 赛灵思AI方案三大重点
赛灵思AI方案三大重点
低时延,低时延,低时延
加速整体应用,而非单项加速
匹配创新的速度,手慢无
01 最低时延的 AI 推断
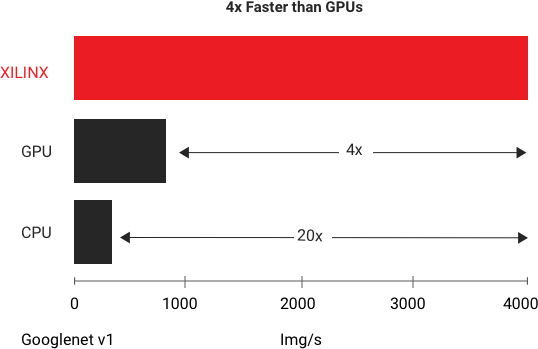
在数据中心 AI 平台上,对于低时延 AI 推断,赛灵思能以最低时延的条件下提供最高吞吐量,在 GoogleNet V1 上进行的标准基准测试当中,赛灵思 Alveo U250 可为实时推断提供比现有最快的 GPU 多出 4 倍的吞吐量。
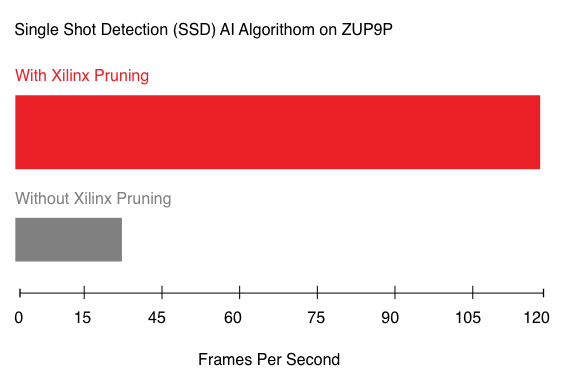
而在边缘 AI 平台,赛灵思方案利用 CNN 剪枝技术获得了 AI 推断性能的领导地位,比如,可实现 5-50 倍的网络性能优化;大幅增加 FPS 的前提下降低功耗。对于开发者来说,赛灵思支持 Tensorflow、Caffe 和 MXNet 等网络,并用赛灵思提供的工具链将网络部署到赛灵思的加速器上。
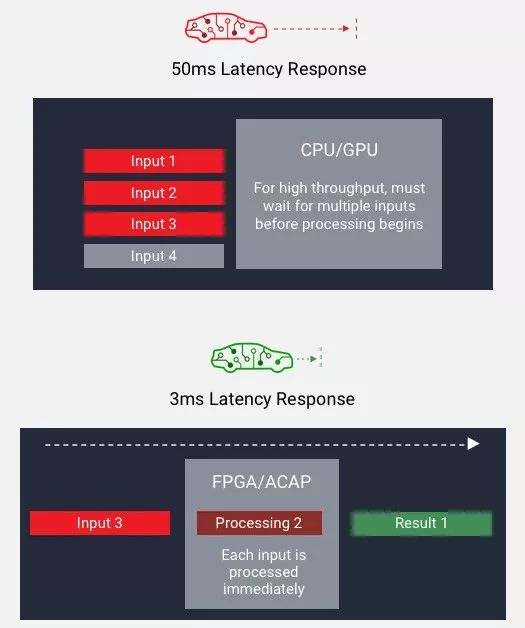
如下图所示,传统 CPU/GPU 只能在“高吞吐量”和“低时延”两者选择其一,如需低时延则无法满足大批量规模的吞吐量;而一旦需要使用大批量规模实现吞吐量,在处理之前,器件必须等待所有输入就绪之后再处理,从而导致高时延。而使用 FPGA,则可以采用小批量规模实现吞吐量,并在每个输入就绪之时开始处理,从而降低时延。
02 整体应用加速
通过将自定义加速器紧密耦合在动态架构芯片器件中,优化了 AI 推断,并对其它对性能有关键影响的功能进行硬件加速。
提供端对端的应用性能,该性能比 GPU 等固定架构 AI 加速器高很多;因为使用 GPU,在没有自定义硬件加速性能或效率的情况下,应用的其它性能关键功能须仍在软件中运行。

03 匹配 AI 创新的速度
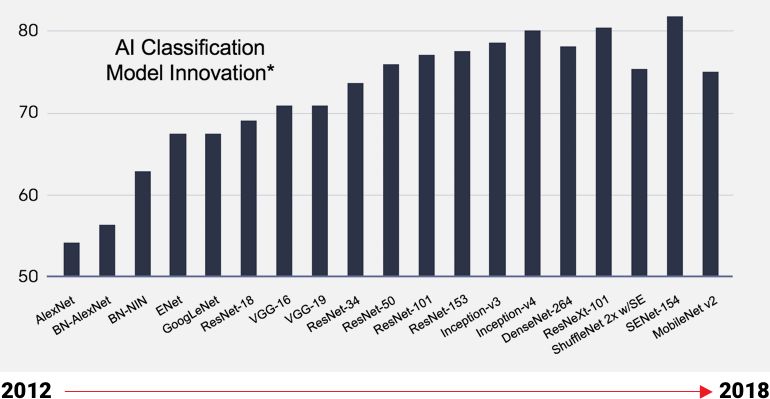
人工智能模型正在迅速发展,新算法层出不穷,灵活应变的芯片支持基于特定区领域架构(DSA)的设计,从而无需更换芯片,即可开始优化最新的人工智能模型。从而最大限度地匹配创新的速度,为客户赢得宝贵的 Time To Market。从下图可以看出,专用芯片开发周期长,在对 DSA 的支持上非常不友好,无法满足现阶段 AI 创新的更迭速度。
赛灵思是 FPGA、硬件可编程 SoC 及 ACAP 的发明者,旨在提供业界最具活力的处理器技术,实现自适应、智能且互连的未来世界。
-
cpu
+关注
关注
68文章
10855浏览量
211601 -
数据中心
+关注
关注
16文章
4764浏览量
72097 -
人工智能
+关注
关注
1791文章
47206浏览量
238279
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论