 一种AI算法,可以根据说话声音来预测说话人将作出怎样的肢体动作
一种AI算法,可以根据说话声音来预测说话人将作出怎样的肢体动作
来自UC Berkeley和MIT的研究人员开发了一种AI算法,可以根据说话声音来预测说话人将作出怎样的肢体动作。所预测的动作十分自然、流畅,本文带来技术解读。
人在说话的时候,常常伴随着身体动作,不管是像睁大眼睛这样细微的动作,还是像手舞足蹈这样夸张的动作。
最近,来自UC Berkeley和MIT的研究人员开发了一种AI算法,可以根据说话声音来预测说话人将作出怎样的肢体动作。
研究人员称,只需要音频语音输入,AI就能生成与声音一致的手势。具体来说,他们进行的是人的独白到手势和手臂动作的“跨模态转换”(cross-modal translation)。相关论文发表在CVPR 2019上。
研究人员收集了10个人144小时的演讲视频,其中包括一名修女、一名化学教师和5名电视节目主持人(Conan O’Brien, Ellen DeGeneres, John Oliver, Jon Stewart, 以及Seth Meyers)。
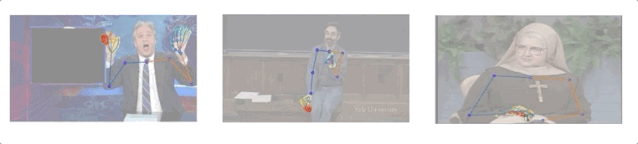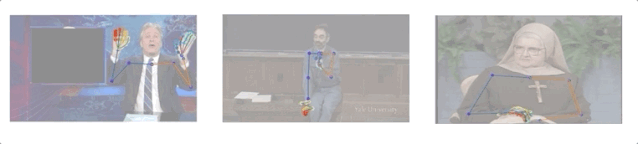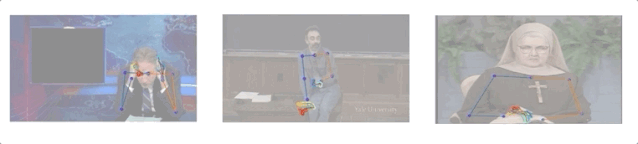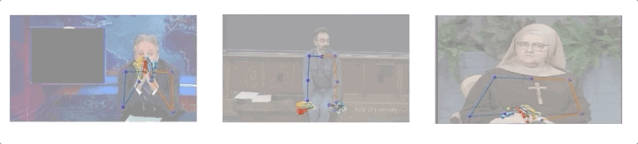
演讲视频数据集
他们使用现有的算法生成代表说话者手臂和手位置的骨架图形。然后他们用这些数据训练了自己的算法,这样AI就可以根据说话者的新音频来预测手势。

图1:从语音到手势的转换的示例结果。由下往上:输入音频、由我们的模型预测的手臂和手的姿态,以及由Caroline Chan等人在“Everybody Dance Now”论文中提出的方法合成的视频片段。
研究人员表示,在定量比较中,生成的手势比从同一说话者者随机选择的手势更接近现实,也比从一种不同类型的算法预测的手势更接近现实。
图2:特定于说话者的手势数据集
说话者的手势也是独特的,对一个人进行训练并预测另一个人的手势并不奏效。将预测到的手势输入到现有的图像生成算法中,可以生成半真实的视频。
研究团队表示,他们的下一步是不仅根据声音,还根据文字稿来预测手势。该研究潜在的应用包括创建动画角色、动作自如的机器人,或者识别假视频中人的动作。
为了支持对手势和语音之间关系的计算理解的研究,他们还发布了一个大型的个人特定手势视频数据集。
方法详解:两阶段从语音预测视频
给定原始语音,我们的目标是生成说话者相应的手臂和手势动作。
我们分两个阶段来完成这项任务——首先,由于我们用于训练的唯一信号是相应的音频和姿势检测序列,因此我们使用L1回归到2D关键点的序列堆栈来学习从语音到手势的映射。
其次,为了避免回归到所有可能的手势模式的平均值,我们使用了一个对抗性鉴别器,以确保产生的动作相对于说话者的典型动作是可信的。
任何逼真的手势动作都必须在时间上连贯流畅。我们通过学习表示整个话语的音频编码来实现流畅性,该编码考虑了输入语音的完整时间范围s,并一次性(而不是递归地)预测相应姿势的整个时间序列p。
我们的完全卷积网络由一个音频编码器和一个1D UNet转换架构组成的,如图3所示。
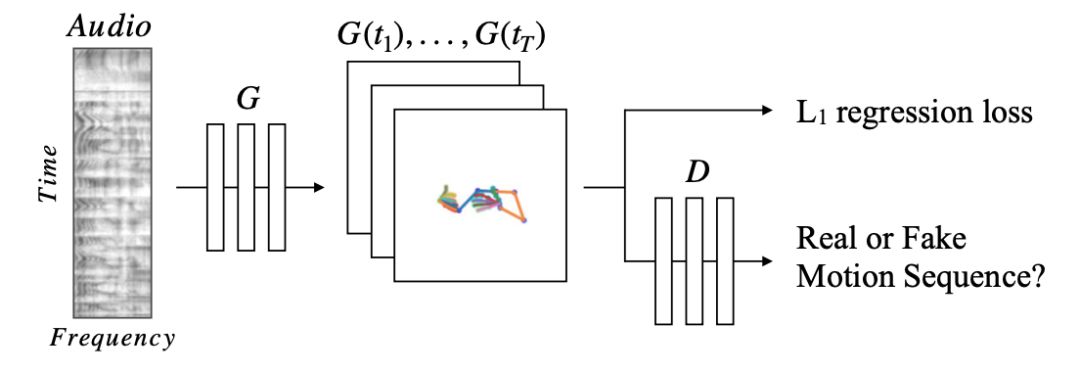
图3:语音到手势的翻译模型。
一个 convolutional audio encoder对2D谱图进行采样并将其转换为1D信号。然后,平移模型G预测相应的2D姿势序列堆栈。对真实数据姿势的L1回归提供了一个训练信号,而一个对抗性辨别器D则确保预测的动作既具有时间一致性,又符合说话者的风格。
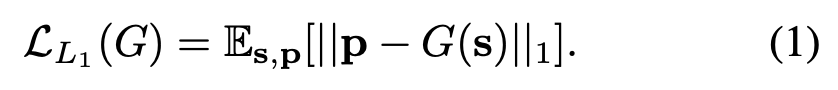
我们使用UNet架构进行转换,因为它的bottleneck为网络提供了过去和未来的时间上下文,而skip connections允许高频时间信息通过,从而能够预测快速移动。
定量和定性结果
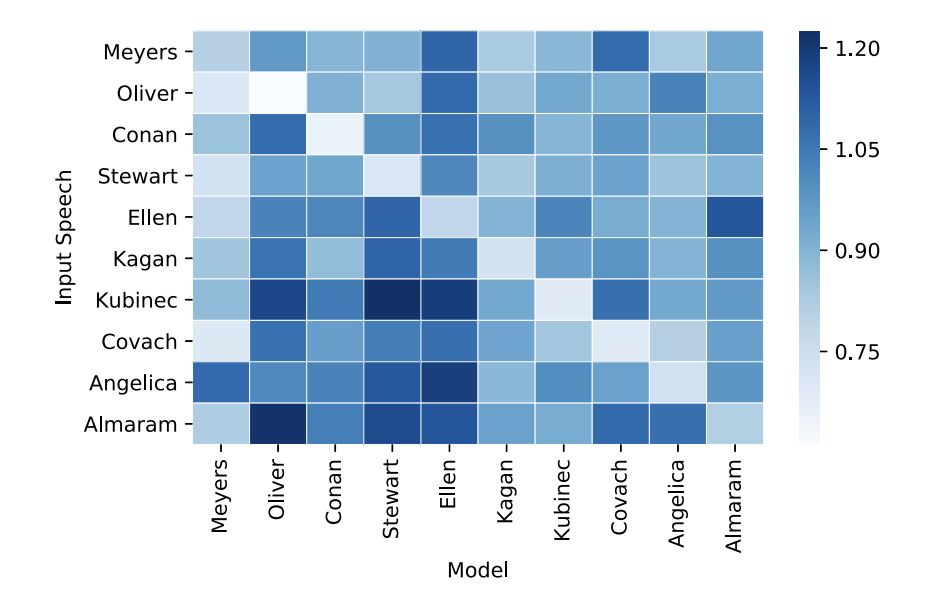
图4:我们训练过的模型是特定于人的。对于每个说话者的音频输入(行),我们应用所有其他单独训练的说话者模型(列)。颜色饱和度对应于待测集上的L1损耗值(越低越好)。对于每一行,对角线上的项都是颜色最浅的,因为模型使用训练对象的输入语音效果最好。
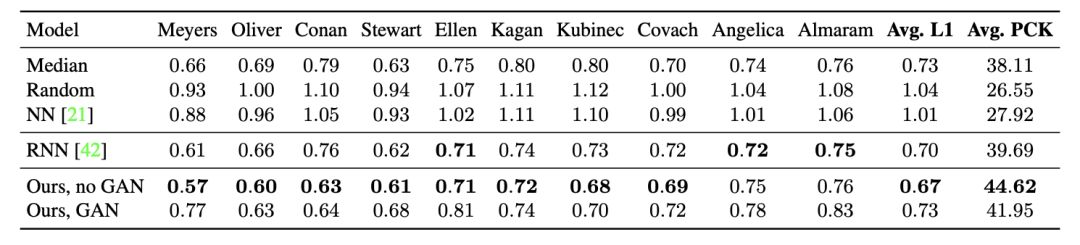
表1:在测试集上使用L1损失的语音到手势转换任务的定量结果(越低越好)

图5:语音到手势转换的定性结果。我们展示了Dr. Kubinec(讲师)和Conan O’Brien(节目主持人)的输入音频频谱图和预测手势。
-
语音
+关注
关注
3文章
388浏览量
38202 -
鉴别器
+关注
关注
0文章
8浏览量
8786 -
AI算法
+关注
关注
0文章
253浏览量
12387
原文标题:你说话时的肢体动作,AI仅凭声音就能预测 | CVPR 2019
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【书籍评测活动NO.55】AI Agent应用与项目实战
中国移动与南京大学合作研发高保真2D数字人说话系统
将AIC33的DIN和DOUT脚用短路的方式实现自环时,说话的声音稍微大点的时候,会在声音上叠加一个“噼啪”声,为什么?
将TPA31102D2板的音频输入与SPEAKER芯片连接时,说话声很小失真很厉害,为什么?
可以将一个TLV320AIC3101的输入与输出端口的左右声道分开使用吗?
BitEnergy AI公司开发出一种新AI处理方法
ai大模型和算法有什么区别
基于神经网络的呼吸音分类算法
云知声说话人识别引擎获得HUAWEI COMPATIBLE证书及认证徽标的使用权







 工商网监
工商网监
评论