 爱尔兰贝尔实验室的研究人员开发出一款编码内核
爱尔兰贝尔实验室的研究人员开发出一款编码内核

作为首选的 5G 无线网络基础架构,大规模 MIMO 无线系统现已领跑整个行业。低时延预编码实现方案是充分利用多输入多输出 (MIMO) 方案多传输架构内在优势的关键。我们的团队利用赛灵思System Generator和简单可扩展的Vivado Design Suite构建了一款高速、低时延预编码内核。
借其固有的多用户空分复用传输能力,大规模 MIMO 系统可显著提高传统单天线用户设备和升级版多天线用户终端的信号干扰噪声比 (SINR)。这样不仅可获得更大的网络容量、更高的数据吞吐量,而且还能提高频谱利用率。
但是,大规模 MIMO 技术自身仍存在一些挑战。要使用该技术,电信工程师需要构建多个 RF 收发器和多个基于辐射式相控阵天线。他们还需要使用数字资源来执行所谓的预编码功能。
我们的解决方案是构建低时延、可扩展的频变预编码 IP;可以按照 Lego 方式将该 IP 核用于集中式和分布式 大规模 MIMO 架构。这个 DSP 研发项目的关键是高性能赛灵思 7 系列 FPGA以及带有 System Generator 和 MATLAB/Simulink 的赛灵思 Vivado Design Suite 2015.1 版本。
通用 MIMO 系统中的预编码
在蜂窝网络中,特定频率下每个发送器与接收器之间所谓的信道响应将在空中对普通 MIMO 发送器中辐射出来的用户数据流进行“重塑”。换句话说,不同数据流通往空域另一端的接收器的路径不同。由于频域中的“经历”不同,即使是相同的数据流有时也会有不同表现。
这种固有的无线传输现象等同于将具有特定频率响应的有限脉冲响应 (FIR) 滤波器应用于每个数据流,这样无线信道就会产生频率“失真”,进而导致系统性能不佳。如果我们将无线信道视为一个大型黑盒,那么在系统级只有输入(发送器输出)和输出(接收器输入)是显而易见的。我们可在 MIMO 发送器侧添加一个具有逆信道响应的预均衡黑盒,以预先补偿信道的黑盒效应,然后,级联系统会在接收器设备上提供合理的“校正”数据流。
我们将这种预均衡方法称为预编码,从根本上说,就是在发送器链上应用一组“重塑”系数。例如,如果我们用 NTX (发送器数量)天线发送 NRX 个独立数据流,那么我们在将 NTX 个 RF 信号辐射到空中之前需要通过N 次临时复数线性卷积运算及相应的合并运算来执行预均衡编码。
复数线性卷积的直接、低时延实现方法是使用时域中的复数 FIR 离散数字滤波器。
系统功能要求
在低时延预编码 IP 的创建过程中, 我的团队面临一系列基本要求。
我们必须用不同系数组将一个数据流预编码为多分支的并行数据流。
我们需要在每个分支上放置一个 100 + 抽头长度的复数非对称 FIR 函数,以提供合适的预编码性能。以提供合适的预编码性能。
需要经常对预编码系数进行更新。
所设计的内核必须易于更新和扩展,以支持不同的可扩展系统架构。
在给定资源约束下,预编码时延应该尽可能低。
此外,除了注意满足特定设计的功能要求以外,我们还要考虑硬件资源约束。换句话说,建立节约资源的算法实现方案对于有限的关键硬件资源(例如赛灵思 FPGA 上的专用硬件乘法器 DSP48s)大有裨益。
高速、低时延预编码 (HLP) 内核设计
本质上讲,在开发具备该特质的设计之前必须先满足可扩展性这个关键特性。可扩展设计能确保长期的基础架构可持续演进,并在短期实现最佳的低成本部署策略。可扩展性源自模块化。依照这个理论,我们使用赛灵思 System Generator 在 Simulink 中创建了一个模块化的通用复数 FIR 滤波器评估平台。

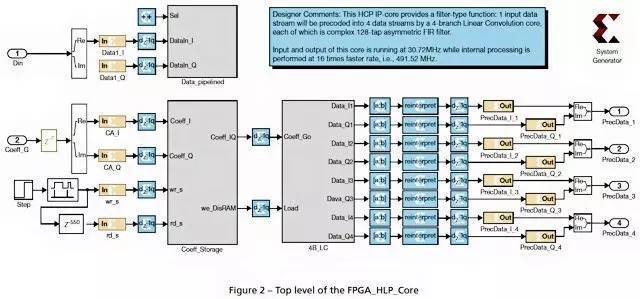
图 1 所示为顶层系统架构。Simulink_HLP_Core 在 Simulink 中用离散数字滤波器模块描述多分支复数 FIR 滤波器;FPGA_HLP_Core 在 System Generator 中用赛灵思资源模块实现多分支复数 FIR 滤波器,如图 2 所示。
不同的 FIR 实现架构会产生不同的 FPGA 资源使用。表 1 对不同实现架构中 128 抽头复数非对称 FIR 滤波器中所使用的复数乘法器 (CM) 进行了比较。我们假设 IQ 数据速率是 30.72Msps(20 MHz 带宽 LTE-Advanced 信号)。
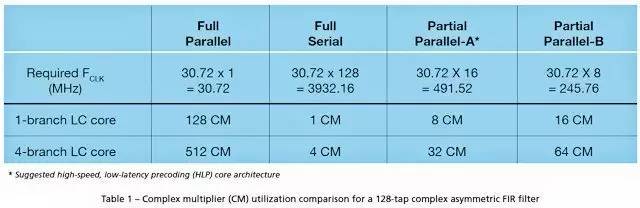
全并行实现架构非常简单直接,可轻松地映射至直接型 FIR 架构,但这种实现架构需要使用大量 CM 资源。全串行实现架构使用的 CM 资源数量最少,得益于其能以时分复用 (TDM) 方式与 128 个操作共享相同的 CM 单元。但其运行时钟速率是最先进的 FPGA 都不可能达到的。
比较现实的解决方案是选用部分并行实现架构,该架构将连续的长滤波器链分成几段并行级。表 1 给出了两个实例。我们选择使用方案 A,因为该方案的 CM 使用量最少,而且时钟速率合理。事实上,我们可以通过控制数据速率、时钟速率和连续级数来决定最终的架构:
FCLK = FDATA×NTAP÷NSS
其中 N 和 N 代表滤波器长度和连续级的数量。然后,我们创建三个主要模块:
系数存储模块:我们使用高性能双端口 Block RAM 来存储需要加载到 FIR 系数 RAM 中的 IQ 系数。用户可以选择何时将系数上载到存储设备中以及何时通过 wr 和 rd 控制信号来更新 FIR 滤波器的系数。
数据 TDM 管线化模块:我们将采样率为 30.72 MHz 的输入 IQ 数据进行多路复用,以生成采样率更高的 8 个流水线 (NSS = 8)(采样率较高,为 30.72×128÷8 = 491.52 MHz)。然后,我们将这些数据流送入四分支的线性卷积 (4B-LC) 模块。
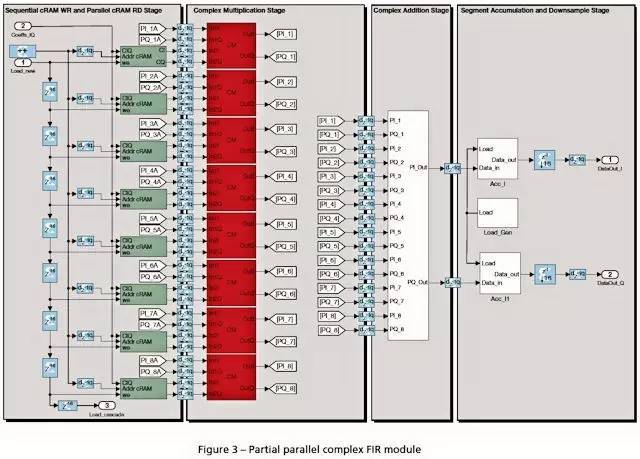
4B-LC 模块:该模块包含四条独立的复数 FIR 滤波器链,每条都利用相同的部分并行架构实现。例如,图 3 中给出的分支 1。分支 1 包含四个被寄存器隔离以获得更好时序特性的子处理级:FIR 系数 RAM (cRAM) 顺序写入和并行读取级;复数乘法级;复数加法级;以及分段累积和下采样级。为了把内核的 I/O 数量降到最低,我们的第一级就需要创建顺序写入操作以便以 TDM 方式从存储设备向 FIR cRAM 加载系数(每个 cRAM 包含 16 = 128/8 个 IQ 系数)。我们设计了并行读取操作用以同时将 FIR 系数送至 CM 内核。在复数乘法级,为将 DSP48 使用量减至最少,我们选择高效的、完全管线化的三重乘法器架构来执行复数乘法运算,代价是产生六倍的时延周期。接下来,复数加法级将 CM 的输出聚合成单个数据流。最后,分段累积和下采样级在 16 个时间周期内累积临时子流,以导出 128 抽头 FIR 滤波器的相应线性卷积结果,并降低高速数据流的采样速度以匹配本系统的数据采样率,即 30.72 MHz。
设计验证
我们分两步执行 IP 验证。首先,我们将 FPGA_HLP_Core 的输出与 Simulink 中的参考双精度多分支 FIR 内核进行比较。我们发现,在 16 位分辨率版本中,我们已成功实现小于 0.04% 的相对幅值误差。较大的数据宽度能提供更好的性能,但代价是消耗更多资源。
功能验证完成后,就需要验证芯片性能。因此,我们的第二个步骤是在 Vivado 设计套件 2015.1 中针对 Zynq-7000 All Programmable SoC 的 FPGA 架构(相当于一个 Kintex xc7k325tffg900-2)对所创建的 IP 进行综合与实现。凭借工具的综合与默认实现设置中具备的完整层级,我们创建了一个具有清晰注册层级的完全管线化设计,因而在 491.52 MHz 的内部处理时钟速率下不难实现所要求的时序。
可扩展性演示
我们设计的 HLP IP 便于用来创建更大的大规模 MIMO 预编码内核。表 2 列出了一些应用方案以及重要资源的使用情况。
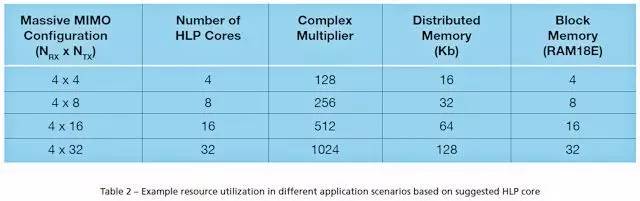
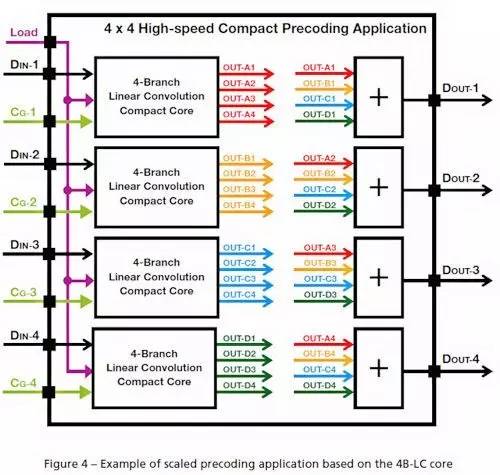
您需要一个额外的聚合级以提交最后的预编码结果。例如图 4 所示,通过插入四个 HLP 内核以及一个额外管线化数据聚合级,很容易构建一个 4x4 预编码内核。
高效和可扩展
我们已经介绍了如何利用赛灵思 System Generator 和 Vivado 设计工具快速构建 大规模 MIMO 预编码内核形式的高效、可扩展的DSP 线性卷积应用。
您既可以在部分并行架构中使用更多顺序级,也可以合理地增大处理时钟速率以更快速地实现任务操作,从而对该内核进行扩展,以便支持更长抽头的 FIR 应用。对于第二种情况,针对实际的实现架构找到目标器件的瓶颈和关键路径应该会有所帮助。然后,更好的方法将会是对硬件和算法进行协同优化以调节系统性能,例如针对硬件的使用开发出更小型预编码算法。
首先,我们着重开发具有最低时延的预编码解决方案。下一步,我们将探索一种替代解决方案以获得优化的资源使用与功耗。
-
内核
+关注
关注
4文章
1479浏览量
43129 -
编码
+关注
关注
6文章
1041浏览量
57198 -
5G无线网络
+关注
关注
0文章
5浏览量
5618
发布评论请先 登录
如何制作实验室人员物品管理系统
【FireBLE申请】无线智能实验室管理系统的研究
【OneNET麒麟座试用申请】实验室环境预警系统
Kilby实验室大揭秘
《编译原理_贝尔实验室_李建中译》pdf下载
美研究人员开发出一款能检测由压力导致疾病的可穿戴设备
曝美国贝尔实验室着手6G研究
美研究人员开发出可实时监测伤口愈合状态的高性能电子皮肤
美国能源部阿贡国家实验室研究人员正在开发深度学习框架MaLTESE
阿贡国家实验室研究人员开发出新型电解质混合物 有望应用于下一代锂离子电池
诺基亚贝尔实验室标准单模光纤创造新记录
研究人员开发出完全集成LED的硅芯片
低代码平台解决行业痛点 新享推出智慧实验室解决方案



评论