 赛灵思公司宣布,其SDAccel开发环境现已通过一致性测试
赛灵思公司宣布,其SDAccel开发环境现已通过一致性测试
All Programmable技术和器件的全球领先企业赛灵思公司 (NASDAQ: XLNX) 宣布,其面向OpenCL、C和C++ 的SDAccel 开发环境现已顺利通过 Khronos OpenCL 1.0标准一致性测试。
OpenCL标准为软件开发人员提供了一个统一的编程环境,使其能够编写高效且可移植的代码,从而能够在赛灵思FPGA上轻松加速各种算法。作为赛灵思SDx系列的最新成员,SDAccel包含一个面向OpenCL、C和C++语言的架构最优化编译器,且实践证明SDAccel相对于CPU或GPU将单位功耗性能提高达25倍,性能和资源利用率更是其他FPGA解决方案的3倍。
SDAccel开发环境结合了业界首款支持OpenCL、C和C++的架构最优化编译器与多种库、开发板,更为FPGA带来完全类似CPU/GPU的开发和运行时间体验。
Khronos 组织总裁兼OpenCL工作组主席Neil Trevett 表示:“看到赛灵思对于异构系统并行编程OpenCL标准的支持,我们非常兴奋。FPGA天然适用于计算密集型算法,在这类算法中,高吞吐量、低时延和低功耗是满足系统要求的关键。现在整个OpenCL设计群体都能够毫无障碍地获益于赛灵思FPGA所带来的优势。”
您可能不知道的一些SDAccel的事情:
中国最大的搜索引擎提供商百度现已转用深度神经网络(DNN)处理技术来解决语音识别、图像搜索以及自然语言处理中存在的各种问题。公司迅速决策到当在线预测使用神经反向传播算法时,FPGA 解决方案远比 CPU 和 GPU 更容易进行扩展。百度开发的 400Gflop 软件定义加速器,其所用的赛灵思 Kintex-7 480t-2l PCI Express FPGA开发板可以插入到任何类型的 1U 或 2U 服务器中。在不同工作负载下,百度发现Kintex 7 FPGA 开发板的性能均比 GPU 高出 4 倍,比 CPU 则高出 9 倍,同时在实际生产系统中功耗仅为 10-20W。百度指出应用 FPGA 解决方案的一大壁垒就是开发时间长,百度建议利用 Xilinx SDAccel 环境提供的相应软件工具来解决这个问题。
板级超级计算机专家Convey Computer将 x86 CPU 与赛灵思 FPGA 完美结合,设计了一款可帮助数据中心服务器进行内容高速缓存的 Wolverine 加速卡。Convey 与戴尔的数据中心解决方案(DCS)业务部通力合作推出了一款图像缩放解决方案(在社交媒体和图片存储网络中非常需要)。该解决方案采用两个 Virtex7 开发板,相对仅采用 CPU 的同等系统而言,缩放速度可提高 35 到 40 倍。此外,Convey-Dell 解决方案之所以得到广泛使用,关键还是能够利用更高级的语言定制 FPGA 加速器。
大型数据中心需要令人信服的 FPGA 实用功能,微软的案例就是一个有力的证明。在2014 年年初,微软启动了一项计划 —使用 FPGA 加速 Bing 搜索排名。微软公司服务器工程副总裁 Kushadra Vaid 最近在 Linley 处理器大会上的一次主题演讲中展示了使用 1632 台带 PCIe FPGA 加速卡的服务器试生产结果。相对于未加速的服务器,微软实现方案的吞吐量提高了 2 倍,而时延和成本分别降低了 29% 和 30%。尽管 Vaid 展示了 ASIC 可以提供极高的效率,但他表示他们根本无法赶上快速变化的需求。一直阻碍 FPGA 在这些数据中心应用中更广泛使用的原因就是缺乏一款高效优化的编译器和相关开发环境,以满足数十年在面向通用 CPU 和 GPU 架构的编译器上工作的需求。
赛灵思从事特定领域规范环境的开发工作将近十年了。数据中心管理人员和服务器/交换机 OEM 厂商对数据中心性能的关注有助于推动向统一环境纵深发展,从而在数据中心应用中实现设计优化。因此,用于加速的软件定义开发环境 SDAccel 应运而生。
这款编译器不仅可完成用户在任何本地 OpenCL 编译器上所能实现的基本功能,如循环合并、扁平化以及展开等,而且还能执行一些更高级的优化工作,如内存使用、数据流、循环流水线等选项。这些优化让客户依赖编译器将 C、C++ 或 OpenCL 直接高效导入到 FPGA 硬件中。
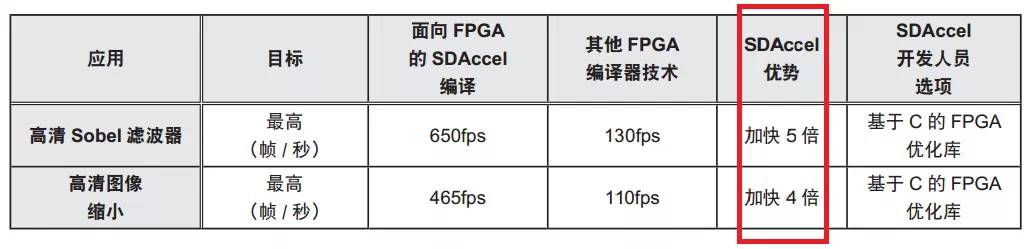

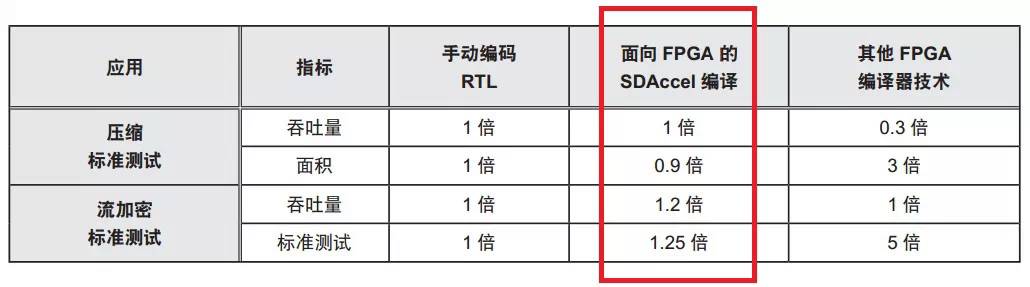
-
赛灵思
+关注
关注
32文章
1794浏览量
131130 -
开发环境
+关注
关注
1文章
219浏览量
16570
发布评论请先 登录
相关推荐
LTE基站一致性测试的类别
泰克为SAS一致性测试推出全自动测试支持
安捷伦LTE终端一致性测试解决方案通过TPAC标准
泰克推出DisplayPort一致性测试的全自动化解决方案
世界第一:安立公司的RF/RRM一致性测试系统和协议一致性测试系统
Xilinx面向多种语言的SDAccel开发环境通过Khronos一致性测试
Imagination PowerVR GPU 通过 Khronos 的 OpenVX 一致性测试
Imagination PowerVR GPU 率先通过 Khronos 的 OpenVX 1.1一致性测试
Xilinx与IBM通过SuperVesselOpenPOWER开发云平台实现FPGA加速
EMI一致性测试调试方法





 工商网监
工商网监
评论