 深度学习如何继续革命?
深度学习如何继续革命?
近日,图灵奖得主、深度学习巨头Geoffrey Hinton和Yann LeCun在ACM FCRC 2019上发表了精彩演讲。
二人分别在大会上做了题为《深度学习革命》和《深度学习革命:续集》的精彩演讲。目前视频已经公开:
Geoffrey Hinton:《深度学习革命》
Geoffrey Hinton
Hinton表示,自从20世纪50年代开始,人工智能存在两种范式:分别是逻辑启发的方法和生物学启发的方法。
逻辑启发的方法(The logic-inspired approach):智能的本质是使用符号规则来操纵符号表达。 我们应该专注于推理。
生物学启发的方法(The biologically-inspired approach):智能的本质是学习神经网络中连接的优势。 我们应该专注于学习和感知。
不同的范式便使得最终的目标有所不同。因此,在内部表示(internal representation)方面也存在着两种观点:
内部表示是符号表达式。程序员可以用一种明确的语言把它们交给计算机;可以通过对现有表示应用规则派生新的表示。
内部表示与语言完全不同。它们是神经活动的向量(big vectors);它们对神经活动的其他载体有直接的因果影响;这些向量是从数据中学到的。
由此也导致了两种让计算机完成任务的方式。
首先是智能设计:有意识地精确计算出你将如何操纵符号表示来执行任务,然后极其详细地告诉计算机具体要做什么。
其次是学习:向计算机展示大量输入和所需输出的例子。让计算机学习如何使用通用的学习程序将输入映射到输出。
Hinton举了一个例子:人们花了50年的时间,用符号型人工智能(symbolic AI)来完成的任务就是“看图说话”。
针对这项任务,人们尝试了很长时间来编写相应的代码,即便采用神经网络的方法依旧尝试了很长一段时间。最终,这项任务得到很好解决的方法竟然是基于纯学习的方法。
因此,对于神经网络而言,存在如下的核心问题:
包含数百万权重和多层非线性神经元的大型神经网络是非常强大的计算设备。但神经网络能否从随机权重开始,并从训练数据中获取所有知识,从而学习一项困难的任务(比如物体识别或机器翻译)?
针对这项问题,前人们付出了不少的努力:



针对如何训练人工神经网络,Hinton认为分为两大方法,分别是监督训练和无监督训练。
监督训练:向网络显示一个输入向量,并告诉它正确的输出;调整权重,减少正确输出与实际输出之间的差异。
无监督训练:仅向网络显示输入;调整权重,以便更好地从隐含神经元的活动中重建输入(或部分输入)。

而反向传播(backpropagation algorithm)只是计算权重变化如何影响输出错误的一种有效方法。不是一次一个地扰动权重并测量效果,而是使用微积分同时计算所有权重的误差梯度。
当有一百万个权重时,反向传播方法要比变异方法效率高出一百万倍。
然而,反向传播算法却又让人感到失望。
在20世纪90年代,虽然反向传播算法的效果还算不错,但并没有达到人们所期待的那样——深度网络训练非常困难;在中等规模的数据集上,一些其他机器学习方法甚至比反向传播更有效。
符号型人工智能的研究人员称,期望在大型深层神经网络中学习困难的任务是愚蠢的,因为这些网络从随机连接开始,且没有先验知识。
Hinton举了三个非常荒诞的理论:

而后,深度学习开始被各种拒绝:
2007年:NIPS program committee拒绝了Hinton等人的一篇关于深度学习的论文。因为他们已经接收了一篇关于深度学习的论文,而同一主题的两篇论文就会“显得过多”。
2009年:一位评审员告诉Yoshua Bengio,有关神经网络的论文在ICML中没有地位。
2010年:一位CVPR评审员拒绝了Yann LeCun的论文,尽管它击败了最先进的论文。 审稿人说它没有告诉我们任何关于计算机视觉的信息,因为一切都是“学到的”。
而在2005年至2009年期间,研究人员(在加拿大!)取得了几项技术进步,才使反向传播能够更好地在前馈网络中工作。
到了2012年,ImageNet对象识别挑战赛(ImageNet object recognition challenge)有大约100万张从网上拍摄的高分辨率训练图像。
来自世界各地的领先计算机视觉小组在该数据集上尝试了一些当时最好的计算机视觉方法。其结果如下:

这次比赛的结果后,计算机视觉相关的组委会们才突然发觉原来深度学习是有用的!
Hinton在演讲中讨论了一种全新的机器翻译方式。
对于每种语言,我们都有一个编码器神经网络和一个解码器神经网络。编码器按原句中的单词顺序读取(它最后的隐藏状态代表了句子所表达的思想)。而解码器用目标语言表达思想。
自2014年年以来,神经网络机器翻译得了很大的发展。

接下来,Hinton谈到了神经网络视觉的未来。
他认为卷积神经网络获得了巨大的胜利,因为它若是在一个地方能行得通,在其它地方也能使用。但它们识别物体的方式与我们不同,因此是对抗的例子。
人们通过使用对象的坐标系与其部分的坐标系之间的视点不变几何关系来识别对象。Hinton认为神经网络也能做到这一点(参考链接:arxiv.org/abs/1906.06818)。
那么,神经网络的未来又是什么呢?
Hinton认为:
几乎所有人工神经网络只使用两个时间尺度:对权重的缓慢适应和神经活动的快速变化。但是突触在多个不同的时间尺度上适应。它可以使快速权重(fast weight)进行short-term memory将使神经网络变得更好,可以改善优化、可以允许真正的递归。
Yann LeCun演讲:《深度学习革命:续集》
Yann LeCun

Jeff刚才提到了监督学习,监督学习在数据量很大时效果很好,可以做语音识别、图像识别、面部识别、从图片生成属性、机器翻译等。
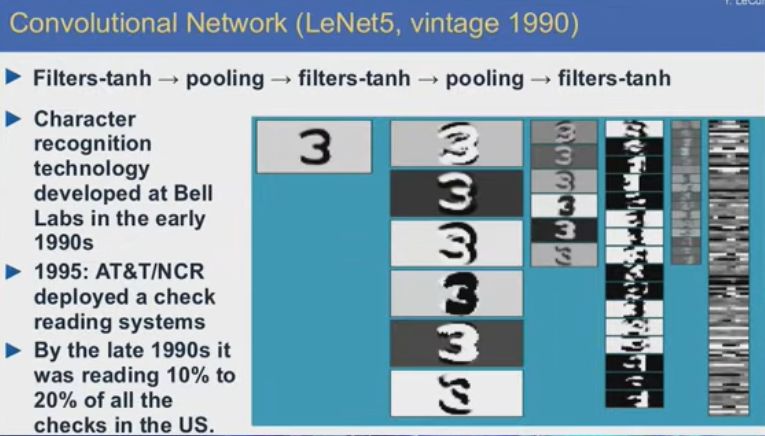
如果神经网络具有某些特殊架构,比如Jeff在上世纪八九十年代提出的那些架构,可以识别手写文字,效果很好,到上世纪90年代末时,我在贝尔实验室研发的这类系统承担了全美手写文字识别工作的10%-20%,不仅在技术上,而且在商业上也是一个成功。
到后来,整个社群一度几乎抛弃了神经网络,一方面是因为是缺乏大型数据集,还有部分原因是当时编写的软件过于复杂,投资很大,还有一部分原因是当时的计算机速度不够快,不足以运行其他所有应用。
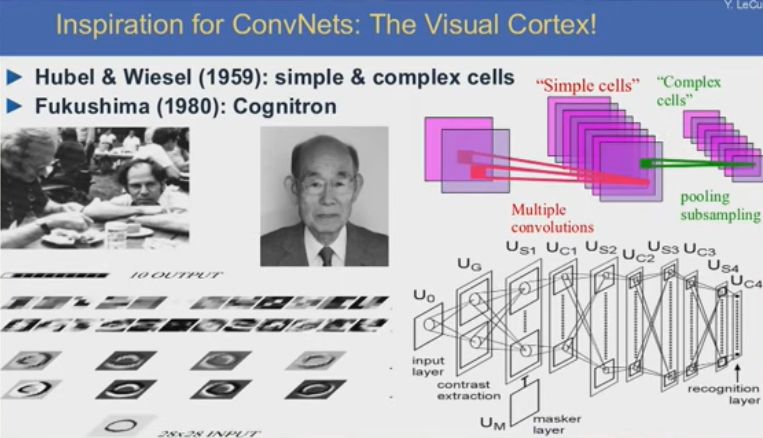
卷积神经网络其实是受到了生物学的启发,它并不是照搬生物学,但确实从中得到很多启发,比如视觉皮层的结构,以及在学习信号处理时自然而然产生的一些观点,比如filtering是处理音视频信号的好办法,而卷积是filtering的一种方式。这些经典理念早在上世纪五六十年代就由Hubel和wiesel等人在神经科学领域提出,日本科学家Fukushima在上世纪80年代对其也有贡献。
我从这些观点和成果中受到启发,我发现可以利用反向传播训练神经网络来复现这些现象。卷积网络的理念是,世界上的物体是由各个部分构成的,各个部分由motif构成,而motif是由材质和边缘的基本组合,边缘是由像素的分布构成的。如果一个层级系统能够检测到有用的像素组合,再依次到边缘、motif、最后到物体的各个部分,这就是一个目标识别系统。
层级表示不仅适用于视觉目标,也适用于语音、文本等自然信号。我们可以使用卷积网络识别面部、识别路上的行人。

在上世纪90年代到2010年左右,出现了一段所谓“AI寒冬”,但我们没有停下脚步,在人脸识别、行人识别,将机器学习用在机器人技术上,使用卷积网络标记整个图像,图像中的每个像素都会标记为“能”或“不能”被机器人穿越,而且数据收集是自动的,无需手动标记。
几年之后,我们使用类似的系统完成目标分割任务,整个系统可以实现VGA实时部署,对图像上的每个像素进行分割。这个系统可以检测行人、道路、树木,但当时这个结果并未马上得到计算机社群的认可。

最近的视觉识别系统的一个范例是Facebook的“全景特征金字塔网络”,可以通过多层路径提取图像特征,由多层路径特征生成输出图像,其中包含图像中全部实例和目标的掩模,并输出分类结果,告诉你图像中目标的分类信息。不仅是目标本身的分类,还包括背景、材质等分类,比如草地、沙地、树林等。可以想象,这种系统对于自动驾驶会很有用。
医疗成像及图像分割
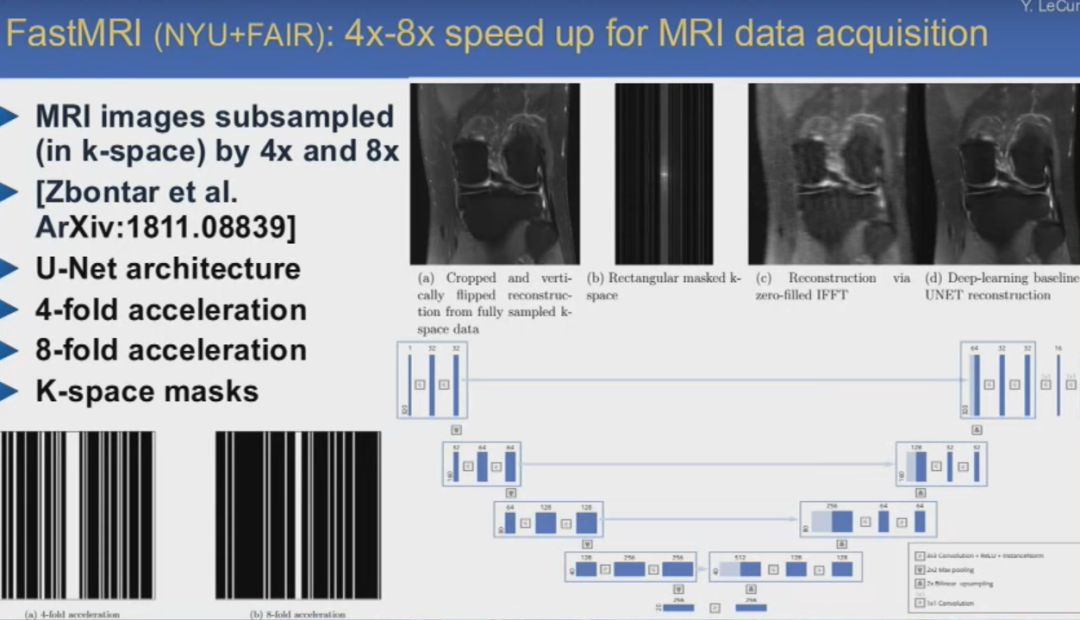
卷积网络对于医学成像应用也很有帮助。与上面提到的网络类似,它也分为解码器部分,负责提取图像特征,另一部分负责生成输出图像,对其进行分割。
神经网络机器翻译
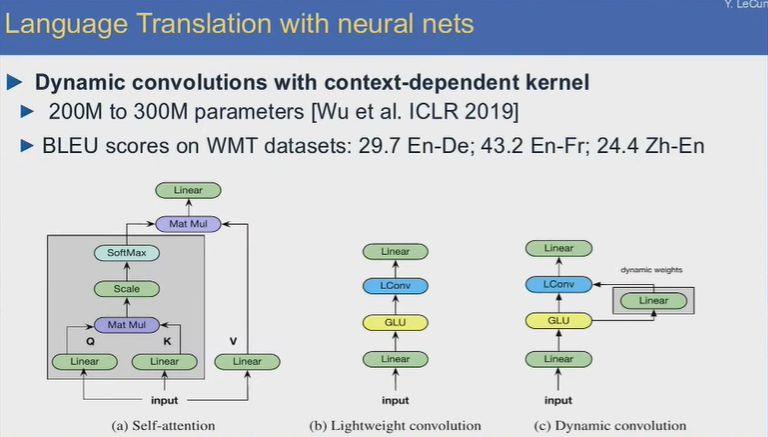
在翻译应用上,采用了许多网络架构上的创新,如自注意力机制、轻量卷积、动态卷积等,实现基于语境的动态卷积网络内核。在ICML2019上的最新机器翻译卷积网络模型,其参数数量达到200M至300M,WMT数据集上的BLEU得分:英语-德语29.7,英语-法语43.2,汉语-英语24.4。
自动驾驶系统

游戏
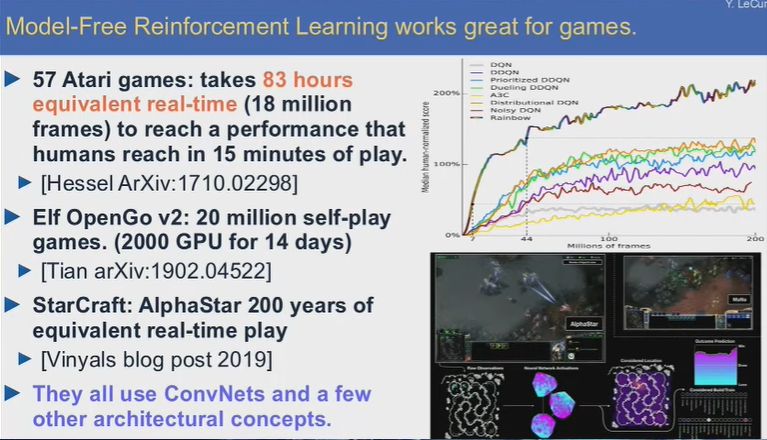
无模型强化学习很适合游戏领域应用。现在强化学习领域的一大问题就是数据的缺乏,使用强化学习训练系统需要大量的重复试验和试错,要达到人类训练15分钟的水平,机器需要大概80小时的实时游戏,对于围棋来说,要达到超人的水平,机器需要完成大约2000万盘的自对弈。Deepmind最近的《星际争霸2》AI则完成了大约200年的游戏时间。

这种海量重复试验的方式在现实中显然不可行,如果你想教一个机器人抓取目标,或者教一台自动驾驶车学会驾驶,如此多的重复次数是不行的。纯粹的强化学习只能适用于虚拟世界,那里的尝试速度要远远快于现实世界。
这就引出了一个问题:为什么人和动物的学习速度这么快?
和自动驾驶系统不同,我们能够建立直觉上真实的模型,所以不会把车开下悬崖。这是我们掌握的内部模型,那么我们是怎么学习这个模型的,如何让机器学会这个模型?基本上是基于观察学会的。
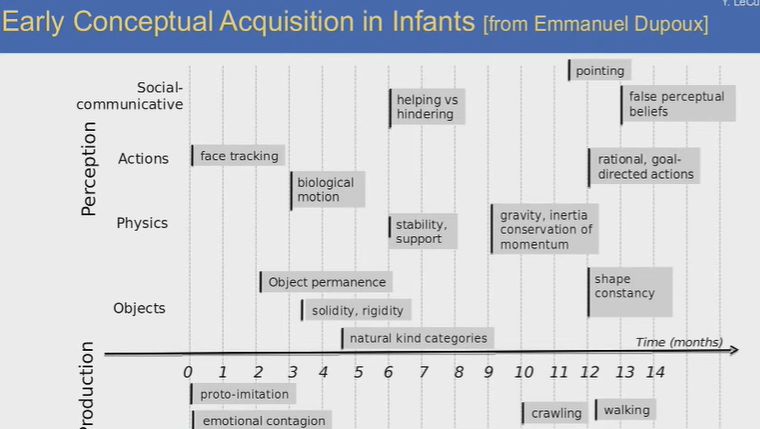
动物身上也存在类似的机制。预测是智能的不可或缺的组成部分,当实际情况和预测出现差异时,实际上就是学习的过程。

上图显示了婴儿学习早期概念和语言的过程。婴儿基本上是通过观察学习这个世界的,但其中也有一小部分是通过交流。
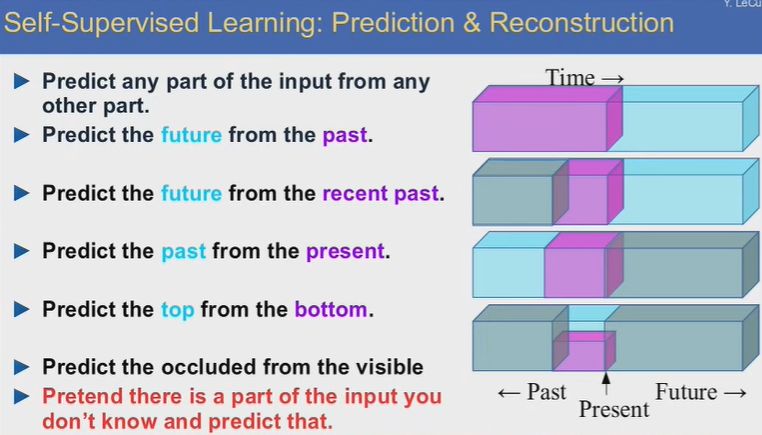
自监督学习:预测与重建
以视频内容预测为例,给定一段视频数据,从其中一段视频内容预测另外一段空白处的内容。自监督学习的典型场景是,事先不公布要空出哪一段内容,实际上根本不用真的留出空白,只是让系统根据一些限制条件来对输入进行重建。系统只通过观察来完成任务,无需外部交互,学习效率更高。
机器在学习过程中被输入了多少信息?对于纯强化学习而言,获得了一些样本的部分碎片信息(就像蛋糕上的樱桃)。对于监督学习,每个样本获得10-10000bit信息(蛋糕表面的冰层),对于半监督学习,每个样本可获得数百万bit的信息(整个蛋糕内部)。

自监督学习的必要性
机器学习的未来在与自监督和半监督学习,而非监督学习和纯强化学习。自监督学习就像填空,在NLP任务上表现很好(实际上是预测句子中缺失的单词),但在图像识别和理解任务上就表现一般。

为什么?因为这世界并不全是可预测的。对于视频预测任务,结果可能有多重可能,训练系统做出唯一一种预测的结果往往会得到唯一“模糊”的结果,即所有未来结果的“平均”。这并不是理想的预测。
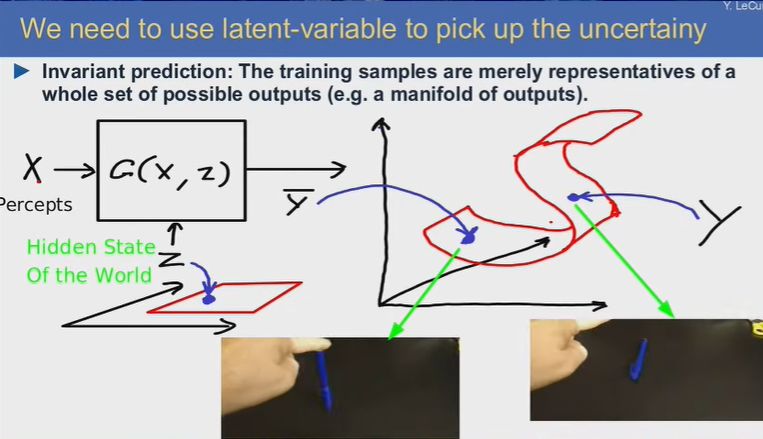
我们需要利用隐变量来处理不确定性。训练样本只是整个可能的输出集合的表示。

几百年以来,理论的提出往往伴随着之后的伟大发明和创造。深度学习和智能理论在未来会带来什么?值得我们拭目以待。
-
图灵
+关注
关注
1文章
41浏览量
9785 -
深度学习
+关注
关注
73文章
5527浏览量
121892
原文标题:图灵奖得主Hinton和 LeCun最新演讲:深度学习如何继续革命?
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
军事应用中深度学习的挑战与机遇
NPU在深度学习中的应用

AI大模型与深度学习的关系
FPGA做深度学习能走多远?
深度学习中的时间序列分类方法
深度学习中的无监督学习方法综述
深度学习与nlp的区别在哪
基于深度学习的小目标检测
深度学习中的模型权重
深度学习的基本原理与核心算法
深度学习常用的Python库
深度学习与传统机器学习的对比
深度解析深度学习下的语义SLAM






 工商网监
工商网监
评论