 谷歌大脑CMU联手推出XLNet,20项任务全面超越BERT
谷歌大脑CMU联手推出XLNet,20项任务全面超越BERT
谷歌大脑和CMU联合团队提出面向NLP预训练新方法XLNet,性能全面超越此前NLP领域的黄金标杆BERT,在20个任务上实现了性能的大幅提升,刷新了18个任务上的SOTA结果,可谓全面屠榜!
近日,谷歌大脑主任科学家Quoc V. Le在Twitter上放出一篇重磅论文,立即引发热议:
这篇论文提出一种新的NLP模型预训练方法XLNet,在20项任务上(如SQuAD、GLUE、RACE) 的性能大幅超越了此前NLP黄金标杆BERT。
XLNet:克服BERT固有局限,20项任务性能强于BERT
本文提出的XLNet是一种广义自回归预训练方法,具有两大特点:(1)通过最大化分解阶的所有排列的预期可能性来学习双向语境,(2)由于其自回归的性质,克服了BERT的局限性。
此外,XLNet将最先进的自回归模型Transformer-XL的创意整合到预训练过程中。实验显示,XLNet在20个任务上的表现优于BERT,而且大都实现了大幅度性能提升,并在18个任务上达到了SOTA结果,这些任务包括问答、自然语言推理、情感分析和文档排名等。
与现有语言预训练目标相比,本文提出了一种广义的自回归方法,同时利用了AR语言建模和AE的优点,同时避免了二者的局限性。首先是不再像传统的AR模型那样,使用固定的前向或后向分解顺序,而是最大化序列的预期对数似然性分解顺序的所有可能排列。每个位置的上下文可以包含来自该位置前后的令牌,实现捕获双向语境的目标。
作为通用AR语言模型,XLNet不依赖于数据损坏。因此,XLNet不会受到BERT受到的预训练和微调后的模型之间差异的影响。同时以自然的方式使用乘积规则,分解预测的令牌的联合概率,从而消除了在BERT中做出的独立性假设。
除了新的预训练目标外,XLNet还改进了预训练的架构设计。 XLNet将Transformer-XL的分段重复机制和相对编码方案集成到预训练中,从而凭经验改进了性能,对于涉及较长文本序列的任务效果尤其明显。
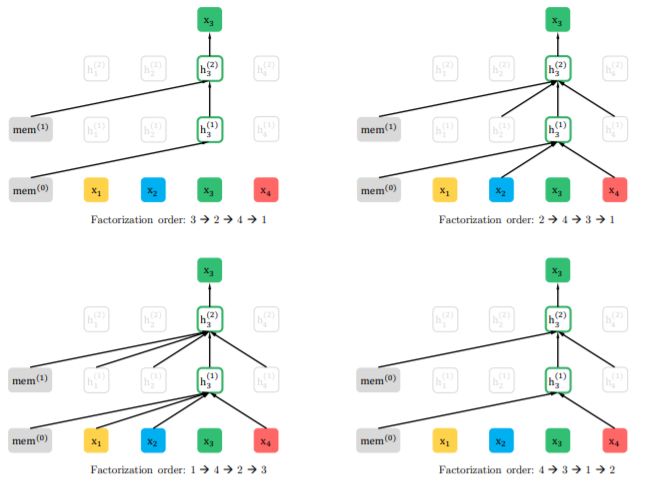
图1:在给定相同输入序列x,但分解顺序不同的情况下,对置换语言建模目标的预测结果
图2:(a):内容流注意力机制,与标准的自注意力机制相同。(b)查询流注意力,其中不含关于内容xzt的访问信息。(c):使用双信息流注意力机制的置换语言建模训练示意图。
全面屠榜:大幅刷新18项任务数据集SOTA性能
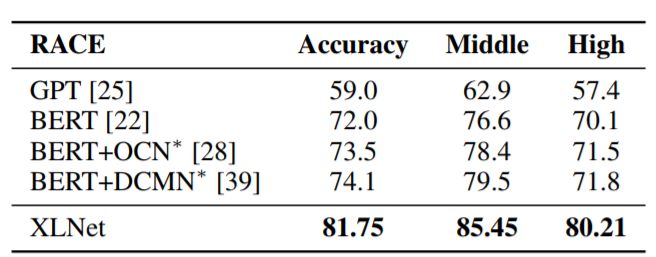
表1:与阅读理解任务RACE测试集的最新结果的比较。 *表示使用聚集模型。 RACE中的“Middle”和“High”是代表初中和高中难度水平的两个子集。所有BERT和XLNet结果均采用大小相似的模型(又称BERT-Large),模型为24层架构。我们的XLNet单一模型在精确度方面高出了7.6分
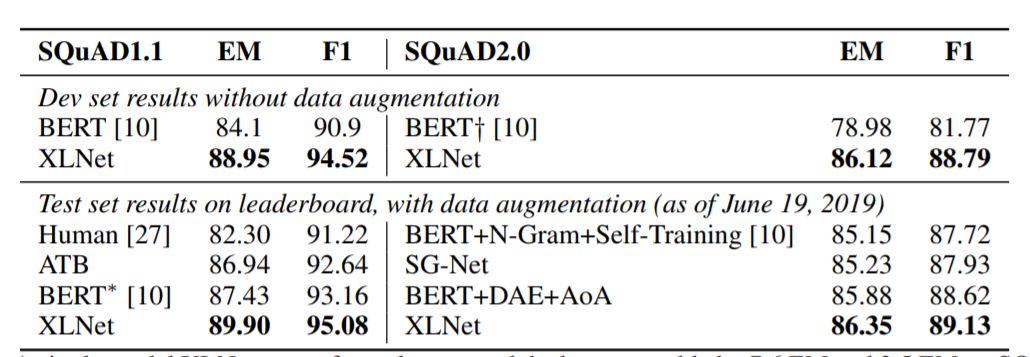
表2:单XLNet模型在SQuAD1.1数据集上的性能优于分别优于真人表现和最佳聚集模型性能达7.6 EM和2.5 EM。
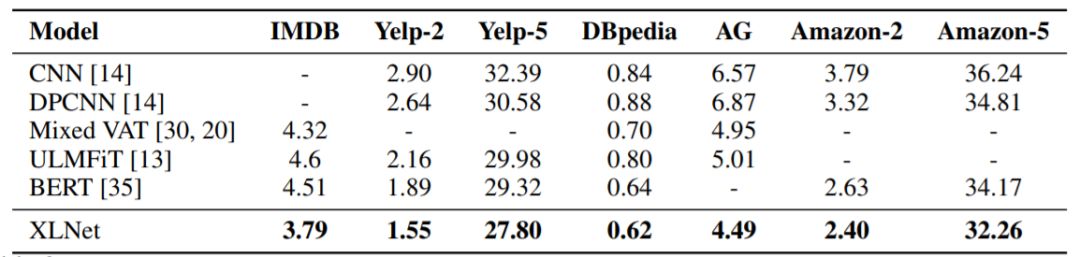
表3:与几个文本分类数据集的测试集上错误率SOTA结果的比较。所有BERT和XLNet结果均采用具有相似大小的24层模型架构(BERT-Large)
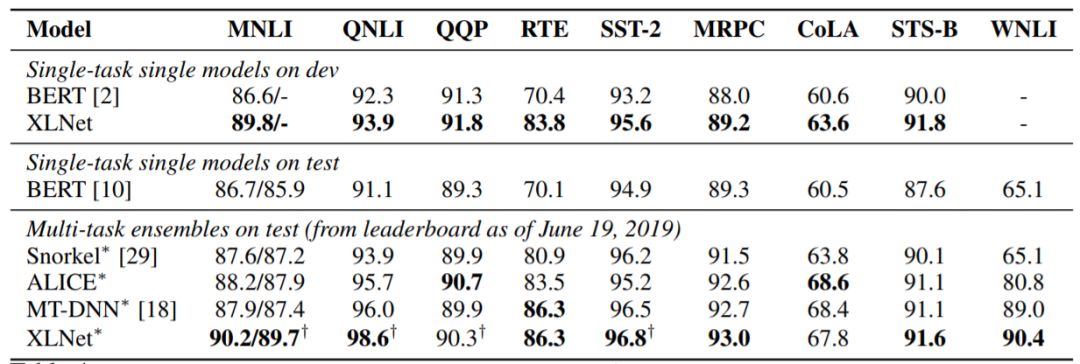
表4:GLUE数据集上的结果。所有结果都基于具有相似模型尺寸的24层架构(也称BERT-Large)。可以将最上行与BERT和最下行中的结果直接比较。
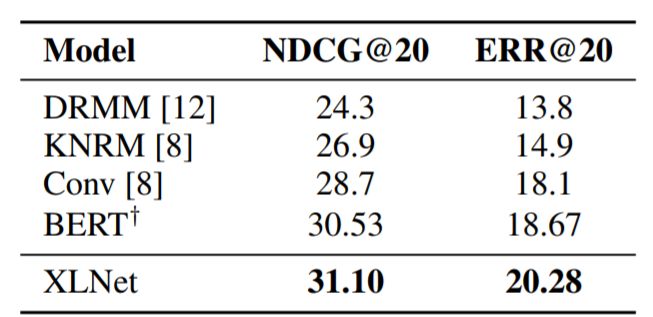
表5:与文档排名任务ClueWeb09-B的测试集上的最新结果的比较。 †表示XLNet的结果。
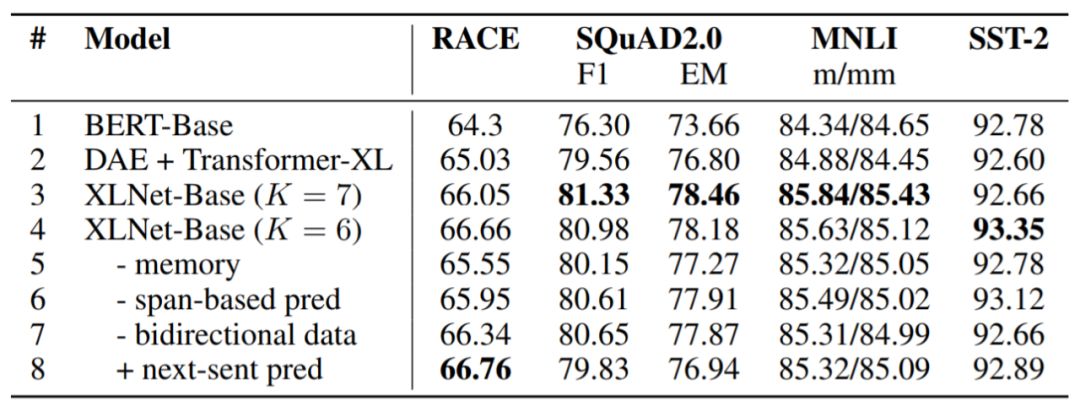
表6:我们使用BERT官方实现方案和XLNet超参数搜索空间在其他数据集上运行BERT,结果如图所示,其中K是控制优化难度的超参数。所有模型都在相同的数据上进行预训练。
从实验结果可以看出,说XLNet全面超越BERT其实一点都不夸张。
知乎热议:512TPU训练,家里没矿真搞不起
有热心网友一早将这篇“屠榜”论文发在了知乎上,从网友的评论上看,一方面承认谷歌和CMU此项成果的突破,同时也有人指出,这样性能强劲的XLNet,还是要背靠谷歌TPU平台的巨额算力资源,“大力出奇迹”果然还是深度学习界的第一真理吗?
比如,网友“Towser”在对论文核心部分内容的简要回顾中,提到了XLNet的优化方法,其中引人注目的一点是其背后的谷歌爸爸的海量算力资源的支持:

512个TPU训练了2.5天,训练总计算量是BERT的5倍!要知道作为谷歌的亲儿子,BERT的训练计算量已经让多数人望尘莫及了。没钱,搞什么深度学习?
难怪NLP领域的专家、清华大学刘知远副教授对XLNet一句评价被毫无悬念地顶到了知乎最高赞:
目前,XLNet的代码和预训练模型也已经在GitHub上放出。
-
谷歌
+关注
关注
27文章
6161浏览量
105287 -
nlp
+关注
关注
1文章
487浏览量
22032
原文标题:NLP新标杆!谷歌大脑CMU联手推出XLNet,20项任务全面超越BERT
文章出处:【微信号:aicapital,微信公众号:全球人工智能】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
谷歌将推出Gemini大型语言模型
AWG和BERT常见问题解答
阿里云发布通义千问2.5大模型,多项能力超越GPT-4
微软、谷歌联手多家科技巨头保护儿童安全
NVIDIA和谷歌云宣布开展一项新的合作,加速AI开发
谷歌发布Axion新款数据中心AI芯片,性能超越x86及云端
谷歌推出能制作旅行攻略的AI工具
谷歌宣布在医疗保健领域推出人工智能计划
Anthropic推出Claude 3大型语言模型,在认知任务性能上创新高
谷歌模型软件有哪些功能
谷歌模型训练软件有哪些功能和作用
Groq推出大模型推理芯片 超越了传统GPU和谷歌TPU
谷歌大型模型终于开放源代码,迟到但重要的开源战略

TikTok引入前谷歌VideoPoet负责人蒋路,发力AI视频生成
大语言模型背后的Transformer,与CNN和RNN有何不同






 工商网监
工商网监
评论