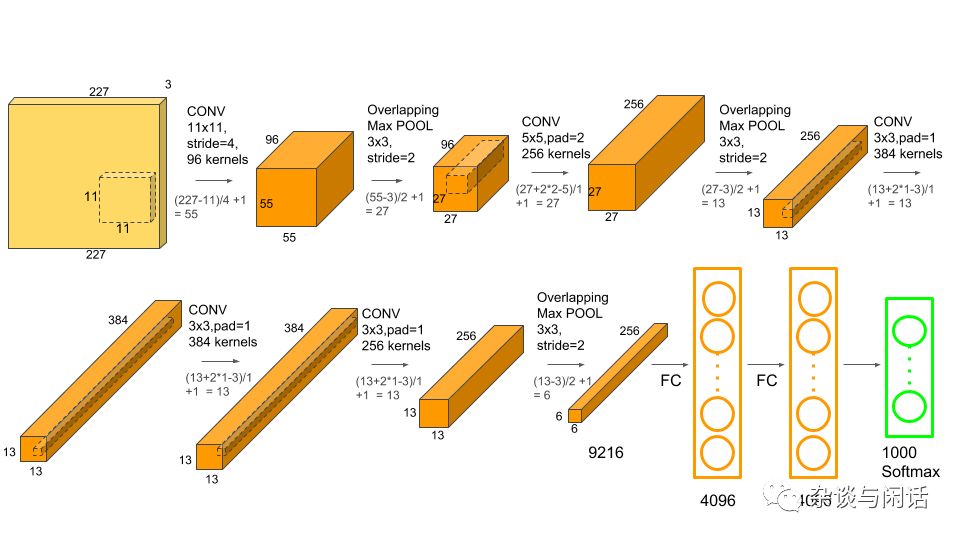
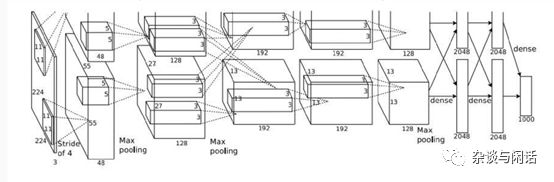
对于计算来讲,卷积层应该是主要,对于Pooling来讲,应该是没有的,对于FC来讲,也是比较简单的。基本上是乘法.
Conv Layer的计算复杂度:
1. 当前的层的图片的width
2. 当前的层的图片的height
3.上一层的深度
4。当前层的深度
5. 当前kernel的大小
的乘积就是这一层卷积的计算复杂度。以Alexnet的conv1为例:
Conv-1:第一层的卷积有96个kernel。kernel的大小是11X11,卷积的stride是4,padding是0
当前的输出的是55X55,上一层的input的深度是3, 当前的kernel是11X11,当前的深度是96.因此
55X55X3X11X11X96=105,415,200次MAC的计算。
对于Alexnet来讲,需要注意的是conv2,4 ,5三个层的计算没有和上一层直接跨GPU,因此需要的计算规模上/2.
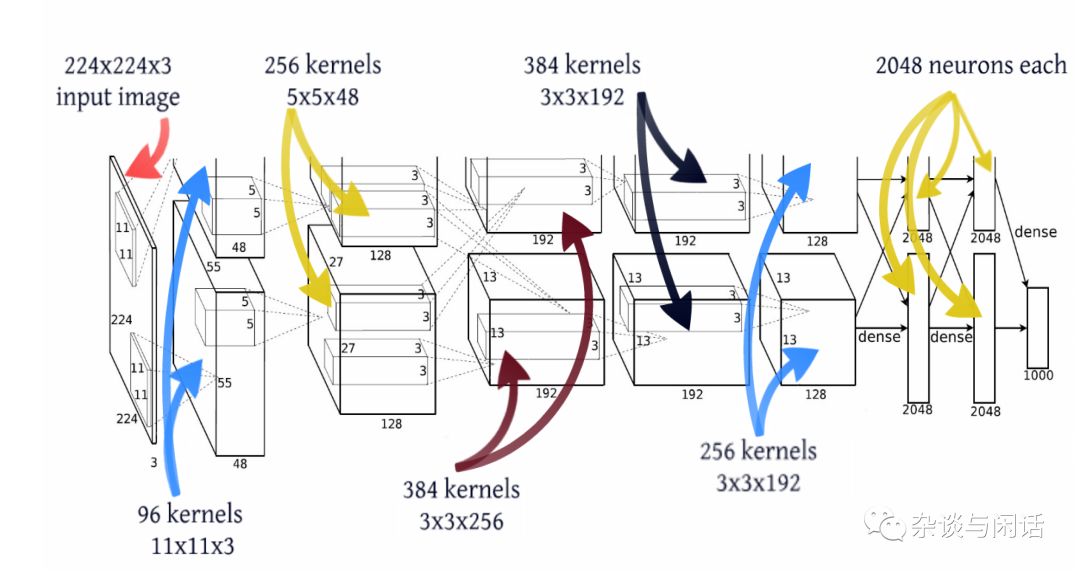
对于FC来讲,比较粗略的计算就是 输入和当前层的规模的乘积。
MaxPool-3:第五层卷积的最大值,Pooling是3X3, stride是2,
FC-1:第一个全连接层,有4096个神经元
因此FC-1 的计算就是:
6X6X256X4096=37,748,736
因此,总结一下之前的参数信息和计算量, Alexnet的图如下:

这个通过统计每一层的计算的复杂度,就可以得到整个网络的计算复杂度,也就是训练一次网络需要多少的MACC资源。对于alexnet 来讲就是:724,406,816 次操作。
这个时候,有一个关键的信息就出来了。就是芯片的能力,大家都是用TFLOPs来表示芯片的浮点处理能力。对于Nvida的芯片,有了TFLOPS,有个一个网络需要的计算量,我们就可以很快计算出每一层计算需要的时间了。
对于Alexnet 的conv1 来讲,在Nivida 最新的V100的120TFLOPs的GPU上,进行训练的执行时间差不多是105,415,200X2/(120X1,000,000,000,000), 约等于1.75us (微秒)。
对于Pooling这一层来讲,因为没有MACC的计算量,但是因为要Max Pooling,也需要大小比较的计算。因此,它的计算基本就是算是数据读取。因此它的数据读取是 conv-1 的55X55X96=290,440. 因此在同样的GPU下,它的执行时间就是 2.42ns.
好了,有了计算时间,现在需要来计算数据量了。对于Conv1来讲,它包含了对一下数据的读写:
对于输入数据的读取 227X227X3 =154,587
对于输出数据的写入55x55x96=290,400
对于参数的读取34848+96=34944
因此,就可以算出对于120TFLOP的GPU的要求:因为在很多ASIC芯片中,输入输出可能在DDR中,但是参数可能放在SRAM中,因此我们就分开计算了。
对于输入数据的读取 (154,587/1.75)X1000,000X4=351.95GB/s
对于输出数据的写入 (290,400/1.75)X1000,000X4=661.16GB/s
对于参数的读取 (34944 /1.75)X1,000,000X4=79.34GB/s
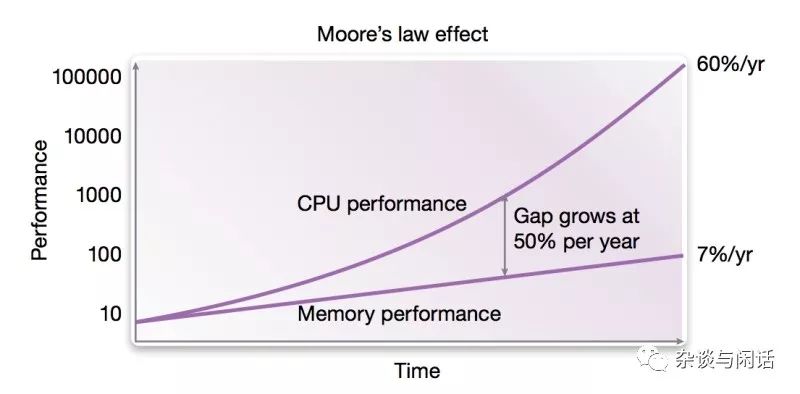
提个醒,我们现在的PC服务器上性能最高的DDR4的带宽基本上在19GB/s左右。看到压力了吧。现在的memory连很慢的CPU都跟不上。更何况老黄家的核弹。
-
NVIDIA
+关注
关注
14文章
4970浏览量
102958 -
深度学习
+关注
关注
73文章
5497浏览量
121094
原文标题:芯片架构师终于证明:深度学习的最大短板原来是它!
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
NPU在深度学习中的应用
激光雷达技术的基于深度学习的进步
AI大模型与深度学习的关系
深度学习中的时间序列分类方法
深度学习中的无监督学习方法综述
深度学习与nlp的区别在哪
深度学习中的模型权重
深度学习常用的Python库
深度学习模型训练过程详解
深度学习与传统机器学习的对比
深度解析深度学习下的语义SLAM

为什么深度学习的效果更好?

【技术科普】主流的深度学习模型有哪些?AI开发工程师必备!







 工商网监
工商网监
评论