 CVPR 2019竞赛第一解决方案分享
CVPR 2019竞赛第一解决方案分享
CVPR 2019细粒度图像分类workshop的挑战赛公布了最终结果:中国团队DeepBlueAI获得冠军。本文带来冠军团队解决方案的技术分享。
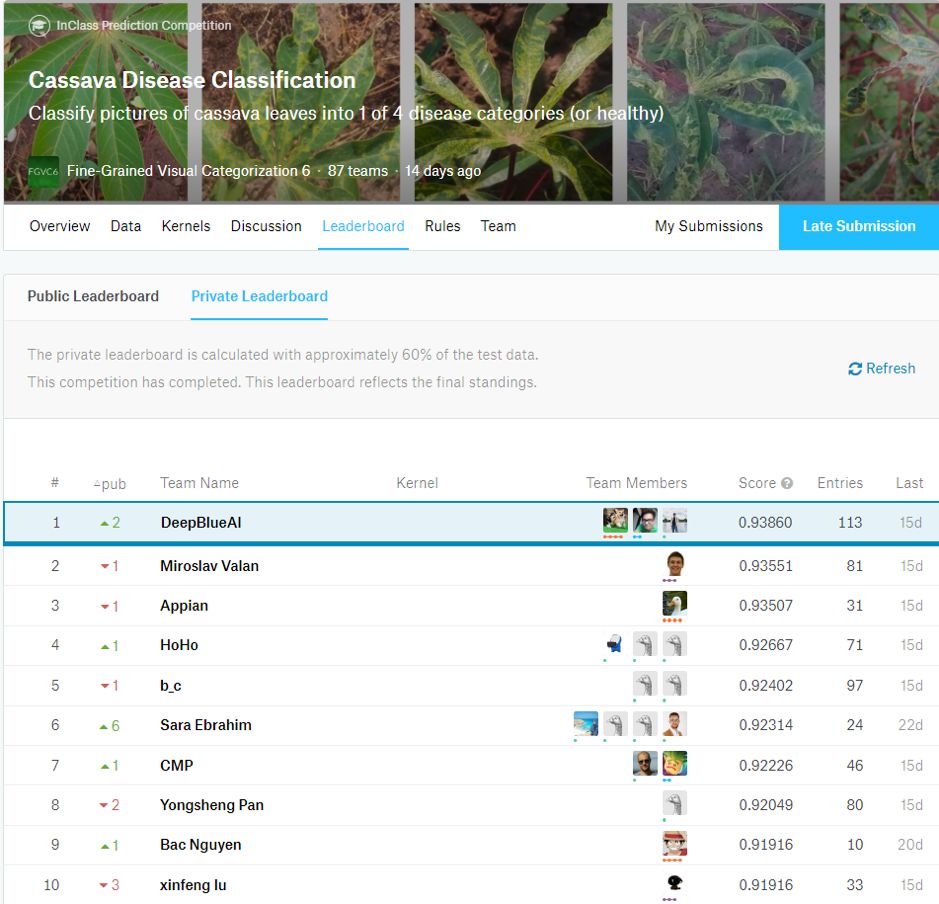
近日,在Kaggle上举办的CVPR 2019 Cassava Disease Classification挑战赛公布了最终结果,国内团队 DeepBlueAI 获得冠军。
国际计算机视觉与模式识别会议(CVPR)是IEEE一年一度的学术性会议,CVPR是世界顶级的计算机视觉会议之一,会议的主要内容是计算机视觉与模式识别技术。CVPR 2019 在洛杉矶长滩举行,FGVC6 Workshop也将作为 CVPR 2019 的一部分如期召开。FGVC6 Workshop 共有十个挑战赛,每个都代表了细粒度视觉分类在某个细分领域的挑战。
FGVC全称为Fine-Grained Visual Categorization,细粒度图像分类,即区分不同的动物和植物、汽车和摩托车模型、建筑风格等,是机器视觉社区刚刚开始解决的最有趣和最有用的开放问题之一。细粒度图像分类在于基本的分类识别(对象识别)和个体识别(人脸识别,生物识别)之间的连续性。相似的类别之间的视觉区别通常非常小,因此很难用当今的通用识别算法来解决。
今年是FGVC举办的第六届比赛,往届比较著名的比赛诸如iNaturalist和iMaterialist,前者侧重于区分自然界不同的生物,后者则是侧重于区分不同的人造物体。
不同于传统的广义上的分类任务,FGVC的挑战致力于子类别的划分,需要分类的对象之间更加相似,例如区分不同的鸟类、不同的植物、不同的日用品等。
赛题介绍
Cassava Disease Classification挑战赛是一个根据木薯的叶子区分不同种类的木薯疾病的任务。Cassava 译为木薯,是非洲第二大碳水化合物供应者,因为其能够承受恶劣的环境。因此木薯是小农种植的一种关键的粮食安全作物,在撒哈拉以南非洲,至少80%的小农家庭种植木薯,而病毒性疾病是低产量的主要来源。
在这次比赛中,主办方引入一个包含5种类别的木薯叶疾病的数据集,该数据集源于在乌干达定期调查中收集到的9436标记图像,主要从农民在自家田地里拍摄的图片,然后由国家作物资源研究所(NaCRRI)与Makarere大学的人工智能实验室共同对图像进行标注。
数据集包括木薯植株的叶子图像,9,436张带注释的图像和12,595张未标记的图像。参与者可以选择使用未标记的图像作为额外的训练数据。目标是学习一个模型,使用训练数据中的图像将给定的图像分类为这4个疾病类别或健康叶子的类别。
团队成绩
题目特点以及常用方法
细粒度图像分类 (Fine-grained imagecategorization), 又被称作子类别图像分类 (Sub-category recognition)。其目的是对属于同一基础类别的图像进行更加细致的子类划分, 但由于子类别间细微的类间差异以及较大的类内差异, 更传统的图像分类任务相比, 细粒度图像分类难度明显要大很多。从下图中的木薯的叶子可以看出,不同的叶子病变情况长相非常相似,此外同一类别由于姿态,背景以及拍摄角度的不同,存在较大的类内差异。
细粒度图像分类的常用方法可以分为两种,分别是基于强监督信息的方法和仅使用弱监督信息的方法。前者需要使用对象的边界框和局部标注信息,后者仅使用类别标签,Cassava Disease Classification是一种弱监督信息的细粒度识别,一般采用预训练模型finetune,并结合训练技巧对模型精调。
实验模型:SENet、ResNet、DenseNet
ResNet是CNN历史上一个里程碑事件,模型深度达到了152层,这和之前CNN的层数完全不在一个量级上。ResNet中的identity的这条线类似一条电路上的短路(shortcuts,skip connection),使得模型学习更加容易,深层可以直接得到浅层的网络特征。
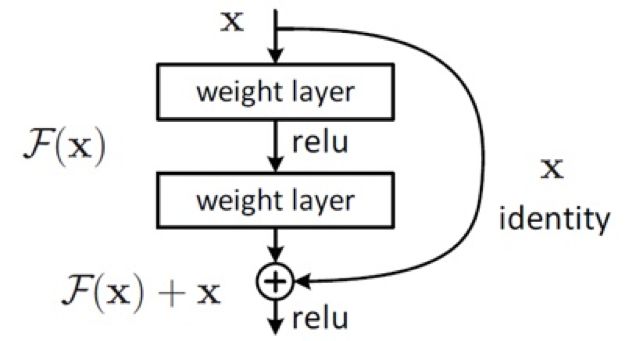
DenseNet的原理不同于ResNet通过加深网络层数以及Inception通过加宽网络宽度来提高模型识别能力,而是利用特征重用和类似ResNet的Bypass的方式,减少了网络参数和缓解了梯度消失的问题。

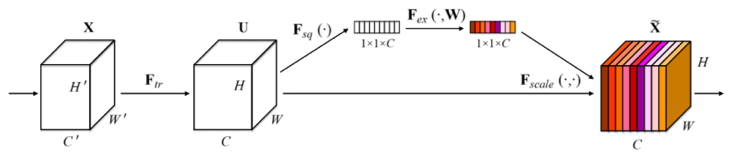
SENet提出了Sequeeze and Excitation block,该模块于传统网络的最大区别在于其侧重于构建通道之间的依赖关系,利用global average pooling来Sequeeze特征图,并用Excitation对前者进行非线性变换,最后再叠加到输入特征上。可以自适应的校准通道的相应特征,并且该模块可以嵌入到现有的网络结构中,实现精度的提升。
模型训练与评测
原图 VerticalFlip HorizontalFlip RandomRotateRandomCrop
RandomErasing
CutOut
由于训练集样本过少,对比分析后对输入数据采取 VerticalFlip,HorizontalFilp 、RandomRotate和RandomCrop的增强操作。此外,还使用了RandomErasing和Cutout,方法会在原图随机选择一些矩形区域,改变该区域的像素值,通过这些数据增强的方式,训练集的图片会被不同程度的遮挡,这样可以进一步降低过拟合的风险并提高模型的鲁棒性。
同样的,为了增强模型的鲁棒性减少过拟合,本次比赛我们利用5-fold crossvalidation,交叉验证有效利用了有限的数据,并且评估结果能够尽可能接近模型在测试集上的表现。用crossvalidation之后,SE_ResNeXt50测试集准确率提升0.01016,ResNet34测试集准确率提升0.01142。

这次比赛中,我们还使用了Mixup和label smoothing的训练策略。Mixup顾名思义就是将两张图片按一定比例融合起来作为输入,计算loss时,针对两张图片的标签分别计算,然后按比例加权求和。Mixup是一种抑制过拟合的策略,通过增加了一些数据上的扰动,从而提升了模型的泛化能力。
实验证明,该方式能将Top1准确率提高近一个百分点。对于分类问题,常规做法时将类别换成one-hot vector。由于标签是类别的one-hot vector,这样做易导致过拟合使得模型泛化能力下降;同时这种做法会将所属类别和非所属类别之间的差距尽可能大,因此很难调优模型。
为此,可以用label smoothing对标签进行平滑处理,软化one-hot类型标签,使得计算损失函数时能有效抑制过拟合现象。
训练以Adam为optimiser,学习率的设置为阶梯状,共四个取值,[3e-4, 1e-4,1e-5, 1e-6],设置patience为4来衰减学习率,即模型连续4个epoch在验证集上效果没有提升则衰减学习率,训练总的epcoh在20次左右。本实验使用的GPU为4卡2080Ti,并行训练一个模型,batchsize通常设为32,较大的模型根据实际情况适当减小。
模型在预测时采用了数据增强的方式Test time augmentation(TTA),即将样本图像进行多个不同的变换获得多个不同的预测结果,再将预测结果进行平均,提高精度。本次任务利用3*TTA,包括 RandomCrop, RandomCrop+HorizontalFlip 和RandomCrop+VerticalFlip 。
模型集成是算法比赛中常用的提高模型精度方法,本次比赛我们训练了大量在ImageNet上表现优良的模型,其中表现较好的模型如下表所示、在采取多种融合方式之后,最终发现SE_ResNeXt50、SE_ResNeXt101、SENet154以及DenseNet201按照归一化后权重的融合效果最好,在测试集上的准确率达到了0.92516。
| 模型 | 测试集准确率 |
| SE_ResNeXt50 | 0.92251 |
| SE_ResNeXt101 | 0.92384 |
| SENet154 | 0.92384 |
| DenseNet201 | 0.91721 |
| MobileNetV2 | 0.91601 |
| ResNet152 | 0.91710 |
| SE_ResNeXt50+SE_ResNeXt101+SENet154+DenseNet201 | 0.92516 |
本次比赛主办方提供了12595张未带label的额外数据集,为了充分利用该数据集,利用在测试集表现最好的融合模型给这些数据集贴上伪标签。然后利用训练集和伪标签数据集训练模型,为了防止模型在伪标签上过拟合,我们对伪标签采取了一定的筛选操作。
采取的思路是:用多个不同概率阈值的过滤所得到的伪标签进行线下实验,看哪个阈值下的数据在线下的表现最好,就用通过该阈值筛选过滤出的数据,最终以0.95的阈值筛选出一半的数据作为添加到训练集的伪标签数据。
实验证明这种半监督的学习方法具有更强的泛化能力。

| 模型 |
测试集准确率 (public leaderboard) |
Private leaderboard |
| SE_ResNeXt50 | 0.92251 | 0.93012 |
| SE_ResNeXt50 with pseudo data | 0.92195 | 0.93512 |
| SE_ResNeXt101 | 0.92384 | 0.93134 |
| SE_ResNeXt101 with pseudo data | 0.92202 | 0.93409 |
| SENet154 | 0.92384 | 0.93054 |
| SE_ResNeXt154 with pseudo data | 0.92283 | 0.93428 |
|
SE_ResNeXt50+SE_ResNeXt101+ SENet154+DenseNet201 |
0.92516 | 0.93727 |
|
SE_ResNeXt50+SE_ResNeXt101+ SENet154+DenseNet201 with pseudo data |
0.92516 | 0.93860 |
进一步工作
针对细粒度图像分类,MSRA有一个结论:分析该问题时图像的形态、轮廓特征原没细节纹理特征重要,而传统的CNN模型都是在构建轮廓特征,因此在构建神经网络时,应该更加精确地找到图像中最有区分度的子区域,然后再对这些区域采用高分辨率、精细化特征的方法,这样可以进一步提高细粒度图像分类的准确率。
另外对数据本身我们可能需要做更多的工作,在任务初期没有做足够的探索性数据分析,例如数据的分布、类型、输入图像的尺寸等都是影响结果的因素,因此数据分析也是后面的一个尝试点。
-
图像
+关注
关注
2文章
1083浏览量
40449 -
人工智能
+关注
关注
1791文章
47146浏览量
238133 -
计算机视觉
+关注
关注
8文章
1698浏览量
45966
原文标题:CVPR 2019细粒度图像分类竞赛中国团队DeepBlueAI获冠军 | 技术干货分享
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一种使用LDO简单电源电路解决方案

解决方案 | 基于TSMaster的平板电脑解决方案

中国科大-云知声联合团队斩获CVPR2024开放环境情感行为分析竞赛三项季军
安森美OBC系统解决方案设计指南
炬芯科技第一代K歌音箱单芯片解决方案量产
润和软件连续四年蝉联数字业务类解决方案市场第一名
润和软件连续三年蝉联互联网金融服务类解决方案市场占有率第一

一文读懂音频解决方案专家







 工商网监
工商网监
评论