 CapsNet再升级!堆栈式胶囊自编码器面世
CapsNet再升级!堆栈式胶囊自编码器面世

2017 年,Geoffrey Hinton 在论文《Dynamic Routing Between Capsules》中提出 CapsNet 引起了极大的关注,同时也提供了一个全新的研究的方向。今日,CapsNet 的作者 Sara Sabour、Hinton 老爷子联合牛津大学的研究者提出了胶囊网络的改进版本——堆栈式胶囊自编码器。这种胶囊自编码器可以无监督地学习图像中的特征,并在无监督分类任务取得最佳或接近最佳的表现。这也是胶囊网络第一次在无监督领域取得新的突破。
综述
一个目标可以被看做是一组相互关联的部件按照几何学形式组合的结果。利用这种几何关系去重建目标的系统应当对视点的变化具有鲁棒性,因为其本质的几何关系不应随着观察视角的变化而发生改变。
本文中,研究人员描述了一种无监督的胶囊网络。其中,观察组成目标所有部件的神经编码器被用来推断目标胶囊的存在和姿态。编码器通过解码器的反向传播方法训练。
训练中,解码器使用姿态预测来预测每个已发现部件的姿态。这些部件是直接从图像中被发现的,同样也是使用神经编码器,该编码器推断这些部件及它们的仿射变换。
而对应的解码器将每个图像像素建模为由仿射变换部件做出的预测混合。研究人员从目标和目标部件的胶囊中学习无标签数据,然后将这些目标胶囊的存在向量进行聚类。
得知这些聚类的名称时,研究人员在 SVHN 和 MNIST 数据集上获得了当前最佳的无监督分类结果,准确率分别为 55% 和 98.5%。
本文提出了堆栈式胶囊自编码器(SCAE),该编码器包含两个阶段。在第一阶段,部件胶囊自编码器(PCAE)将图像分割为组成部分,推断其姿态,并将每个图像像素重建为变换组件模板的像素混合。
在第二阶段,目标胶囊自编码器(OCAE)尝试将发现的部件及其姿态安排在一个更小的目标集合中。这个目标集合对每个部件进行预测,从而解释每个部件的姿态。通过将它们的姿态——目标-观察者关系(OV)和相关的目标-部件关系(OP)相乘,每个目标胶囊都会贡献这些混合的一部分。
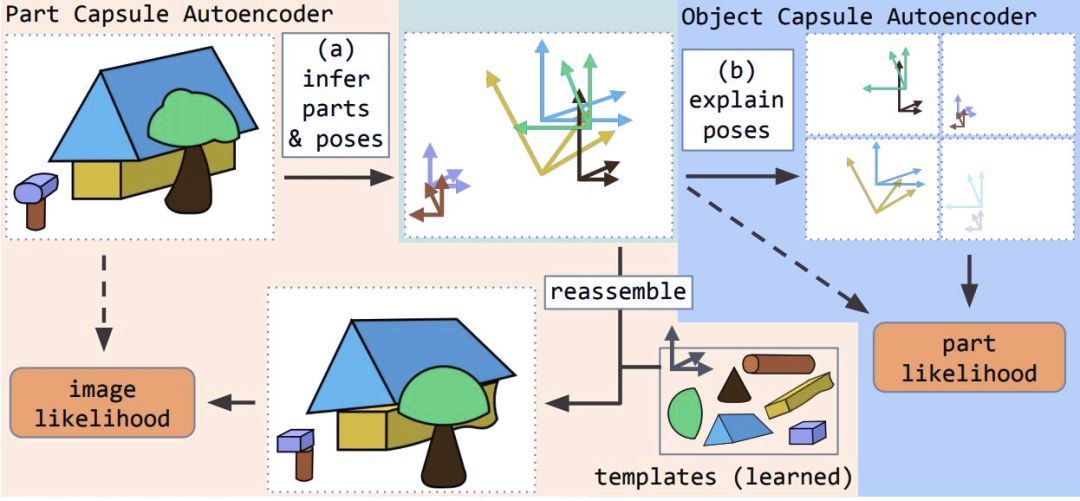
堆栈式胶囊自编码器的工作原理
堆栈式胶囊自编码器在使用未标注数据训练时捕捉所有目标和它们部件之间的空间关系。目标胶囊存在概率的向量倾向于组成紧密的聚类。
当给每个聚类一个分类时,其可以在无监督分类任务上达到当前最佳效果,如 SVHN 数据集上的 55% 和 MNIST 数据集上的 98.5%。以上结果还可以分别提升到 67% 和 99%,而且只需学习不到 300 个参数。
模型架构
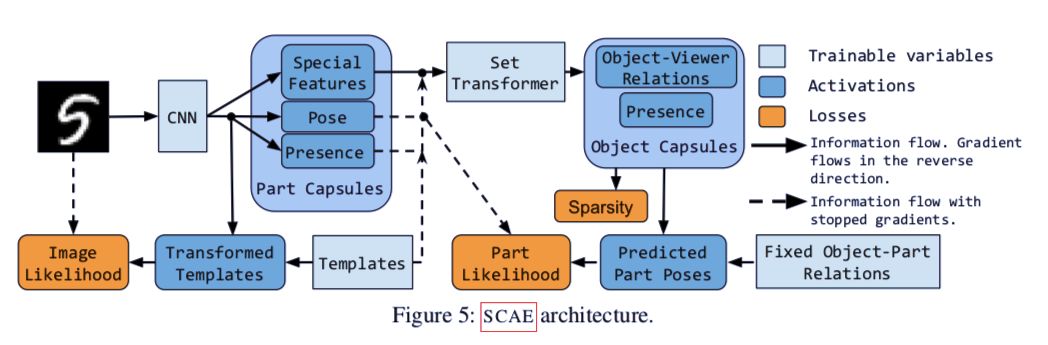
堆栈式胶囊自编码器的结构
堆栈式胶囊自编码器的两个组成部分为:部件胶囊自编码器(PCAE)和目标胶囊自编码器(OCAE)。在下文中,论文首先介绍了集群自编码器(CCAE),通过一系列数学公式说明自编码器如何分解图像中的部件的过程,然后由此引出堆栈式胶囊自编码器的两个组成部分。
集群自编码器

图 2:使用集群自编码器对不同形状的点进行聚类的示意图。
论文首先介绍了集群自编码器,通过这种结构的数学原理,引出堆栈式胶囊自编码器的结构。令 {x_m | m = 1, . . . , M } 为一组二维的输入点,每个点属于一个集群(见图2)。首先使用Set Transformer将所有的输入点(相当于部件胶囊)编码进k个目标胶囊中,Set Transformer是一种基于注意力机制的、有置换不变性的编码器h^cap (Lee et al., 2019) 。
一个目标胶囊 k 包括一个胶囊特征向量 c_k(其存在概率 a_k ∈ [0, 1])和一个 3 × 3 的目标-观察者(OV)关系矩阵。关系矩阵代表着目标(集群)和观察者之间关系的仿射变换。
需要注意的是,每个目标胶囊每次只能代表一个目标。每个目标胶囊都使用一个独立的多层感知机 h_k^part 从胶囊特征向量 c_k 中预测 N ≤ M 个候选部件。
每个候选由条件概率 a_k,n ∈ [0, 1] (当其存在),一个关联标量的标准差λ_k,n,以及一个 3 × 3 的目标-部件(OP)关系矩阵组成。这些代表着目标胶囊和候选部件的仿射变换。
候选预测 μ_k,n 根据目标胶囊 OV 和候选 OP 矩阵相乘得来。然后,研究人员将每个输入部件建模为高斯混合模型,其中μ_k,n 和 λ_k,n 是各向同性组件的中心和标准差。其标准公式如下:

集群胶囊编码器的公式。论文通过举出集群胶囊编码器的例子,用于说明目标胶囊编码器和它的区别。
部件胶囊自编码器
如果要将图像分解为组成部件的集合关系,就需要首先推断图像是由哪些部件组成的,同时也需要了解观察者和这些部件之间的关系(称之为他们的姿态)。
在本研究中,每个部件胶囊都有六个维度的自由姿态,一个存在变量,和一个独特的特征。研究人员把部件发现问题视为自编码:编码器学习去推断不同部件胶囊的姿态和存在,而解码器学习每个部件的图像模板。
模板对应的部件是使用其姿态的仿射变换,而这些变换过的模板的像素点被用来为每个图像像素创建单独的混合模型。在部件胶囊自编码器后是目标胶囊自编码器。
令 y ∈ [0, 1]^h×w×c 为图像。研究人员将部件胶囊的数量限定在 M 之内。对于每个部件胶囊,他们使用一个编码器去推断姿态 x_m ∈ R^6,存在概率 d_m ∈ [0, 1],以及特殊特征 z_m ∈ R^c_z。
虽然后者不会直接参与图像重建,但是会将对应部件的特殊信息提供给目标胶囊自编码器。他们会通过目标胶囊自编码器使用反向传播微分的方式训练。
当前条件下,不允许图像中同一种类型的部件多次出现,从而导致部件胶囊不会在空间中被复制(尽管它们可能会)。然而,确实需要分辨出所有出现在图像中的部件,因此编码器会采用带有从下到上(bottom-up)注意力机制的卷积神经网络。
对于每个胶囊 k,其预测一个特征矩阵 e^k,特征矩阵是 6(姿态)+1(存在)+c_z(特殊特征)的胶囊参数,其空间维度是 h_e × w_e,以及一个单通道注意力层 a_k。
最终,该胶囊的参数计算公式是 。softmax 是对空间维度上的计算。这种计算有点类似于全局平均池化,但是允许一些空间点比其他点对最终结果的权重影响更大。研究人员将其称为注意力池化(attention-based pooling)。
。softmax 是对空间维度上的计算。这种计算有点类似于全局平均池化,但是允许一些空间点比其他点对最终结果的权重影响更大。研究人员将其称为注意力池化(attention-based pooling)。
图像的像素点被建模为独立的高斯混合模型。对于每个像素点,研究人员采用其对应的变换模板,并将其视为有着恒定方差的各向同性高斯组件的中心点。其混合概率对部件胶囊的存在概率和在该位置的色值函数 (c 指的是图像的通道数)都是成比例的。
(c 指的是图像的通道数)都是成比例的。

部件胶囊自编码器的公式推导过程
目标胶囊自编码器(OCAE)
下一步是从已经发现的部件中寻找目标。因此,需要使用相连的姿态 x_m,特殊特征 z_m,以及平滑化的模板 T_m(通过将部件胶囊的特征进行转化)。这些将会成为目标胶囊自编码器的输入,这里和集群自编码器有一些不同。
首先,研究人员将部件胶囊的存在概率 d_m 输入目标胶囊自编码器——由于平衡注意力机制,避免将缺失点考虑在内。
其次,d_m 同时用于衡量部件胶囊的对数似然 cf。另外,除了特殊特征外,不对其他目标胶囊自编码器的输入计算梯度,以便提升训练的稳定性,并避免隐变量崩溃。
最后,通过部件胶囊自编码器发现的部件有着独立的特征(模板和特殊特征)。因此,每个部件姿态都可以被解释为是目标胶囊预测的独立混合——即每个目标胶囊都做出 M 个候选预测 V_k,1:M,或者对每个部件做出一个候选预测。
最终,部件胶囊的似然公式是:


图 3:从MNIST(左)和SVHN(中)和CIFAR 10(右)学习到的模板。

图 4:展示了胶囊自编码器对MNIST数据集的重建过程。a)MNIST图像;b)红色的部件胶囊和绿色的目标胶囊在重建中的组合;c)实际参与重建的被激活胶囊;d)根据图像捕捉到的信息;e)部件的仿射变换,用于展示其重建图像的过程。
模型性能评估
堆栈式胶囊自编码器使用仿射变换,这样可以使编码器的输入由一组较小的变换目标或部件解释。
无监督分类评价
研究人员在 MNIST、SVHN 和 CIFAR 10 数据集上进行了测试,并将目标胶囊的存在打上类别标签。他们使用了多种评价方法。
在部件胶囊编码器上,研究人员在 MNIST 数据集上使用了 24 个单通道,11 × 11 的模板,在 SVHN 和 CIFAR 10 上则分别使用了 32 个 3 通道,14 × 14 的模板。
对于后两个数据集的图像,研究人员进行了 Sobel 过滤,作为重建的目标。对于目标胶囊编码器,研究则分别使用了 24、32 和 64 个目标胶囊。
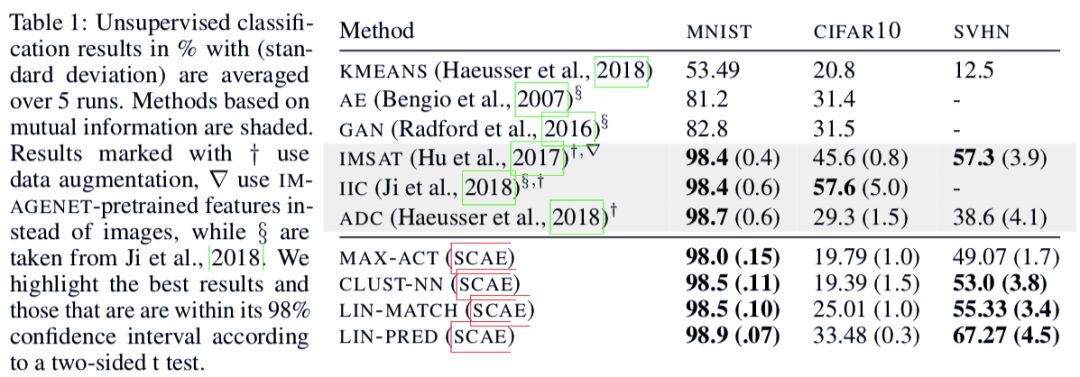
表 1:运行五次后取平均的无监督分类结果和标准差。
-
编码器
+关注
关注
45文章
4011浏览量
143326 -
无监督学习
+关注
关注
1文章
17浏览量
2904
原文标题:Hinton老爷子CapsNet再升级,结合无监督,接近当前最佳效果
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
绝对式旋转编码器常用什么类型磁铁?

磁阻式磁性编码器工作原理及关键技术分析-艾毕胜电子
磁铁在编码器中的作用与应用

磁性编码器磁环的作用有哪些?

探索AEDR - 9930EL:三通道反射式增量线性编码器的卓越性能
探索Broadcom AEAT - 901B系列增量式磁编码器:特性、参数与应用
探索AEAT - 901B系列增量式磁编码器:特性、应用与设计要点
高精度绝对式编码器:工业自动化的“智慧之眼”

相对式编码器:工业自动化领域的“性价比之王”


增量式编码器工作原理是什么?

绝对值编码器与增量式编码器相比有哪些优势?
增量型编码器与绝对值型编码器怎么选择?
Bourns 扩展增量式编码器产品线,旋转寿命功能再升级




评论